import pandas as pd, numpy as np
from sklearn import datasets
from sklearn.decomposition import PCA
from matplotlib import pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score
from sklearn.model_selection import train_test_split
import lime, lime.lime_tabular, shapWelcome back to the Visualization for Machine Learning Lab!
Week 6: Interpreting Black Box Models with LIME AND SHAP (and PCA if time)
LIME
- How does LIME work?
- For an in depth explanation of the math, see Sharma (2020)
- Fidelity-Interpretability Tradoff
- We want an explainer that is faithful (replicates our model’s behavior locally) and interpretable. To achieve this, LIME minimizes
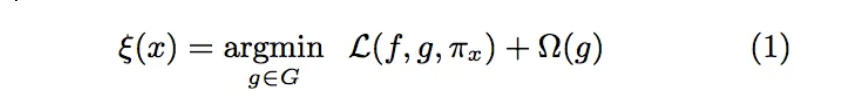
LIME
f: an original predictor
x: original features
g: explanation model which could be a linear model, decision tree, or falling rule lists
Pi: proximity measure between an instance of z to x to define locality around x. It weighs z’ (perturbed instances) depending upon their distance from x.
First Term: the measure of the unfaithfulness of g in approximating f in the locality defined by Pi. This is termed as locality-aware loss in the original paper
Last term: a measure of model complexity of explanation g (e.g. if your explanation model is a decision tree it can be the depth of the tree)
SHAP Example
We can use feature importance to understand how important each feature is to model predictions in general, but it cannot tell us
1. Feature affect on individual predictions
2. If a feature tends to increase or decrease the prediction
3. (For classification) if a feature changes the probability of a positive prediction
SHAP Example (Waterfall Plot)
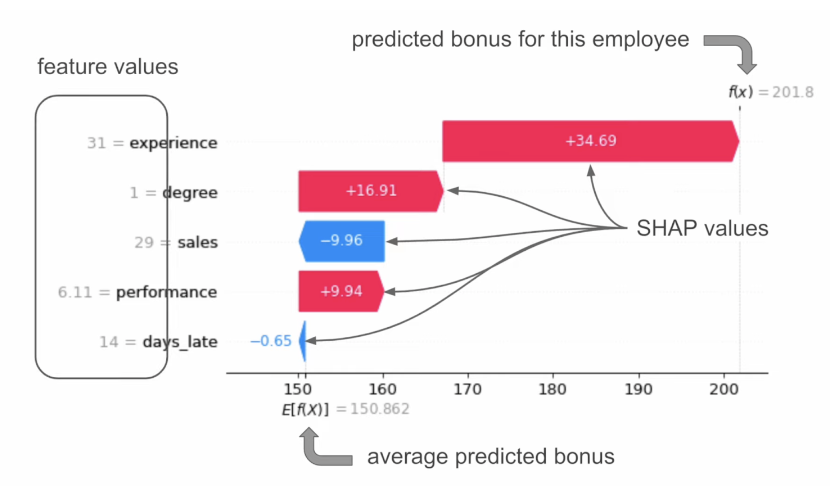
- “When an employee has a degree, the predicted bonus is $16.91 higher than the average.” = “Degree has increased the prediction”
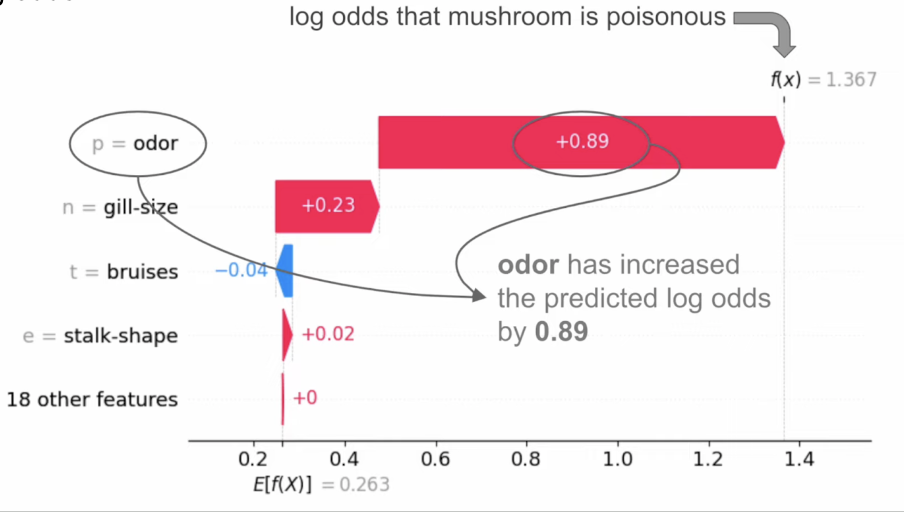
SHAP Example (Classification)
- Suppose we have a classification model that predicts whether mushrooms are poisonous (class 1) or edible (class 0)
- Use log odds (the logarithm of the odds ratio - odds are likelihood ratios, and tell us how likely it is that an event will happen)
Other SHAP Plots (for model as a whole)
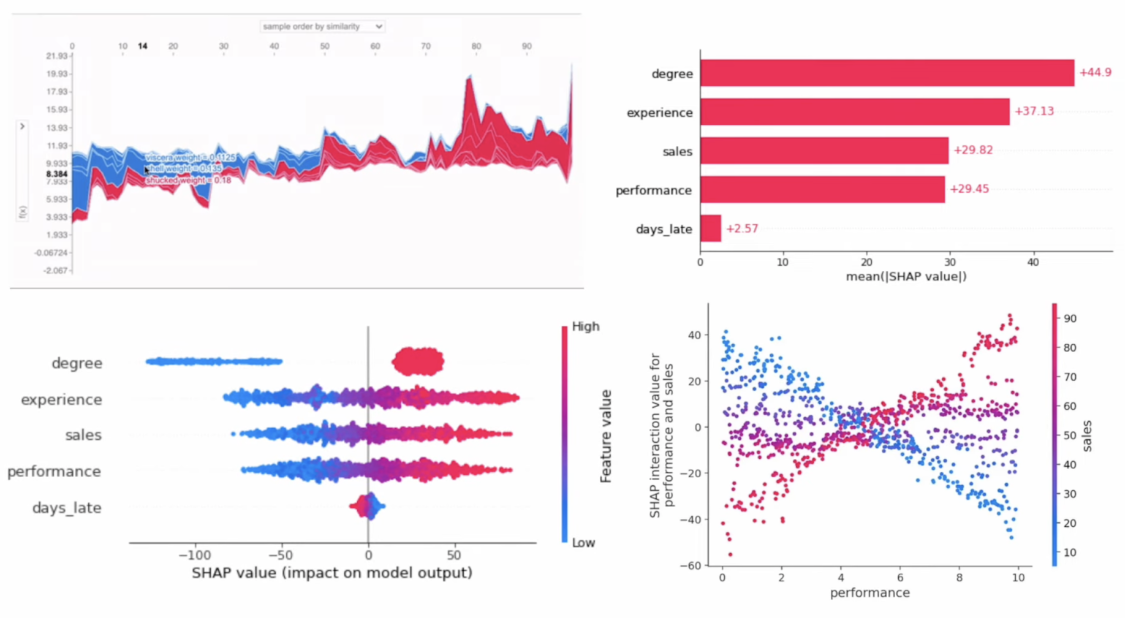
SHAP Examples in Python
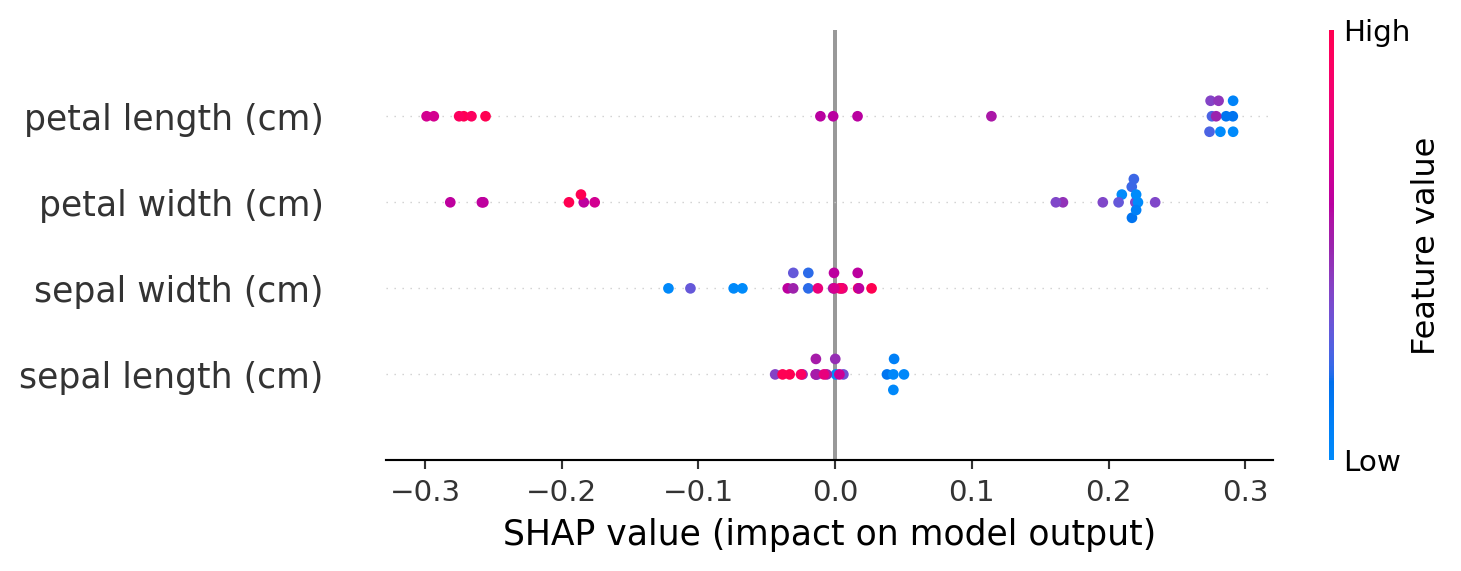
- We can visualize these SHAP values as a beeswarm plot:
- Each dot is a row of the dataset
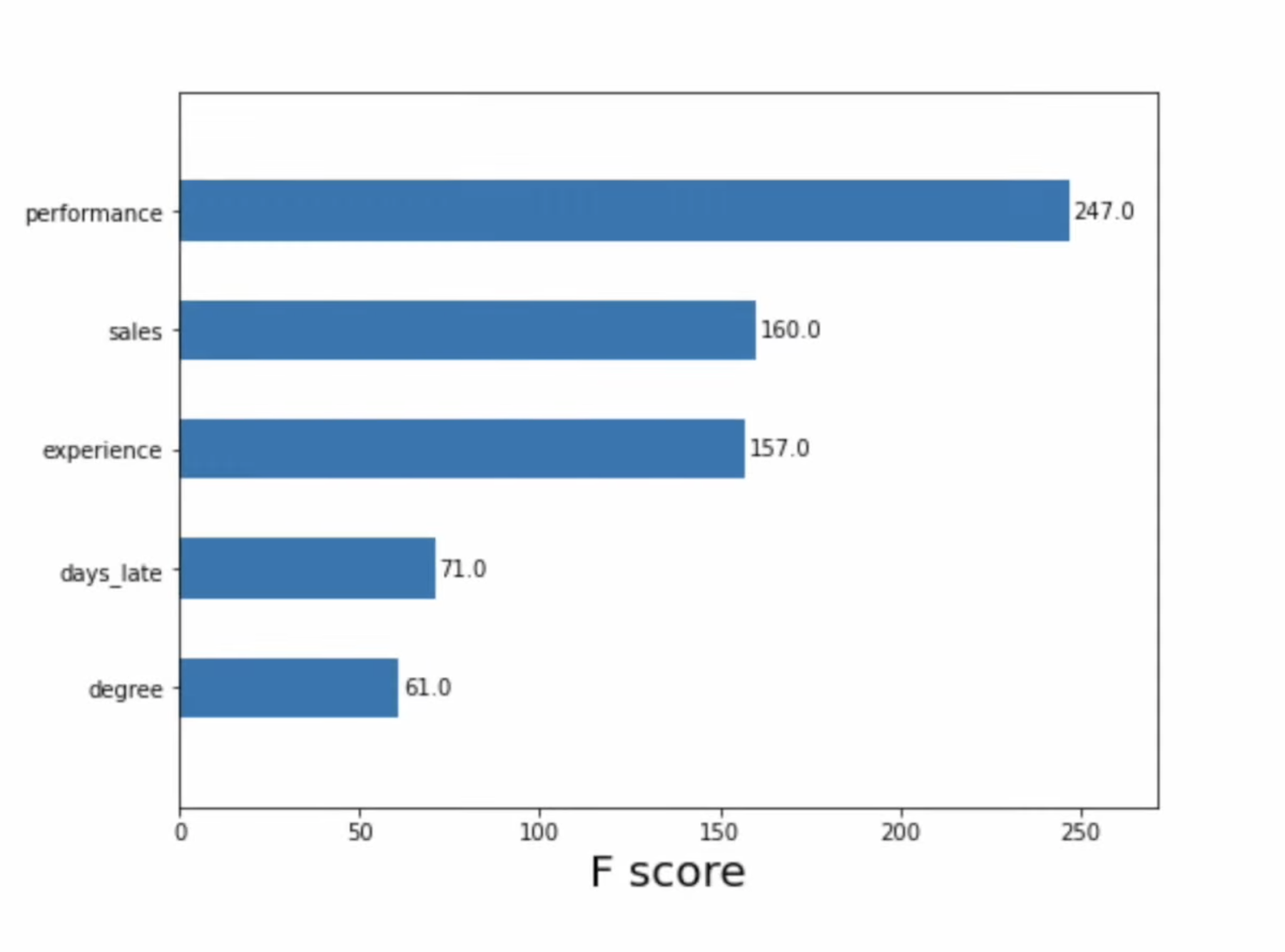
- Features (y-axis) are ranked from top to bottom by their mean absolute SHAP values for the entire dataset
- X-axis position corresponds to each dot's SHAP value
- Color corresponds to the raw feature value
SHAP Examples in Python
- Dependence plots show the relationship between SHAP and raw values for a specific feature
- Vertical dispersion in SHAP values seen for fixed variable values is due to interaction effects with other features
- Dependence plots are often coloured by the values of a strongly interacting feature (in this case, sepal width)
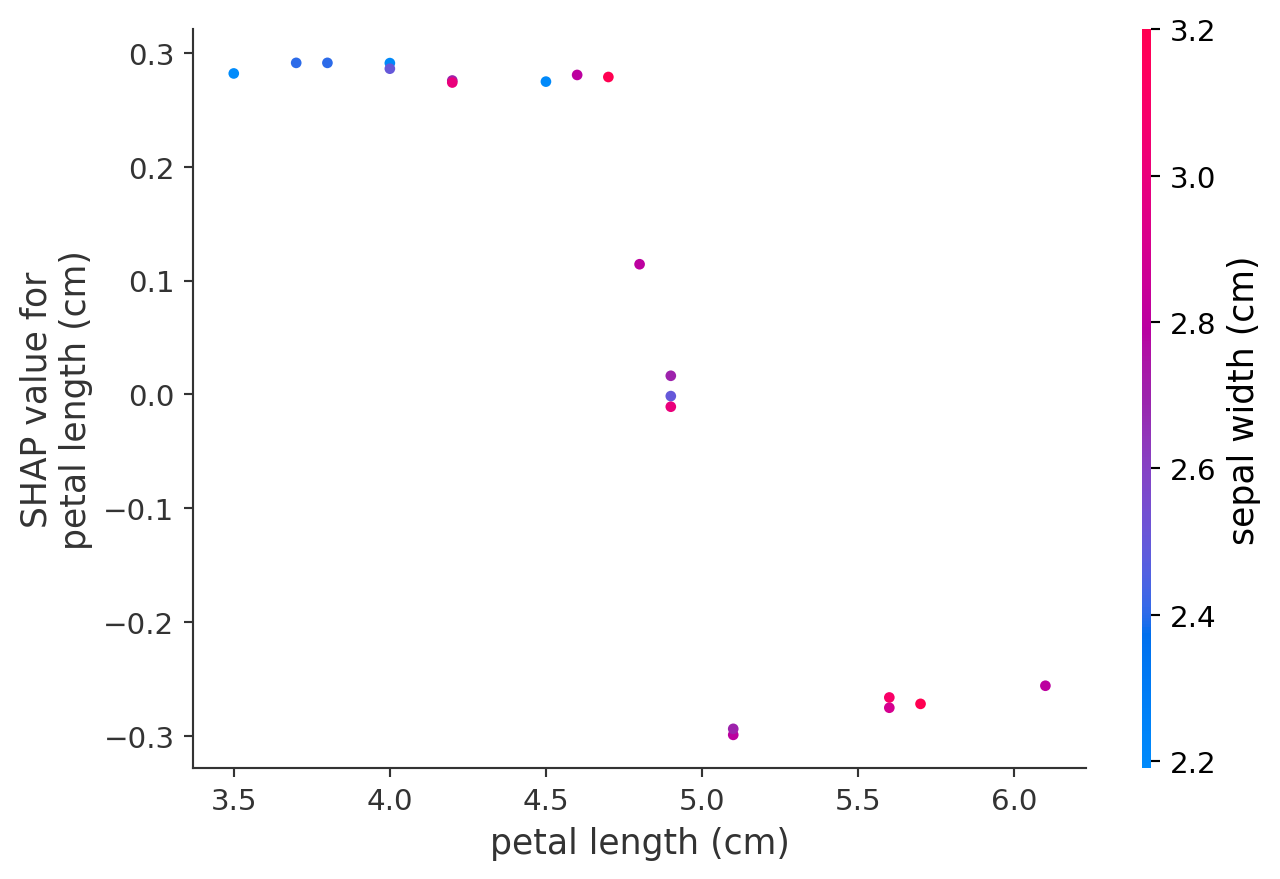
SHAP Examples in Python
Finally, force plots can be thought of as a condensed waterfall plot:
shap.initjs()
sample_idx = 10
shap.force_plot(explainer2.expected_value[class_idx], shap_values[class_idx][sample_idx], X_test.values[sample_idx])
Visualization omitted, Javascript library not loaded!
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.

SHAP Examples in Python
shap.initjs()
class_idx = 1
shap.force_plot(explainer2.expected_value[class_idx], shap_values[class_idx][sample_idx], X_test.values[sample_idx])
Visualization omitted, Javascript library not loaded!
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
Principal Component Analysis (PCA)
- Dimensionality reduction technique that allows us to find clusters of similar data points based on many features (which we boil down to two “principal components” PC1 and PC2)
- PC1 and PC2 represent the directions in the data space with the highest and second-highest variances, respectively
- Way to bring out strong patterns from large and complex datasets
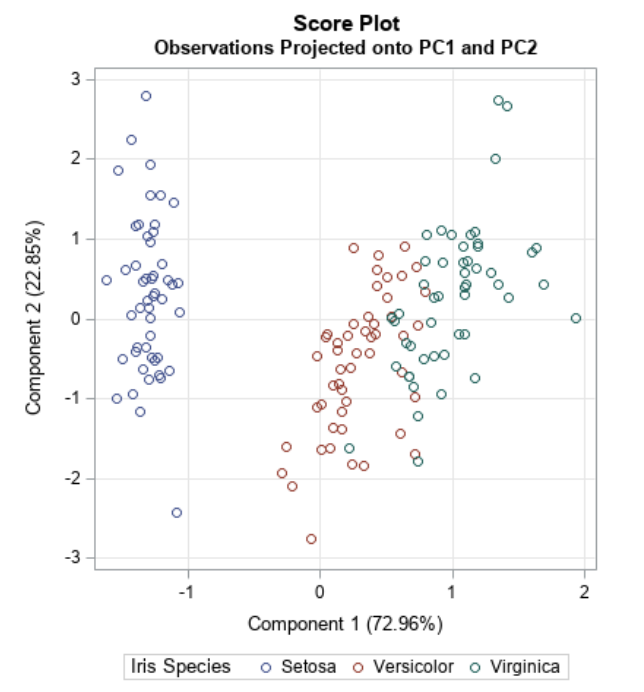
PCA Example
- Suppose we have a dataset that measures the expression of 15 genes from 60 mice
- How do you know which mice are similar to one another, and which ones are different?
- How do you know which genes are responsible for such similarities or differences?
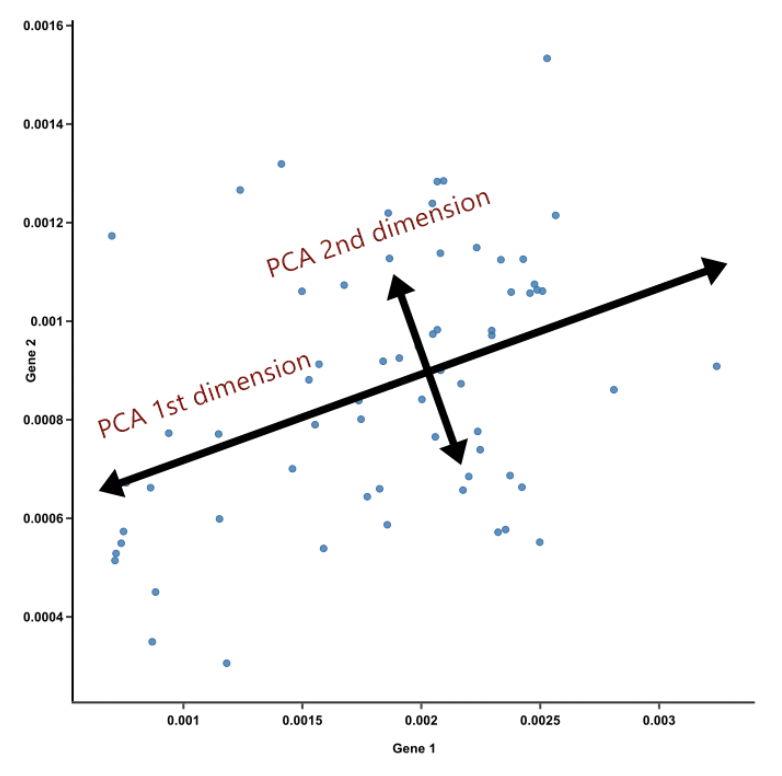
- Let’s start by plotting the data for two genes against each other:
- Each dot = 1 mouse
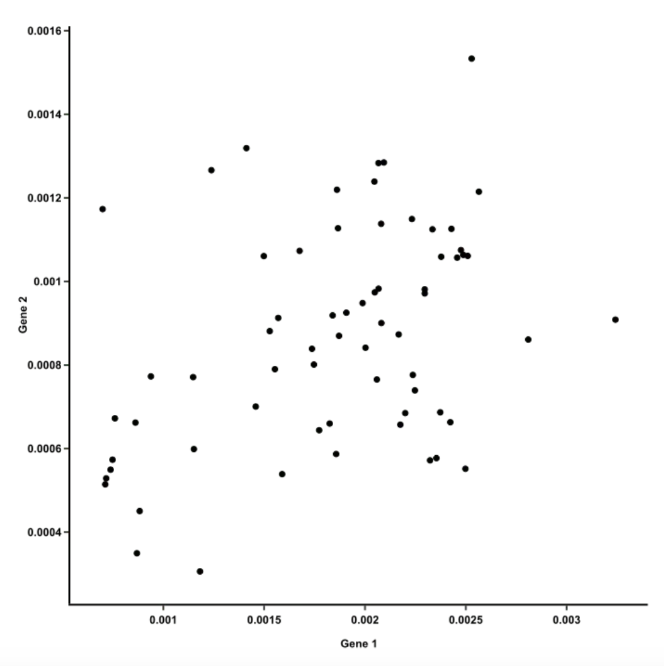
PCA Example
- The first principal component is the line of best fit for this data. It is a line that, if you project the original dots on it, two things happen:
- The total distance among the projected points is maximized. This means they can be distinguished from one another as clearly as possible.
- The total distance from the original points to their corresponding projected points is minimized. This means we have a representation that is as close to the original data as possible.
- AKA PC1 must convey the maximum variation among data points AND contain minimum error (these are actually achieved at the same time)
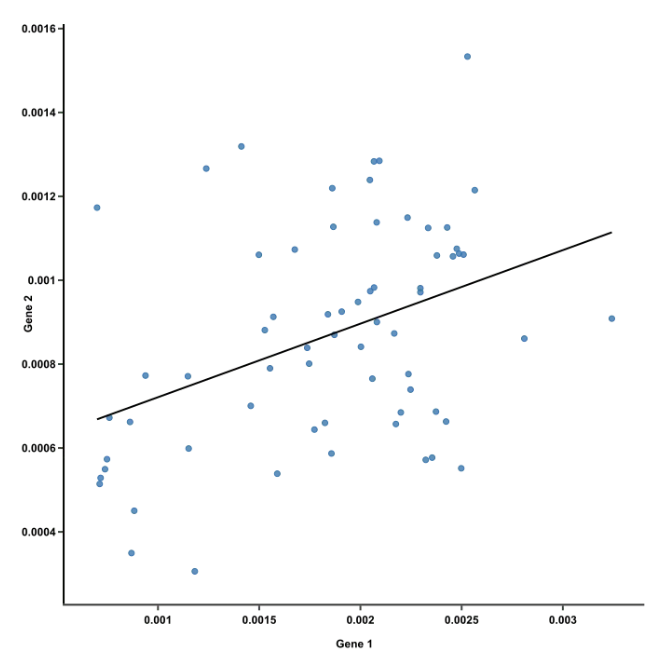
PCA Example
- PC2 is the second line that meets PC1, perpendicularly, at the center of the cloud, and describes the second most variation in the data