Visualization for Machine Learning
Spring 2024
Clustering
Etienne Bernard: “… the goal of clustering is to separate a set of examples into groups called clusters”
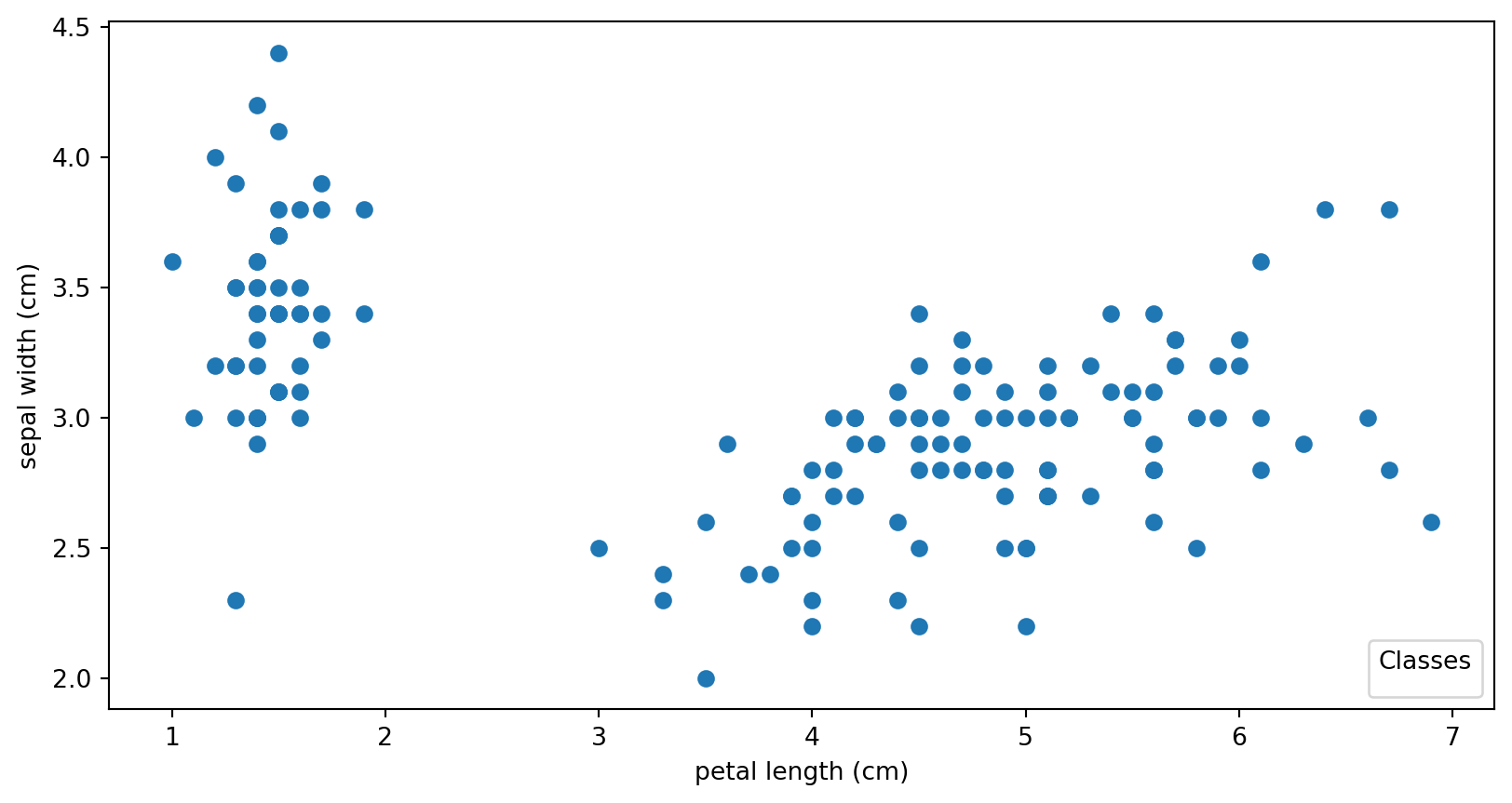
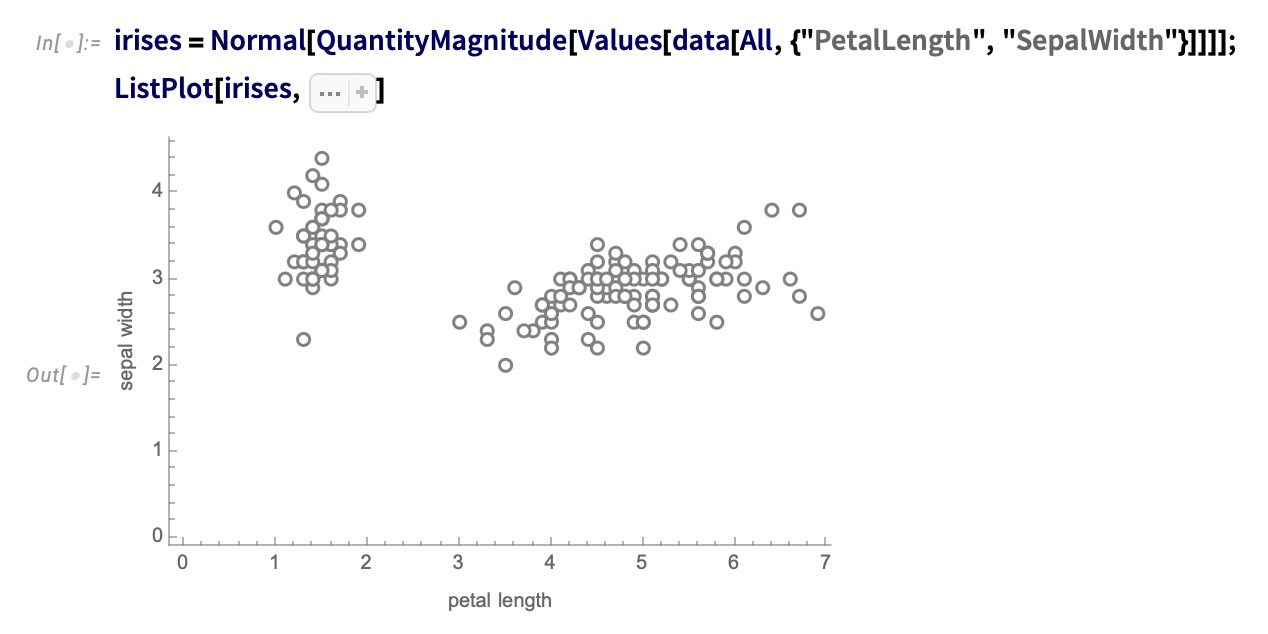
IRIS – another look (Bernard)
IRIS – clustering
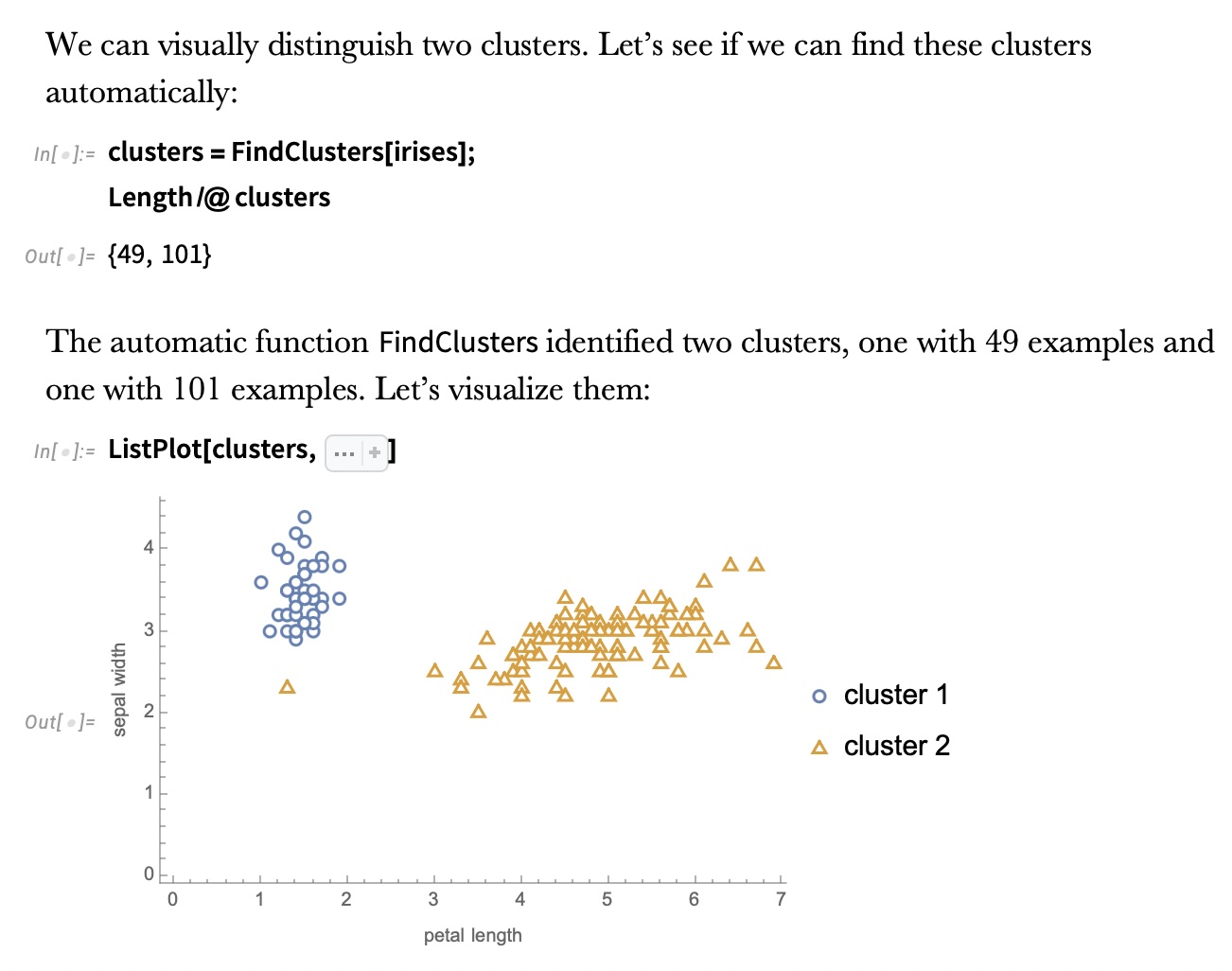
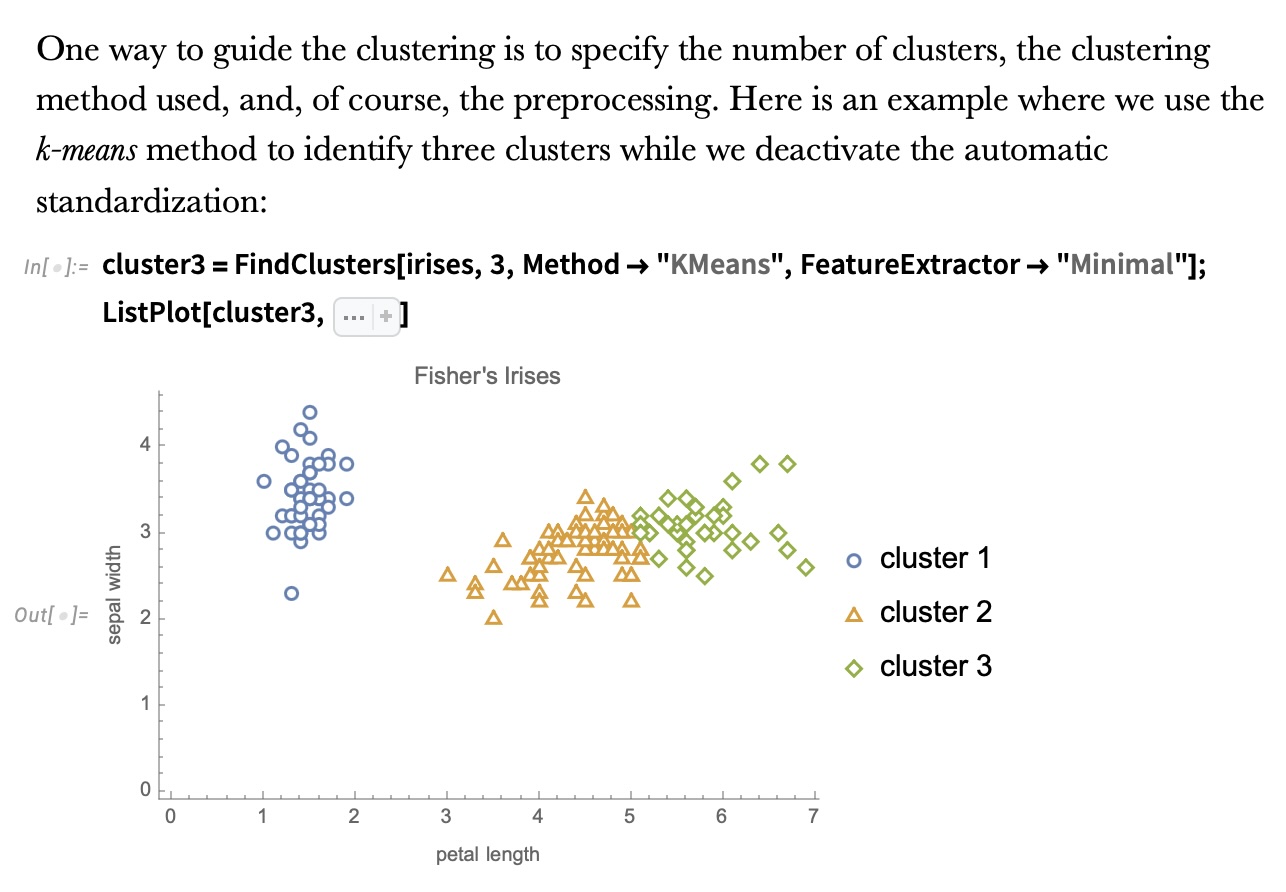
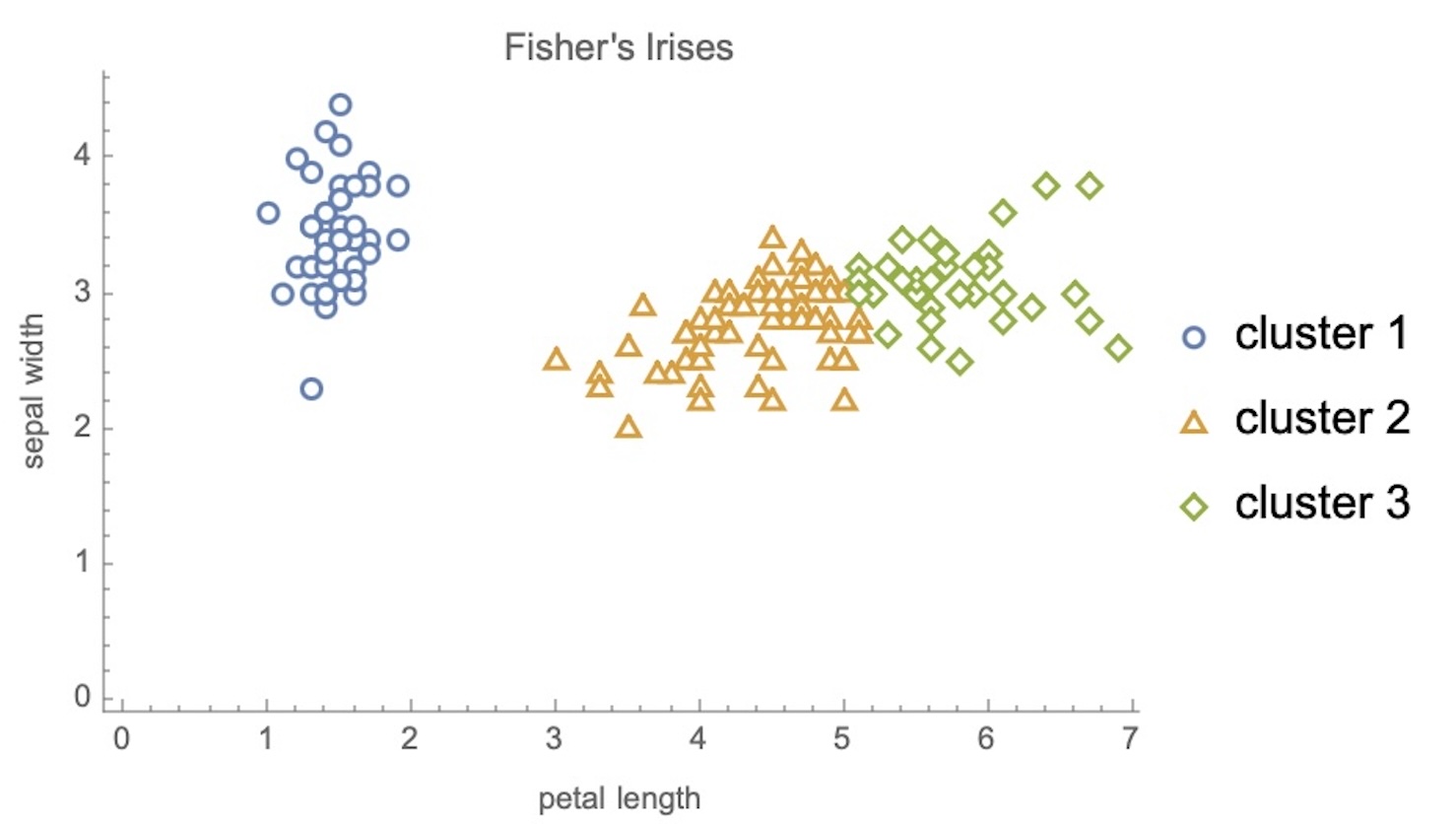
IRIS – k-means
Wolfram Mathematica FindClusters
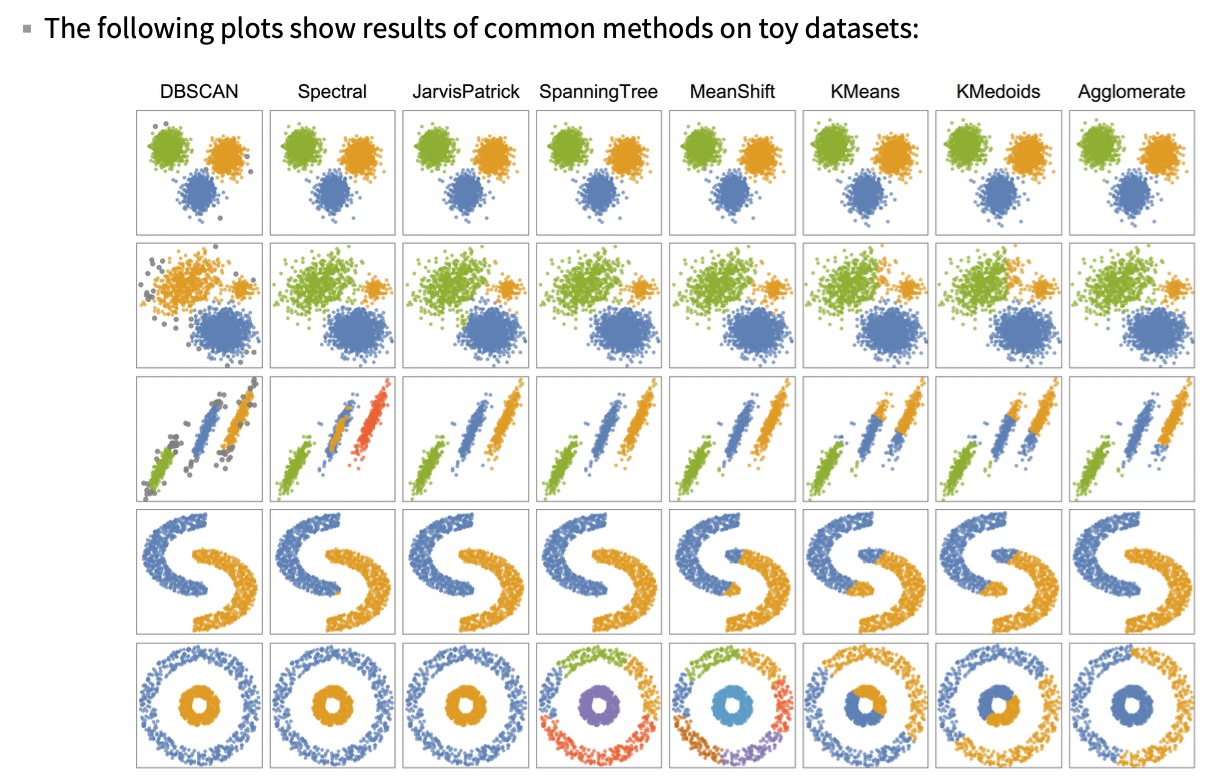
Wolfram Mathematica FindClusters
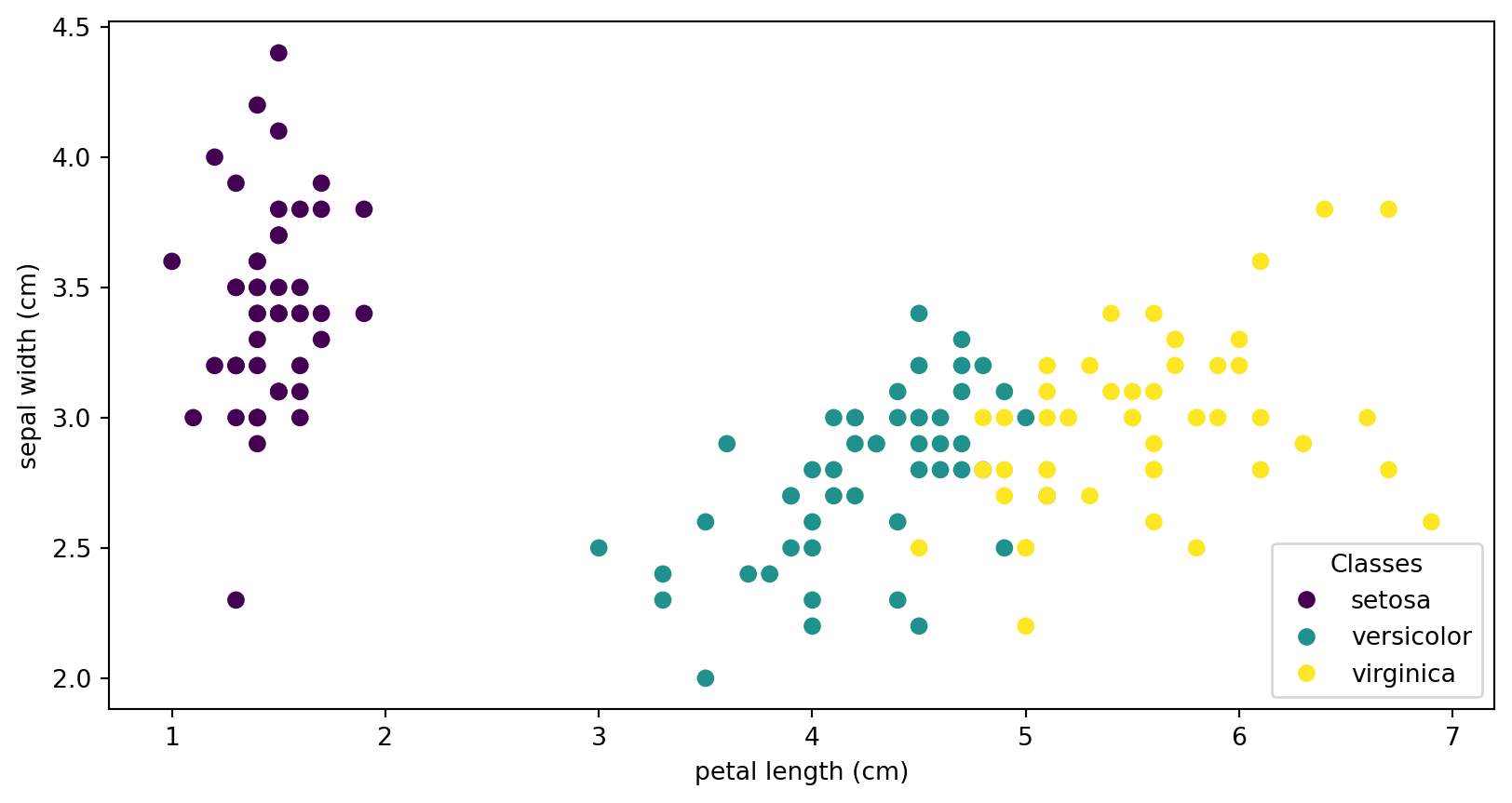
IRIS - classes
Dimensionality Reduction (Yi Zhang)
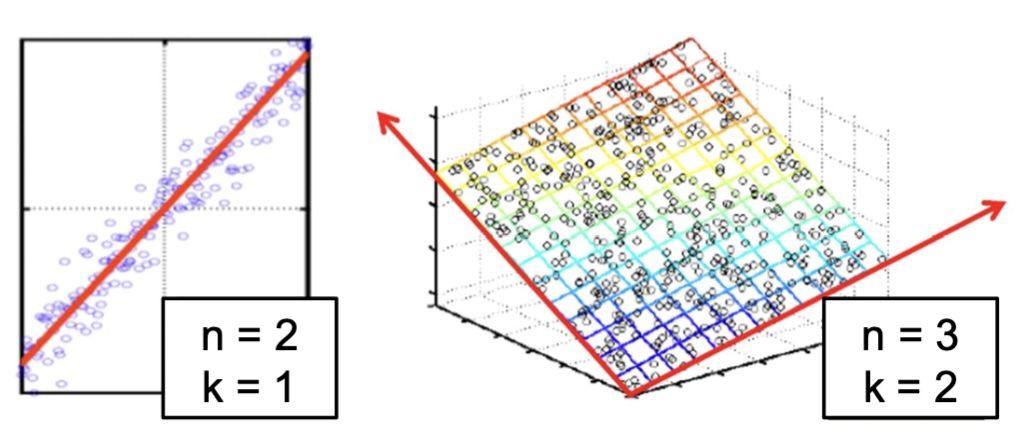
- Assumption: data lies on a lower dimensional space
Dimensionality Reduction (Bishop)
- Supposed a dataset of “3s” perturbed in various ways

What operations did we perform? What’s the intrinsic dimensionality?
Here the underlying manifold is non-linear
Digits

Digits
Computing Random projection embedding...
Computing Truncated SVD embedding...
Computing Linear Discriminant Analysis embedding...
Computing Isomap embedding...
Computing Standard LLE embedding...
Computing Modified LLE embedding...
Computing Hessian LLE embedding...
Computing LTSA LLE embedding...
Computing MDS embedding...
Computing Random Trees embedding...
Computing Spectral embedding...
Computing t-SNE embedding...
Computing NCA embedding...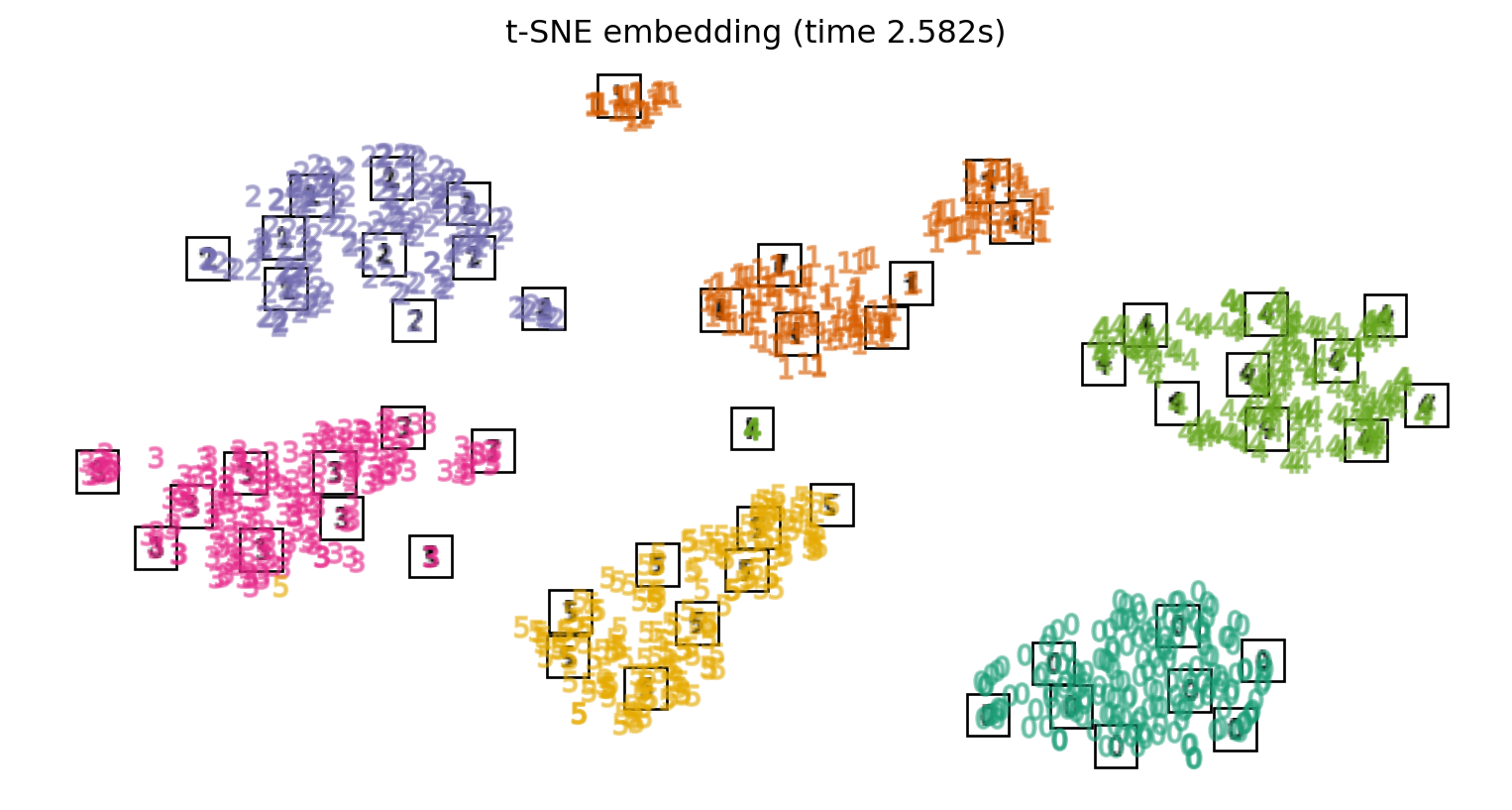
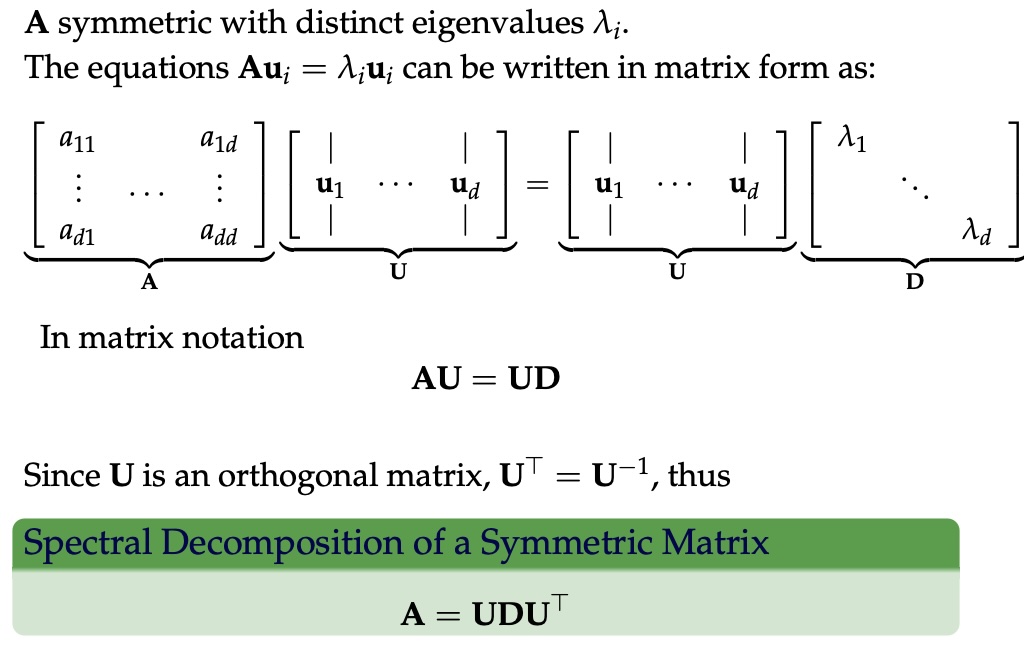
Symmetric Matrices
- \(\lambda \in \mathbb{R}\) and \(u \in \mathbb{R}^d\) (no complex numbers involved)
- The eigenvectors are orthogonal
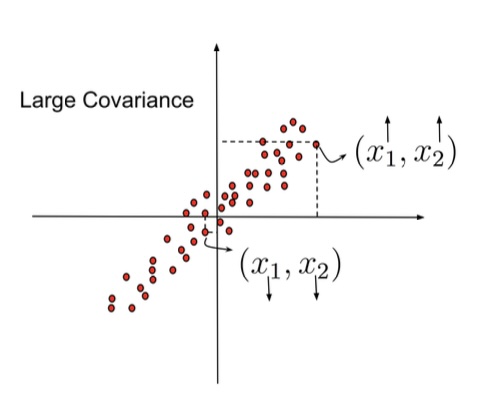
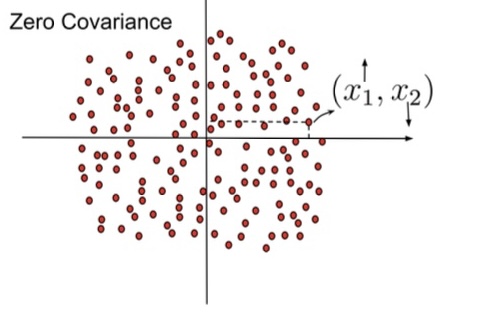
Covariance Matrix

Covariance Matrix
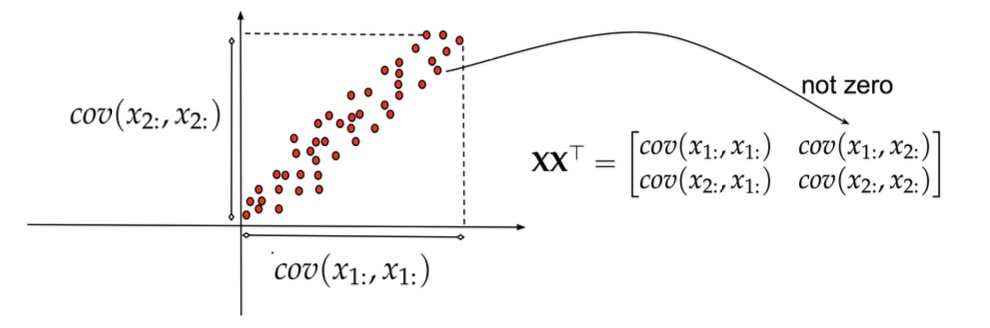
Covariance Matrix

Principal Component Analysis: intuition
Principal Component Analysis: intuition
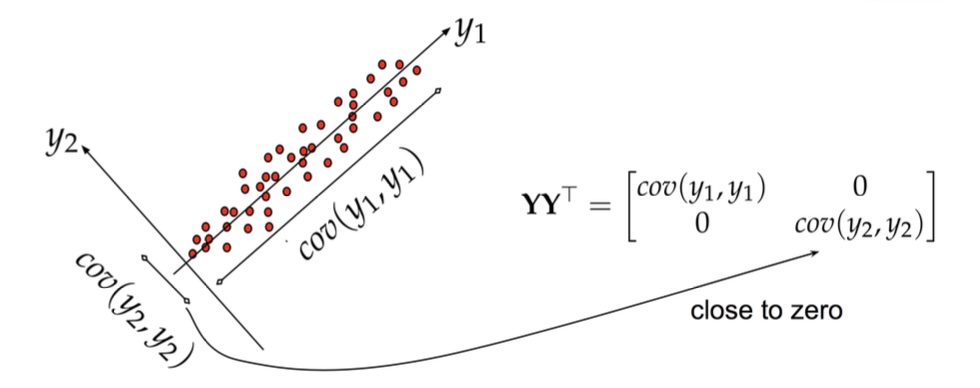
Principal Component Analysis

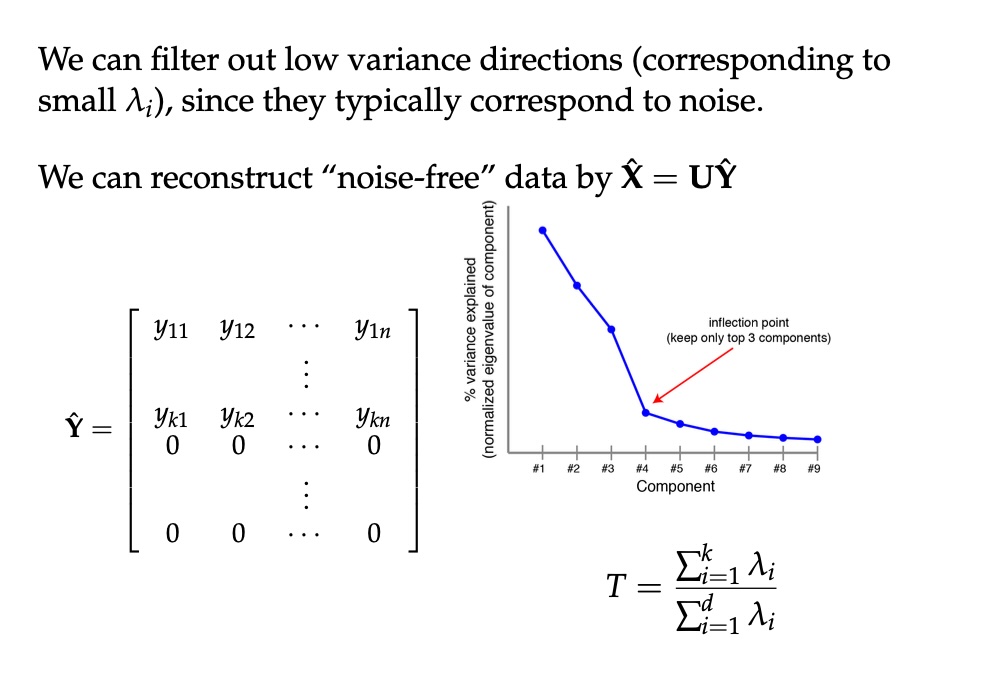
Principal Component Analysis
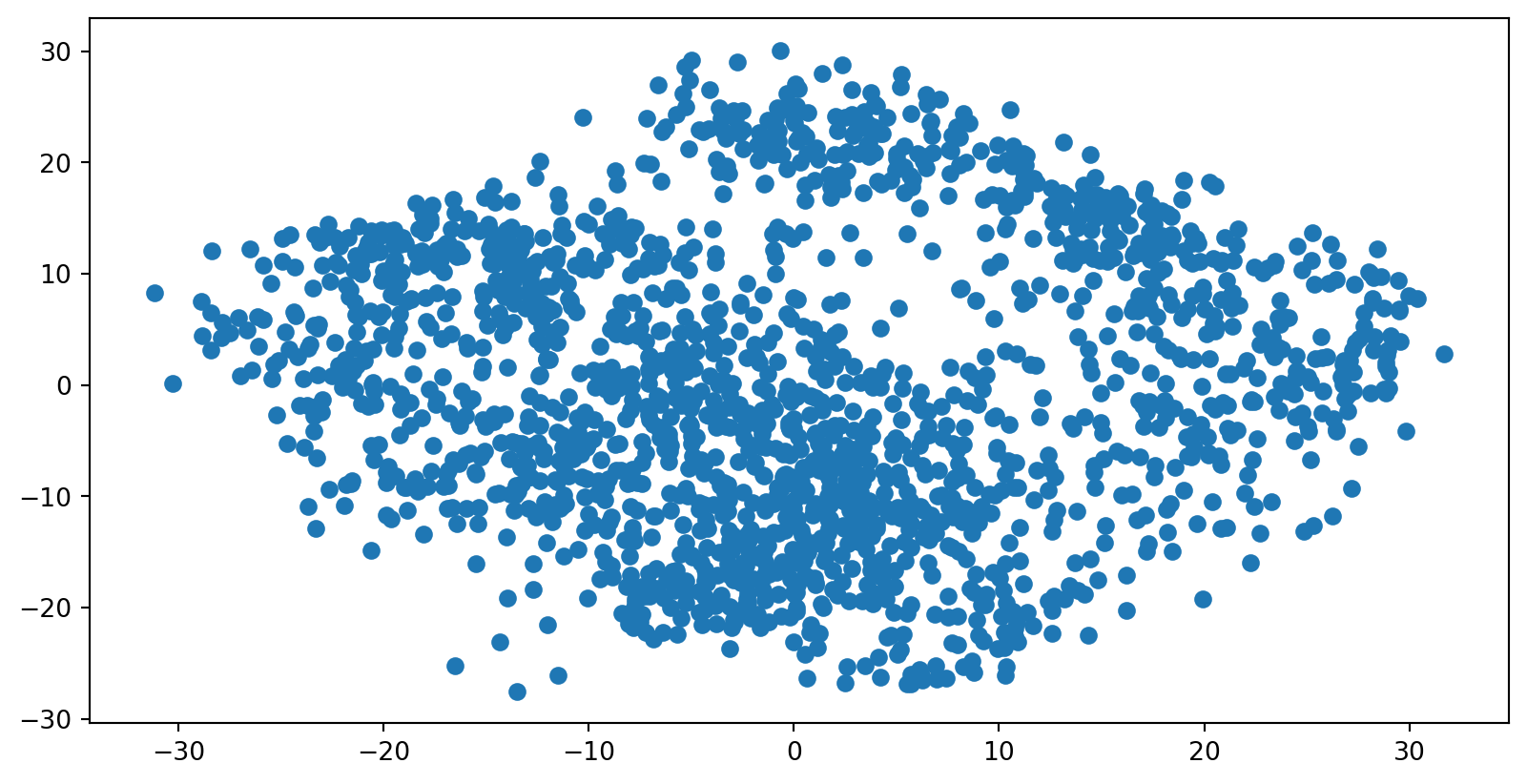
PCA of digits
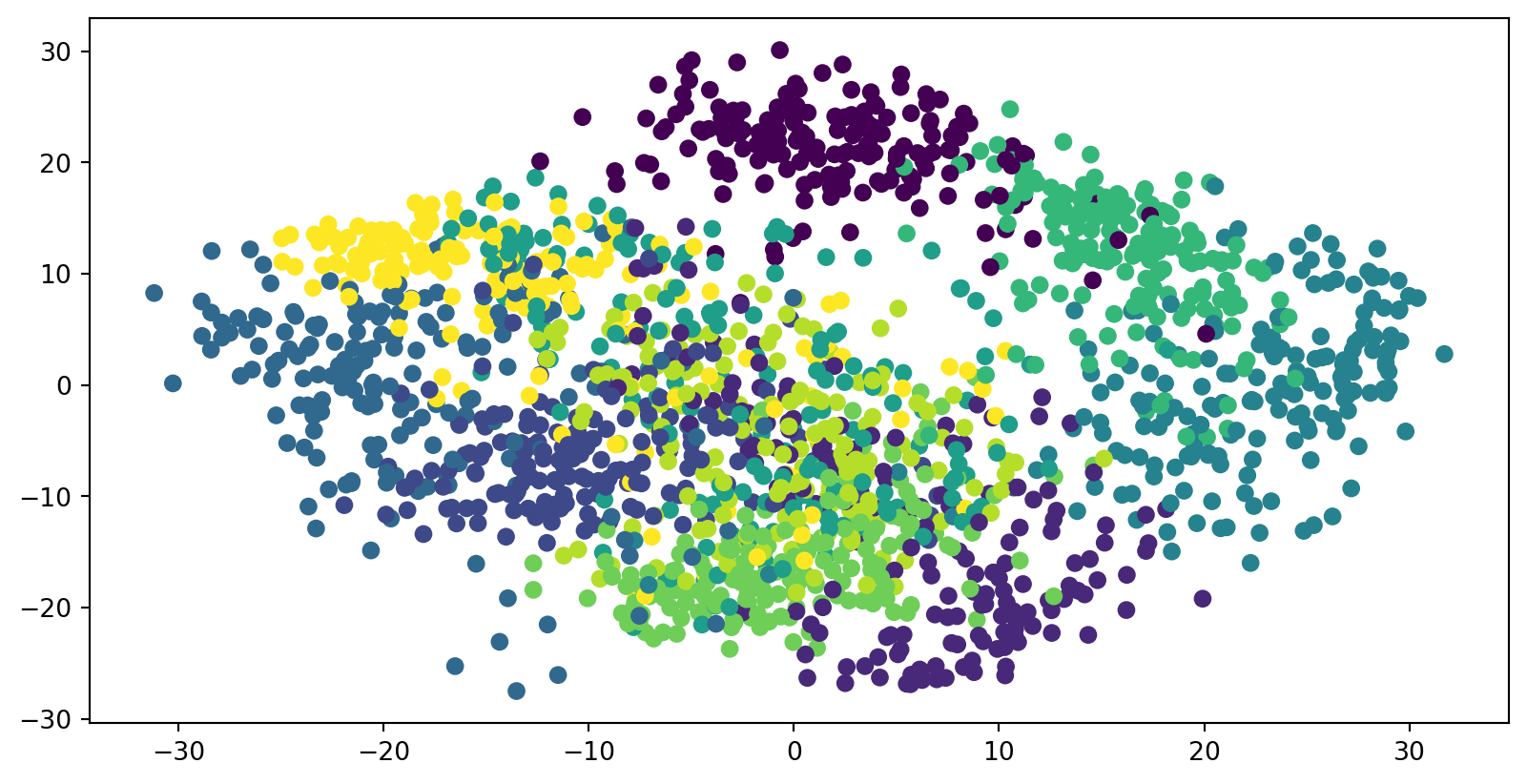
PCA of digits
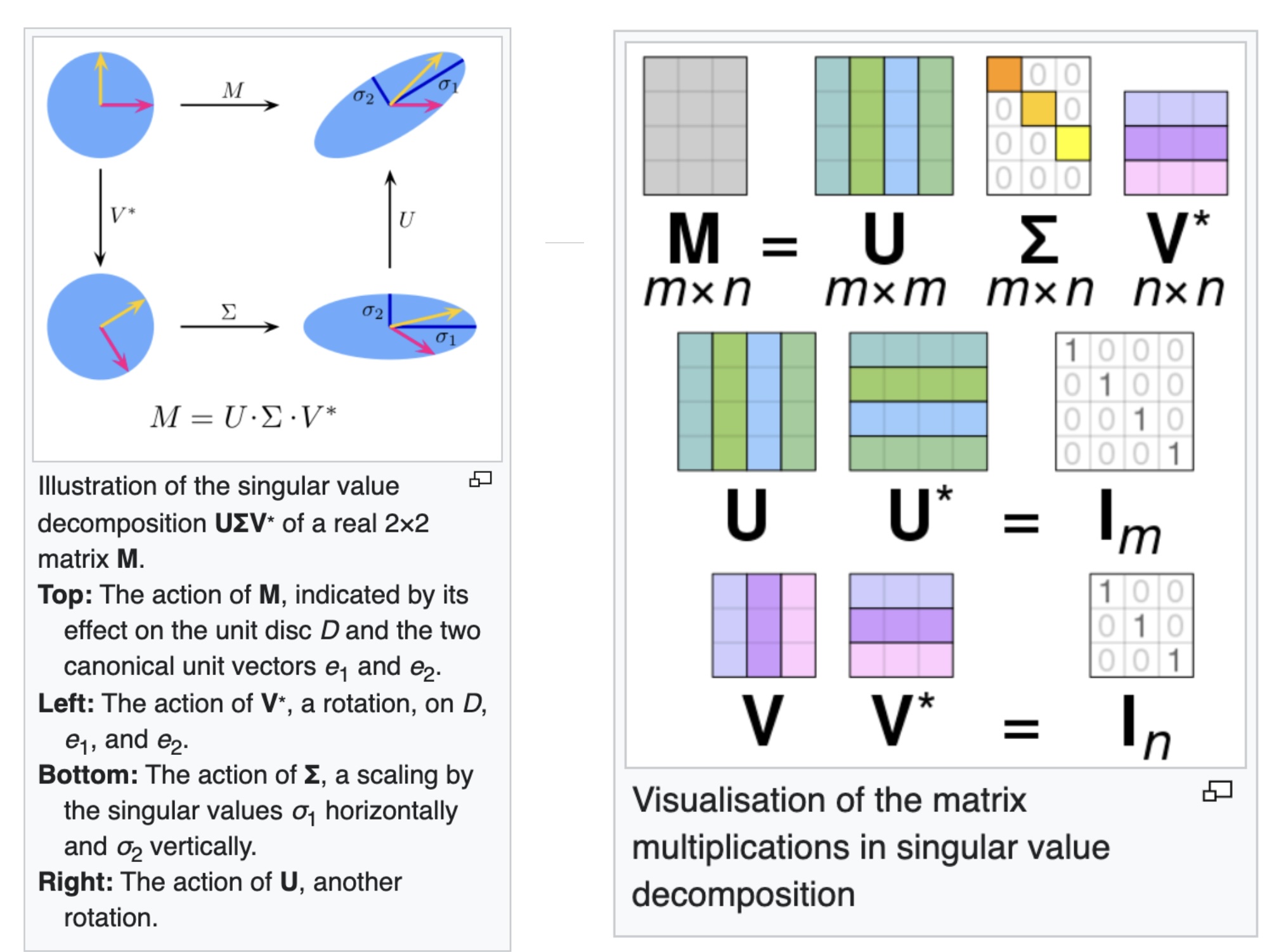
Singular Value Decomposition (SVD)
- https://en.wikipedia.org/wiki/Singular_value_decomposition
Local Linear Embedding
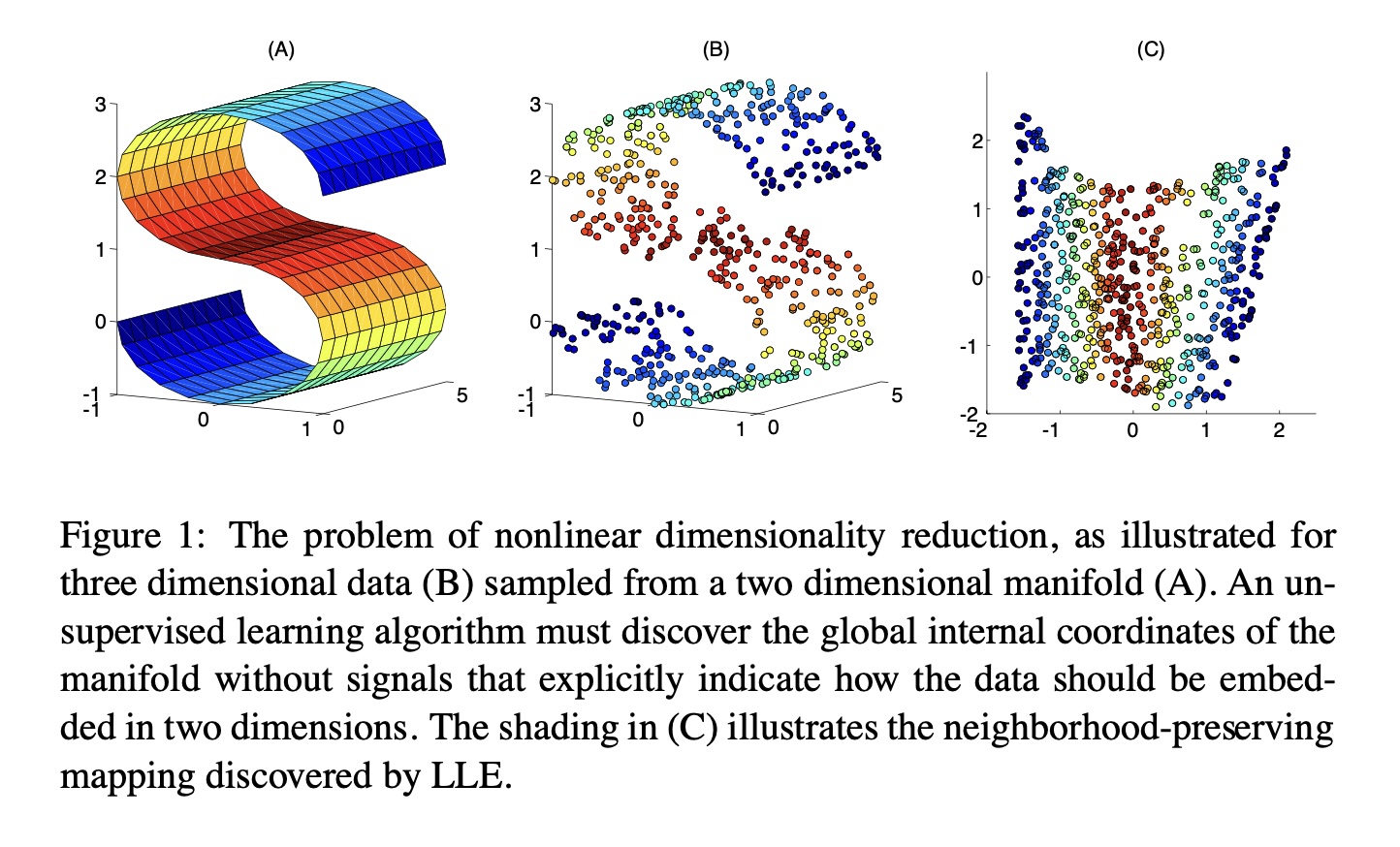
Preserving Local Manifold Neighborhoods
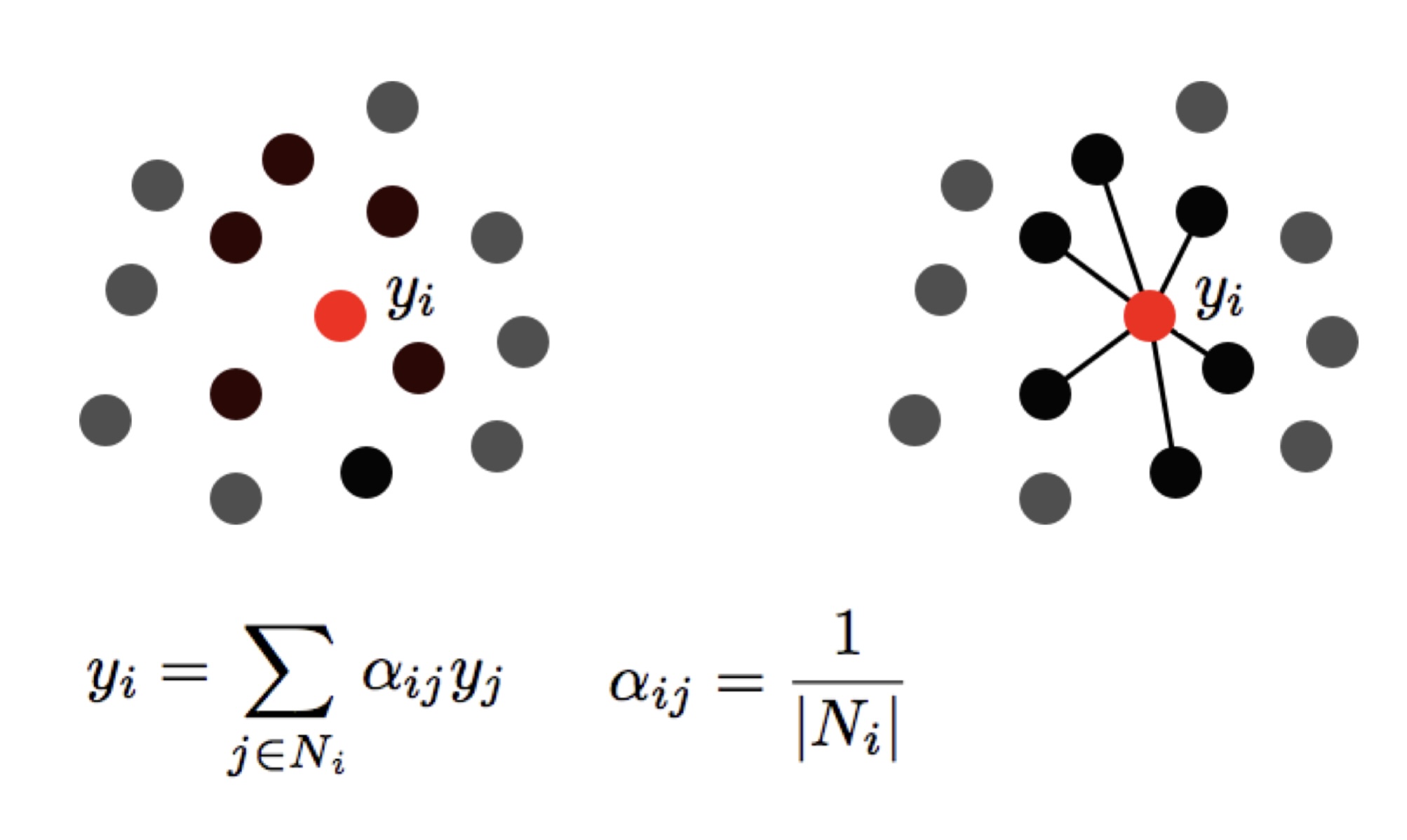
LLE

https://www.science.org/doi/10.1126/science.290.5500.2323
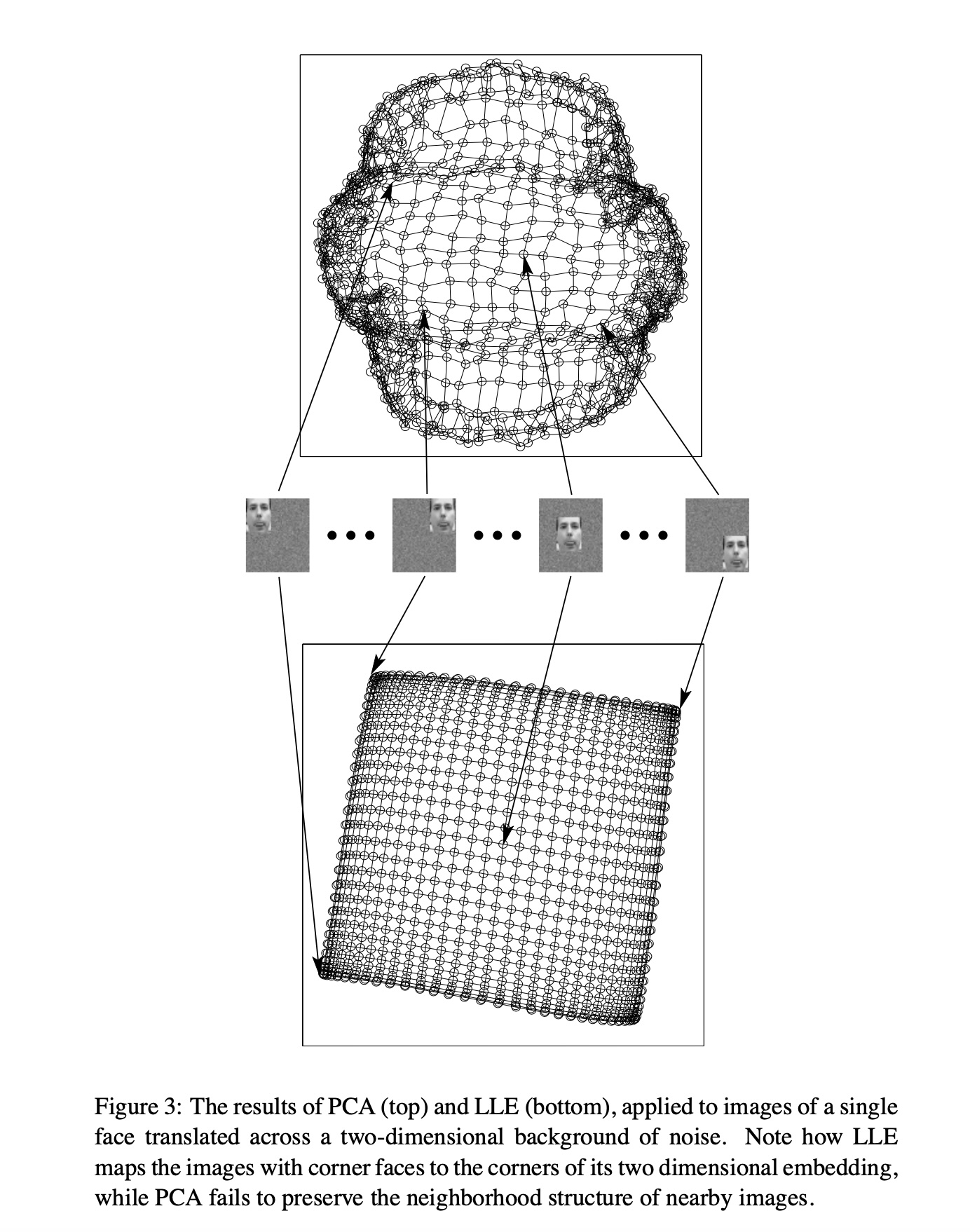
PCA vs LLE
SNE and t-SNE


HERE is an excellent talk by t-SNE creator: video link
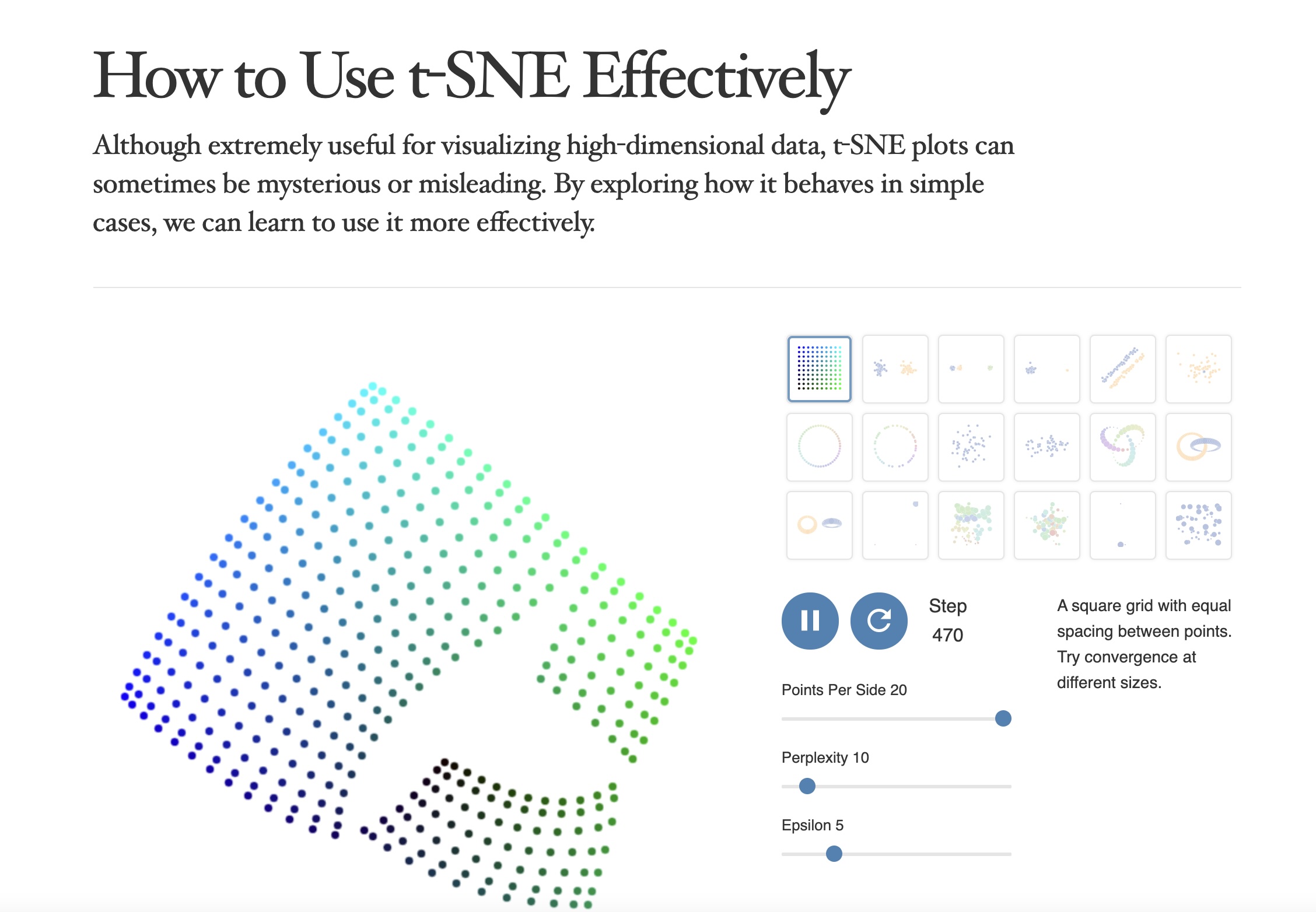
https://distill.pub/2016/misread-tsne/

https://pair-code.github.io/understanding-umap/
What about user interaction?