Visualization for Machine Learning
Spring 2024
Deep Learning
Understanding Deep Learning by Simon J.D. Prince. Published by MIT Press, 2023.
https://udlbook.github.io/udlbook

1-D linear regression model
- \(y = f[x, \Phi] = \Phi_0 + \Phi_1 x\)
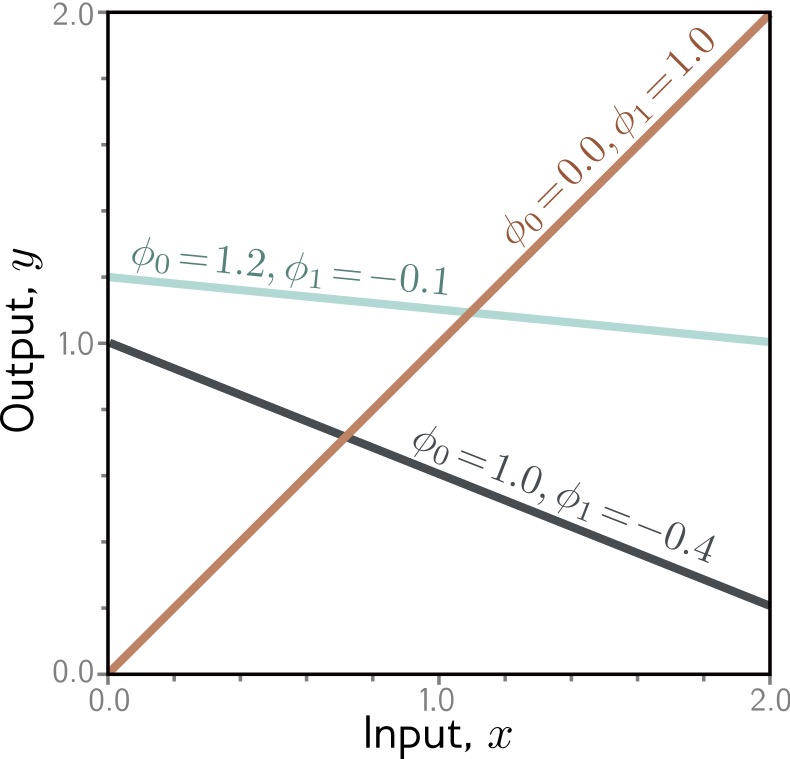
1-D linear regression model: Loss
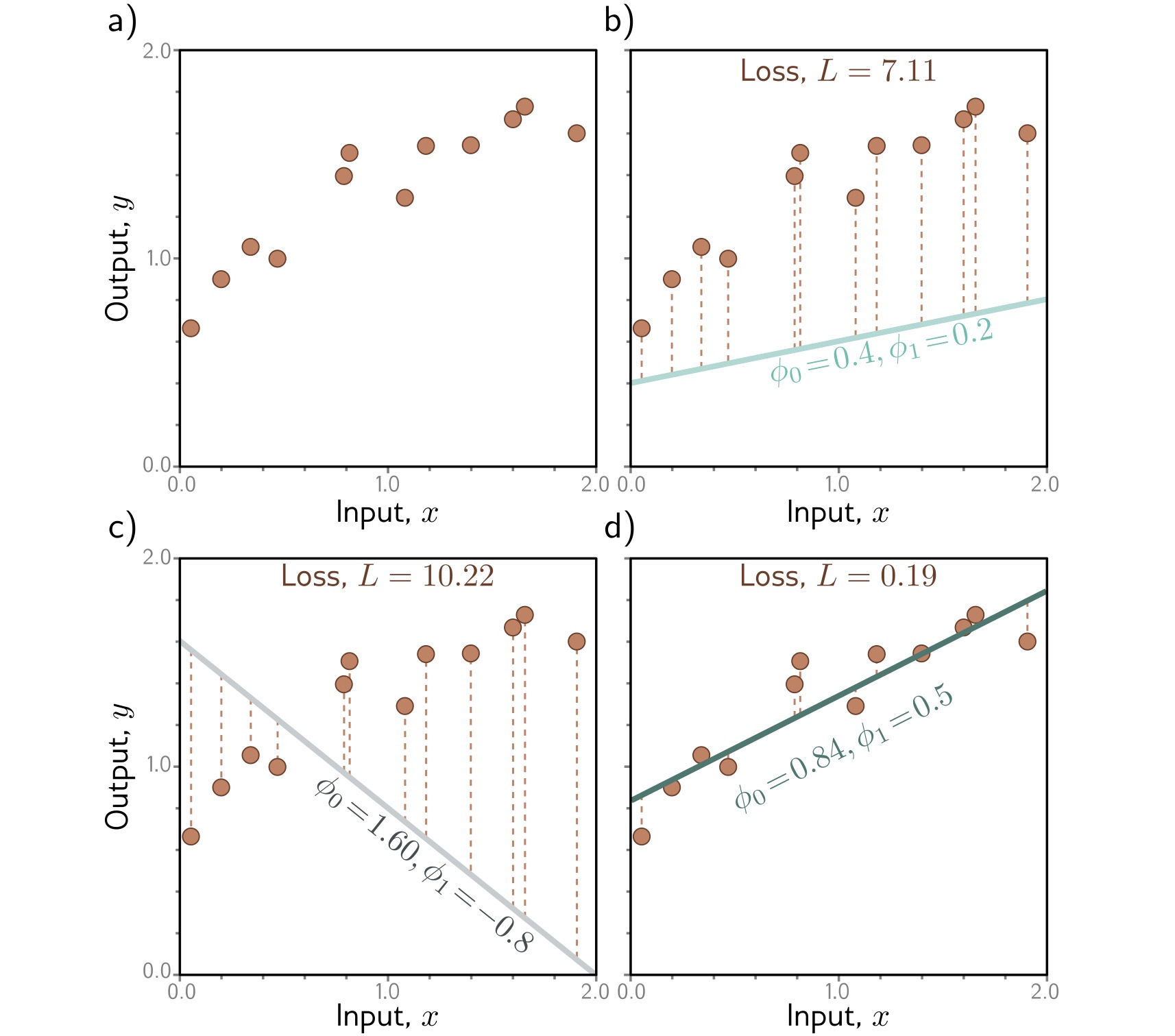
1-D linear regression model: Loss
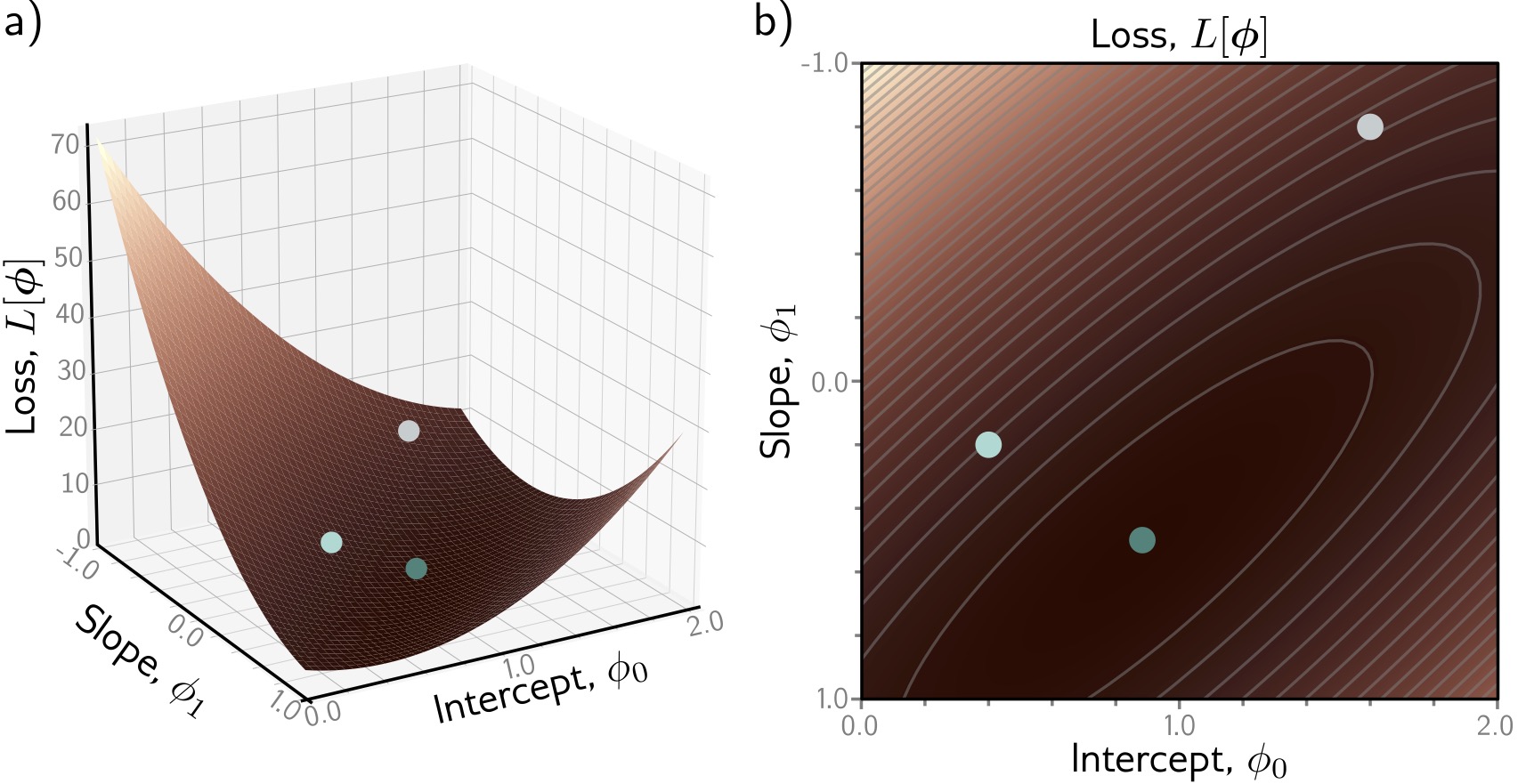
1-D linear regression model: Loss Surface
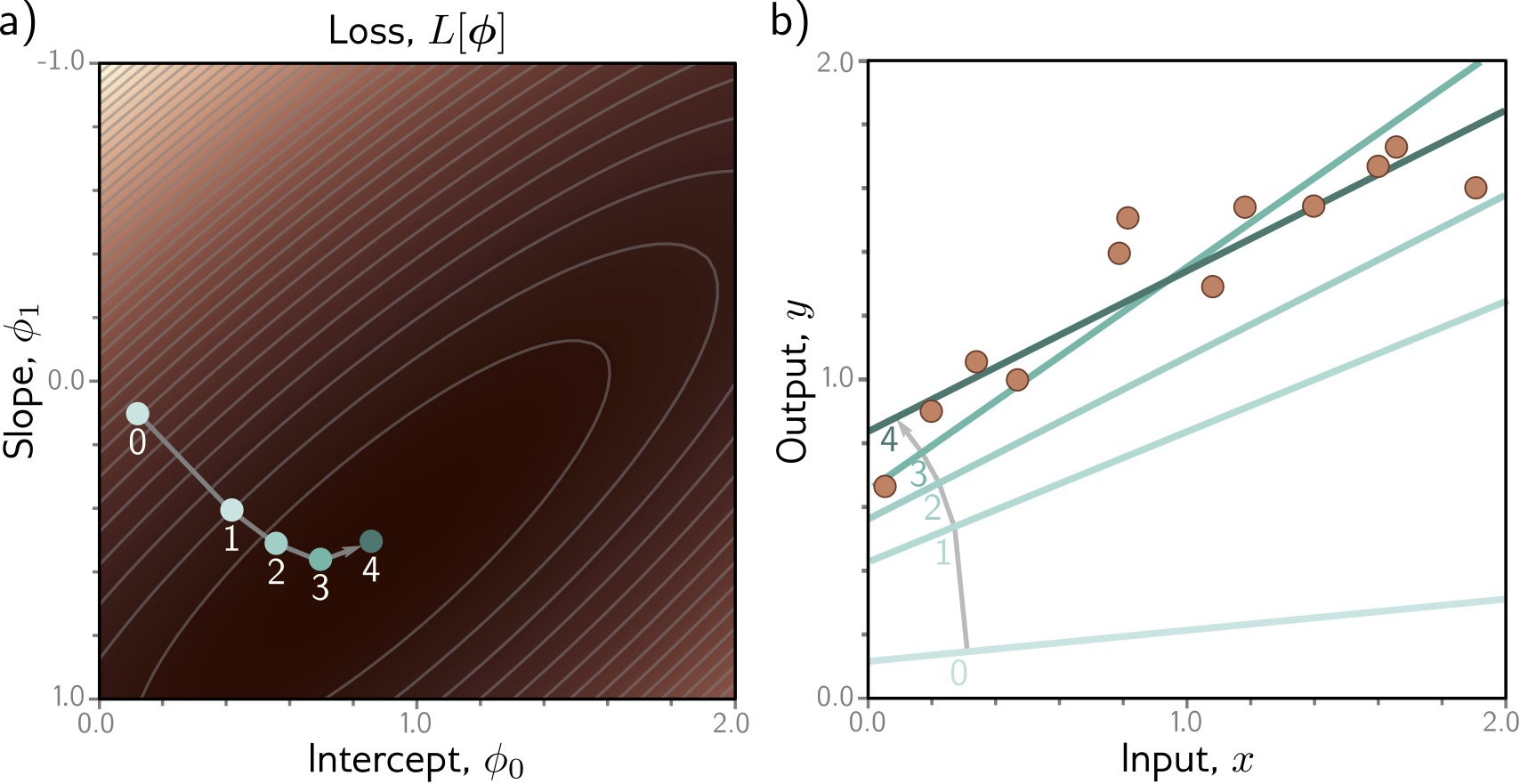
1-D linear regression model: Optimization
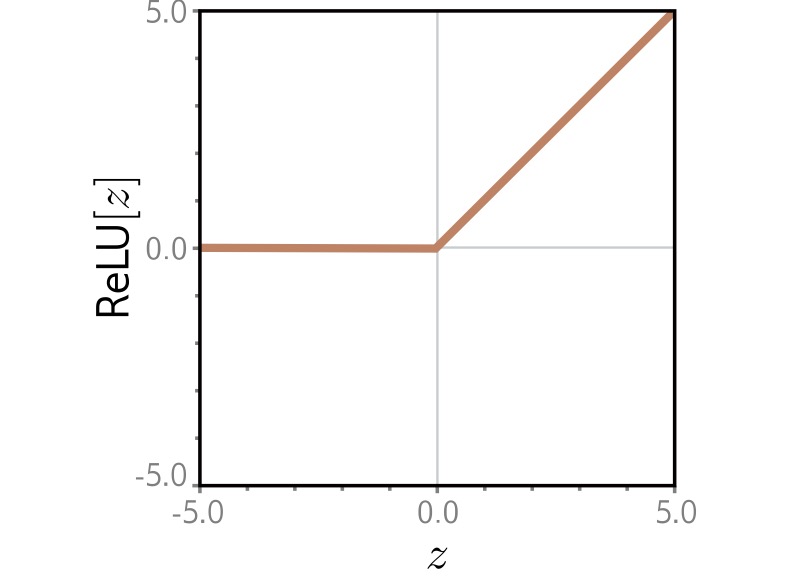
Shallow neural networks: Activation function ReLU
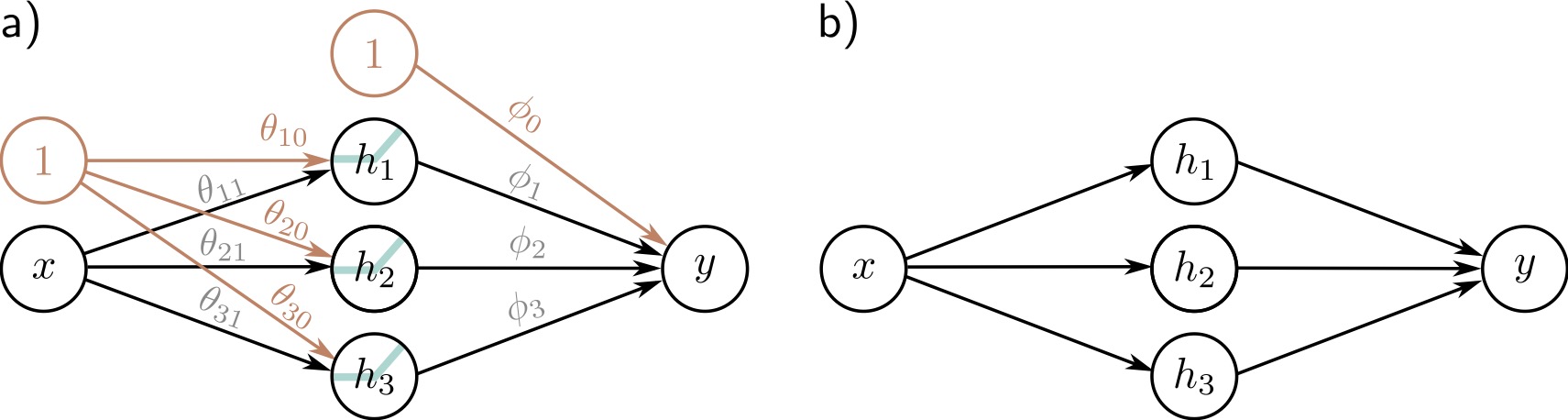
Shallow neural networks: Neural network intuition
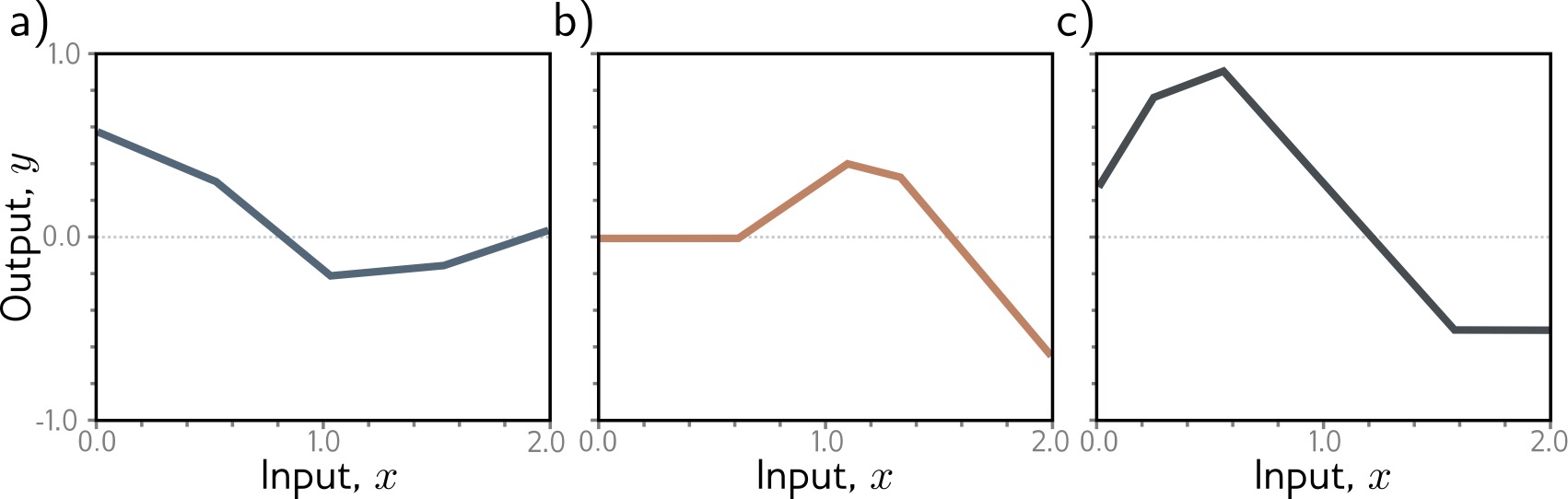
Shallow neural networks: Neural network intuition
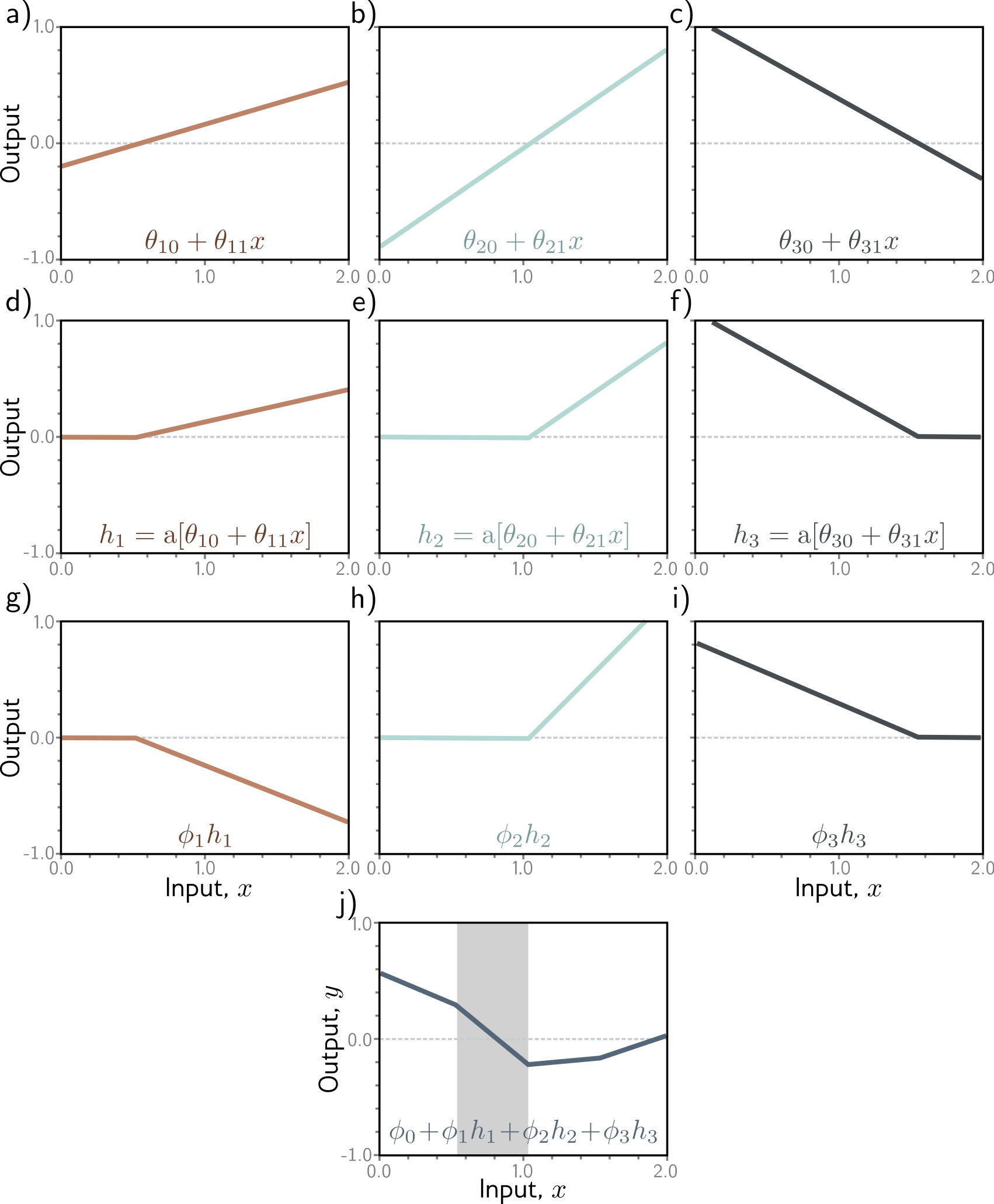
Shallow neural networks: Neural network intuition
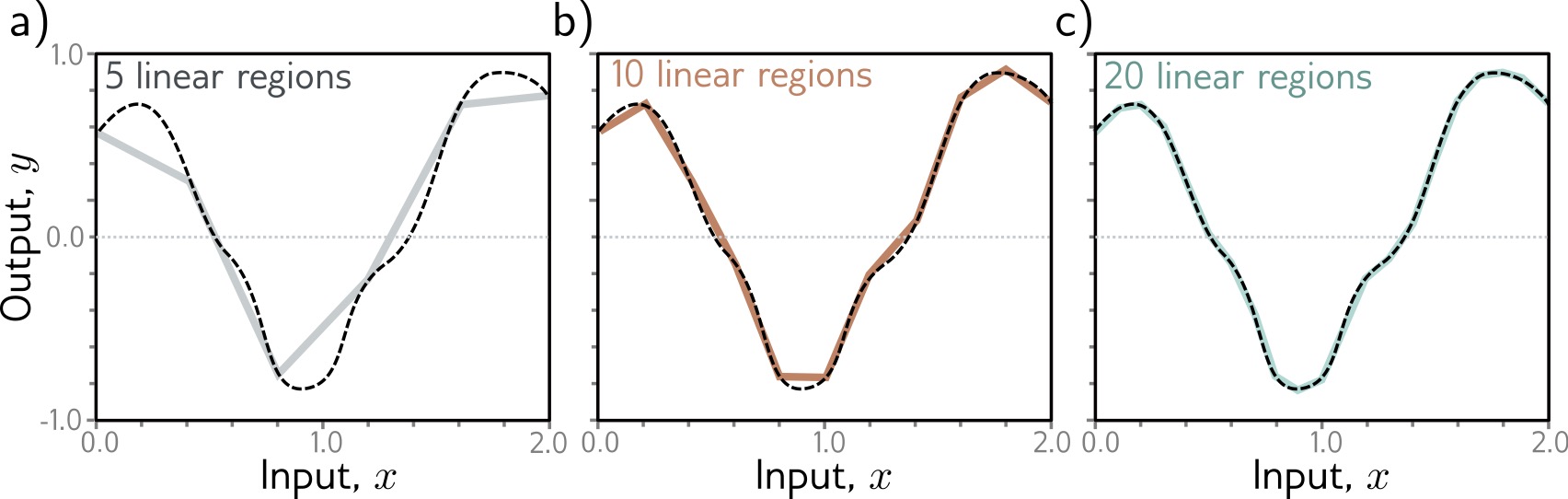
Shallow neural networks: Universal Approximation Theorem
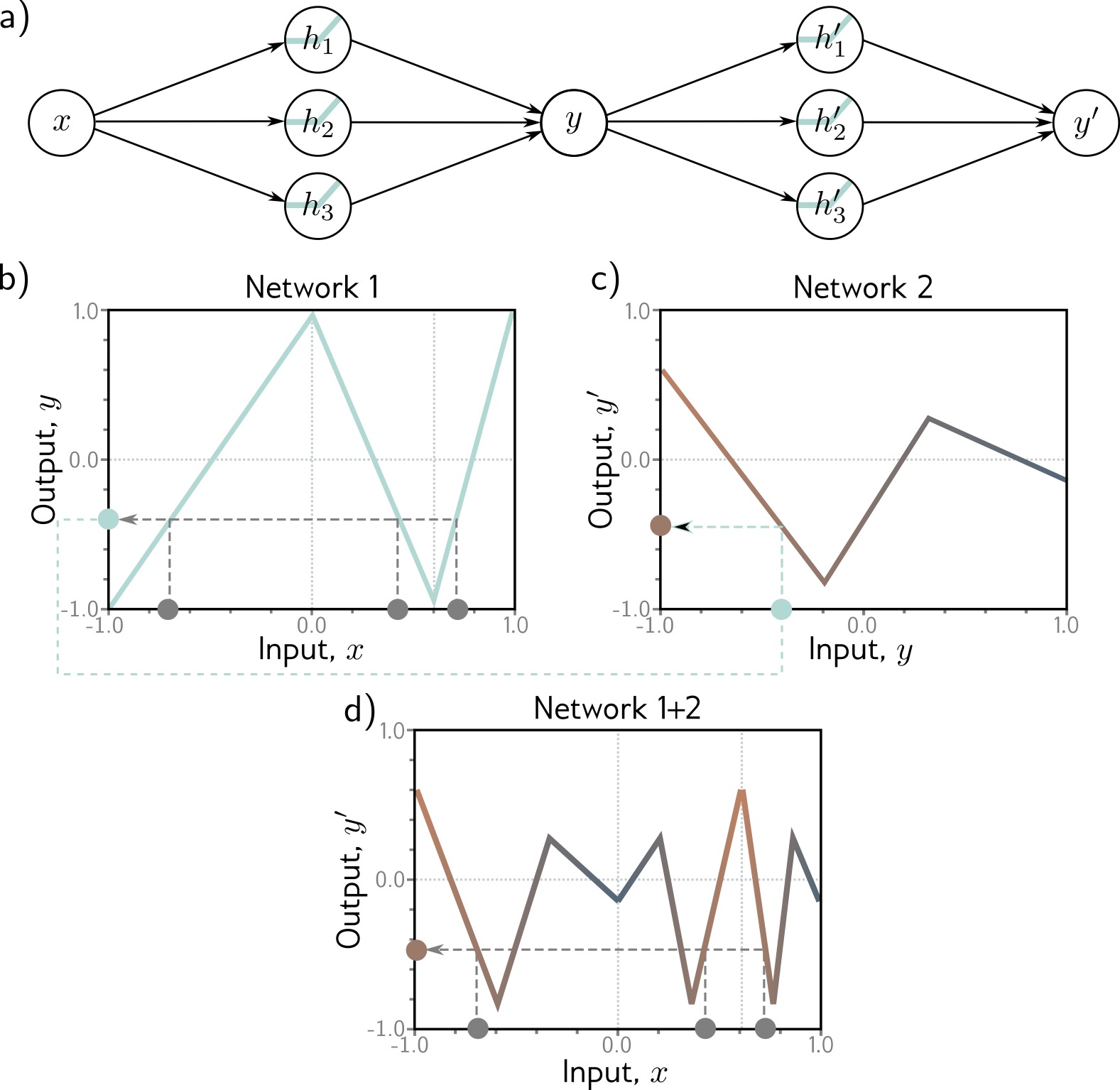
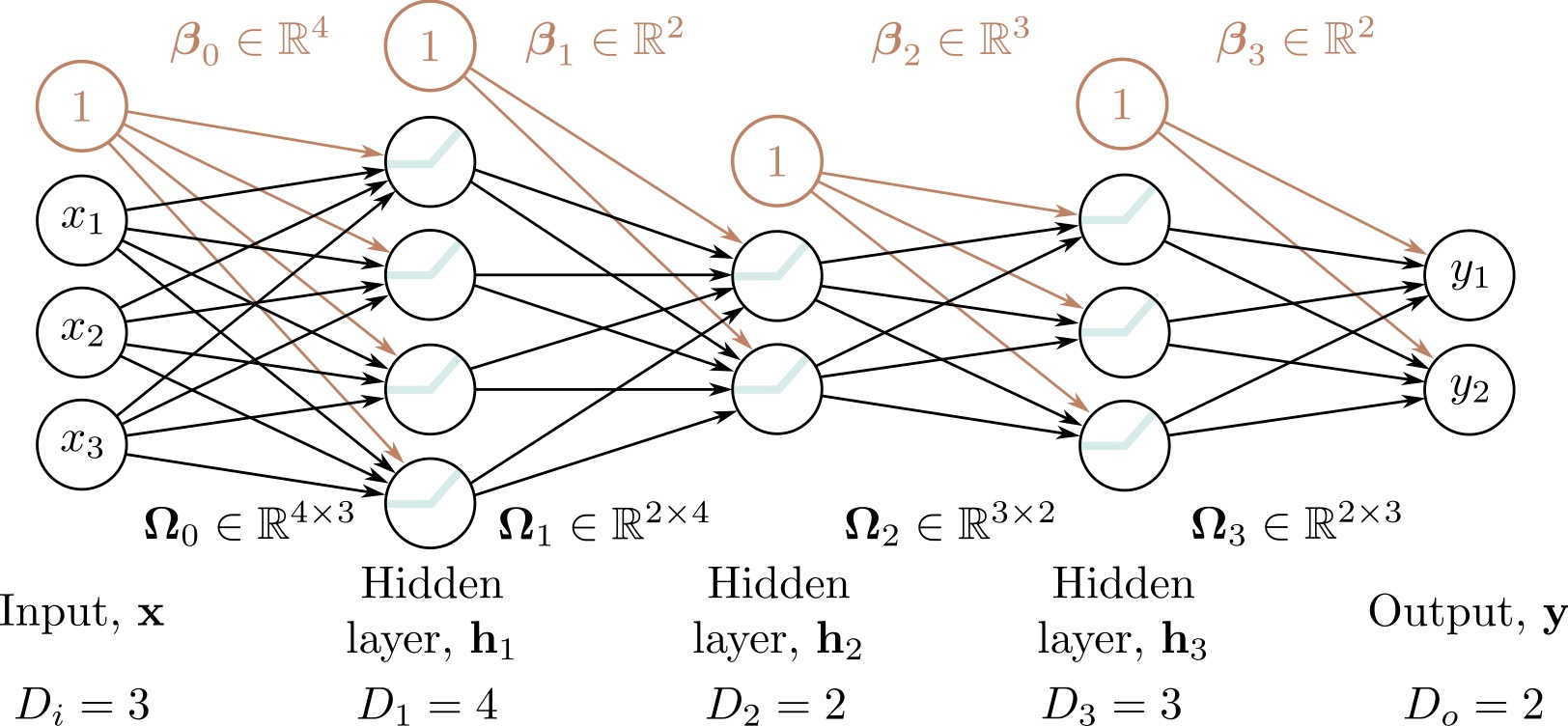
Deep neural networks: Composing multiple networks
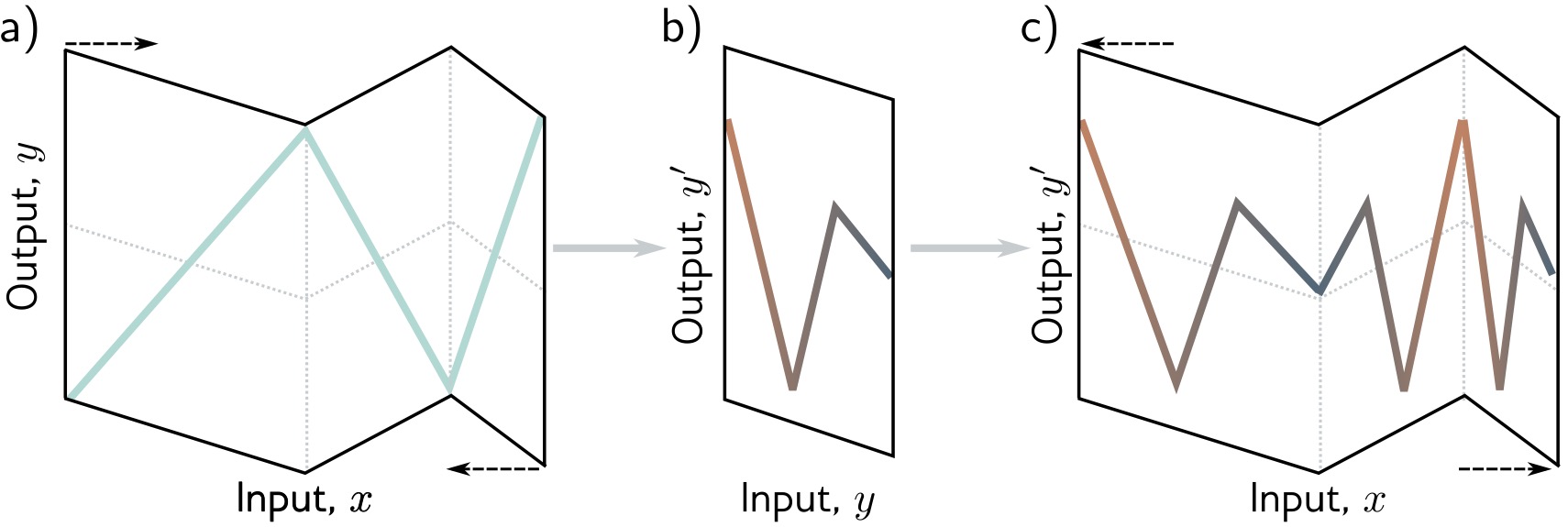
Deep neural networks: Folding Input Space
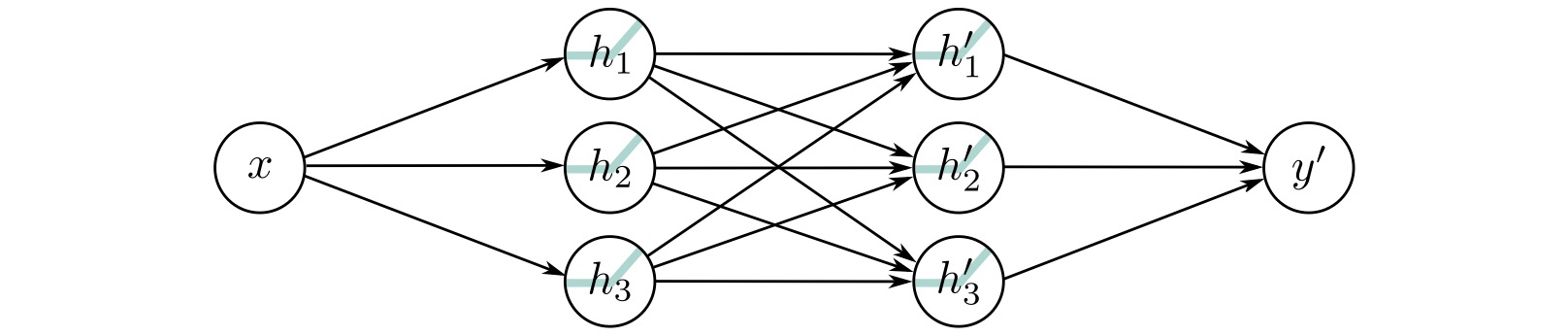
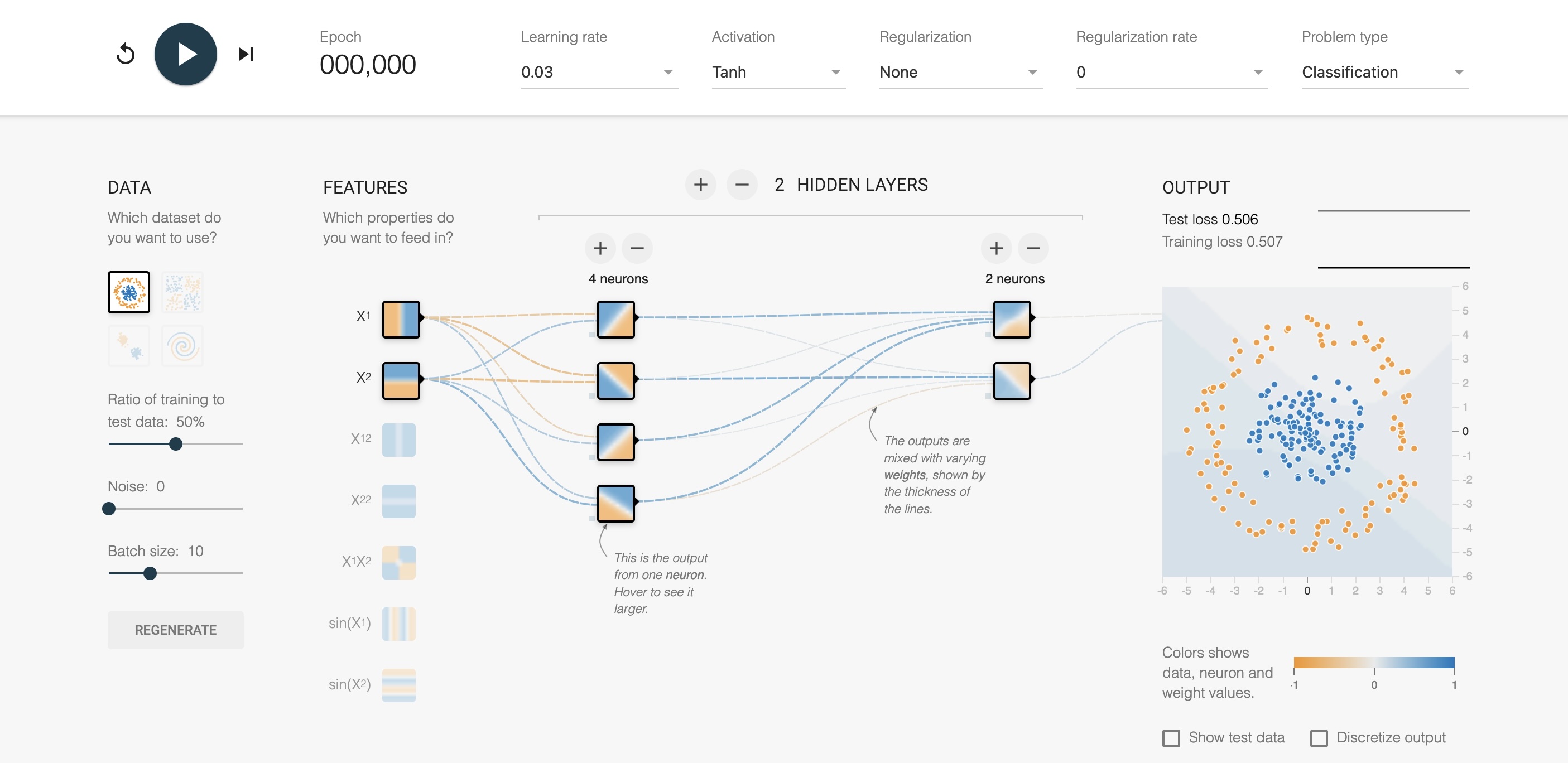
https://playground.tensorflow.org
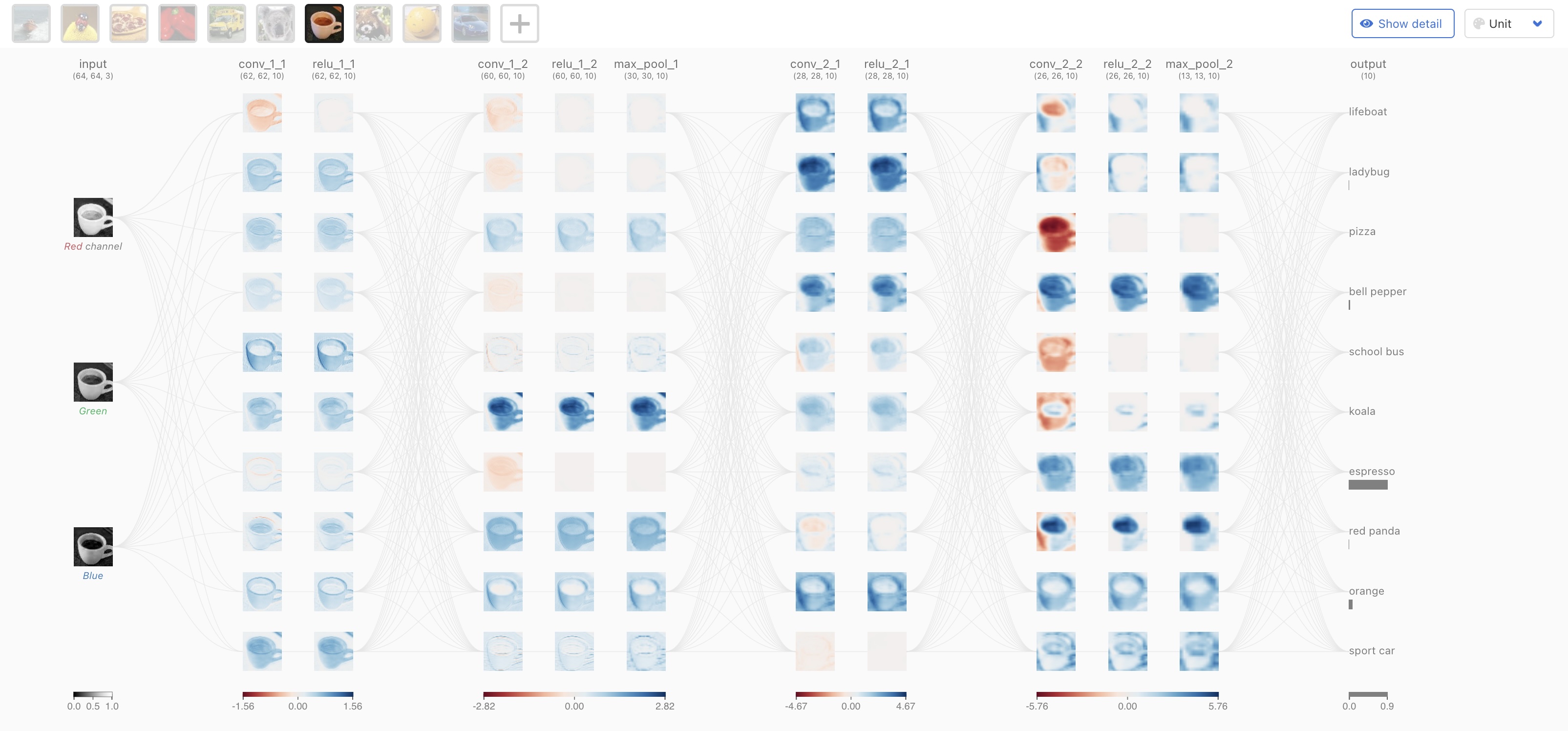
https://poloclub.github.io/cnn-explainer/
Further References
https://distill.pub/2020/grand-tour/
http://projector.tensorflow.org/
https://ml4a.github.io/ml4a/looking_inside_neural_nets/
