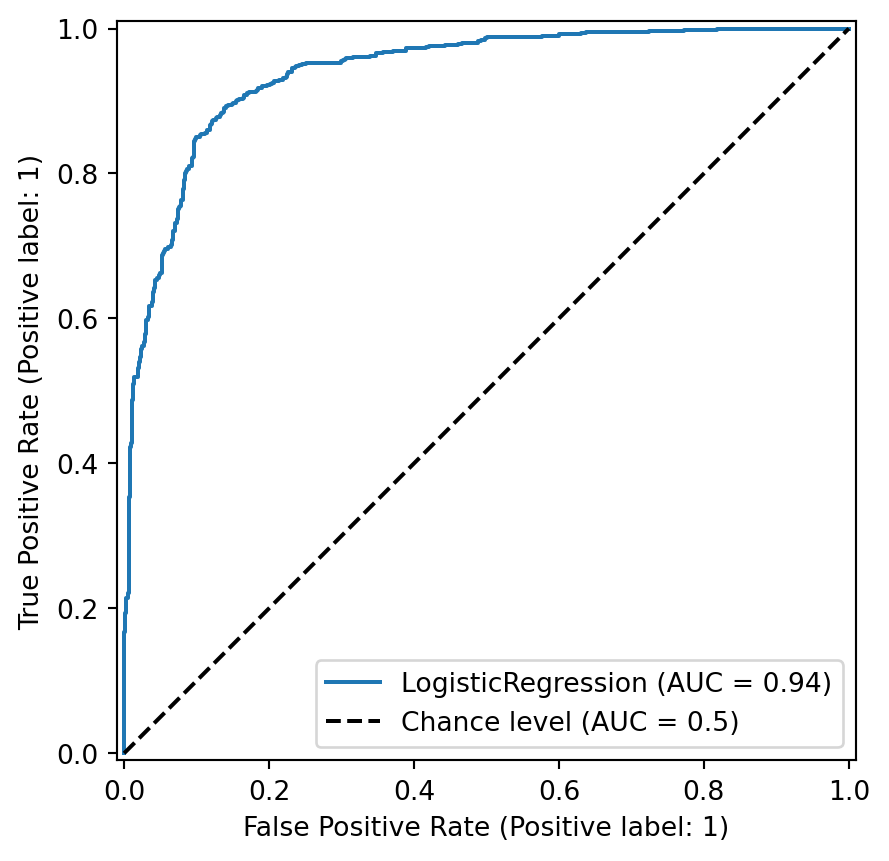
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay
clf.fit(X_train, y_train)
ConfusionMatrixDisplay.from_estimator(clf, X_test, y_test, cmap=plt.cm.Blues)
plt.show()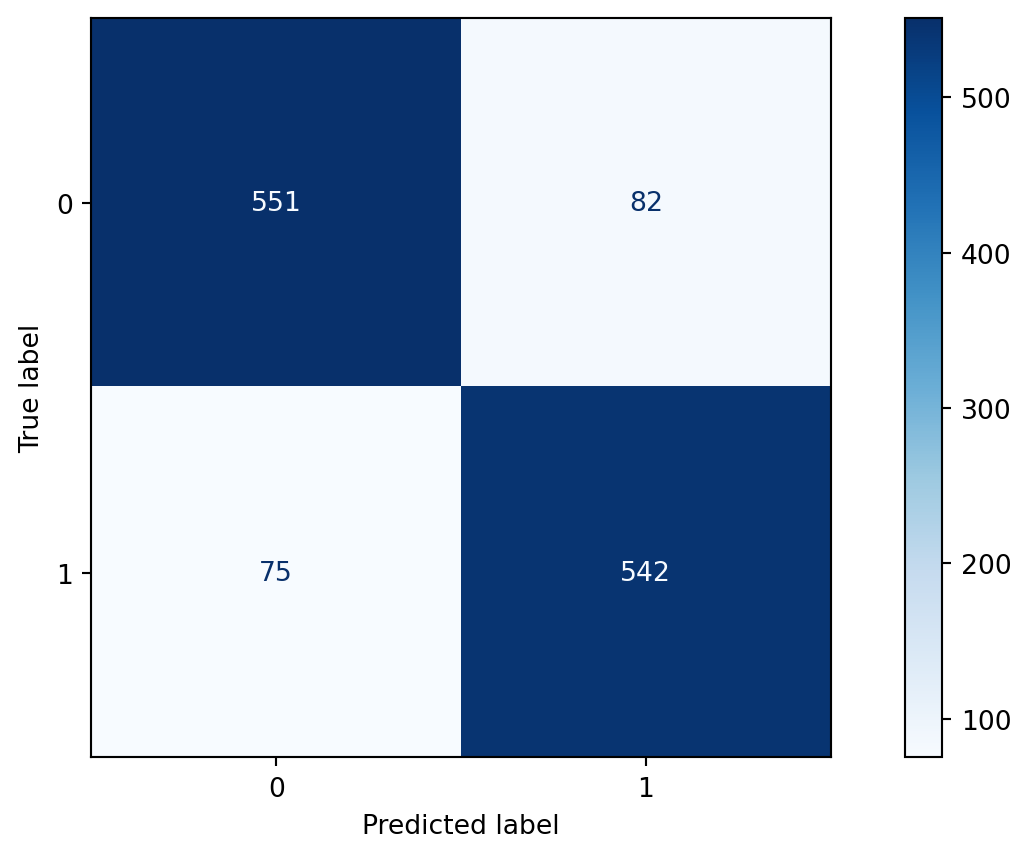
Spring 2024
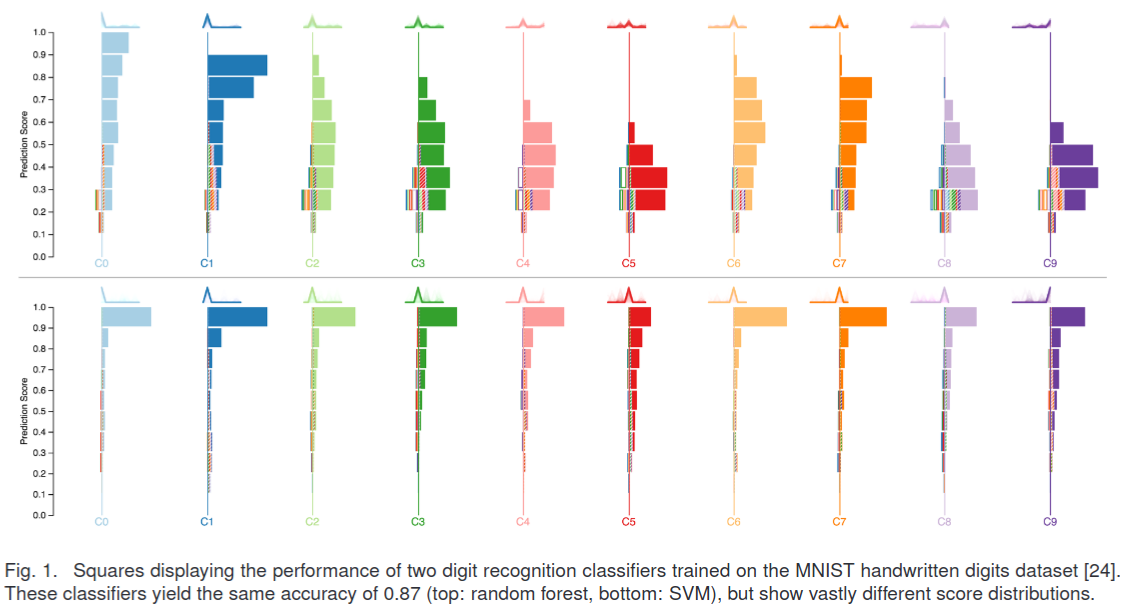
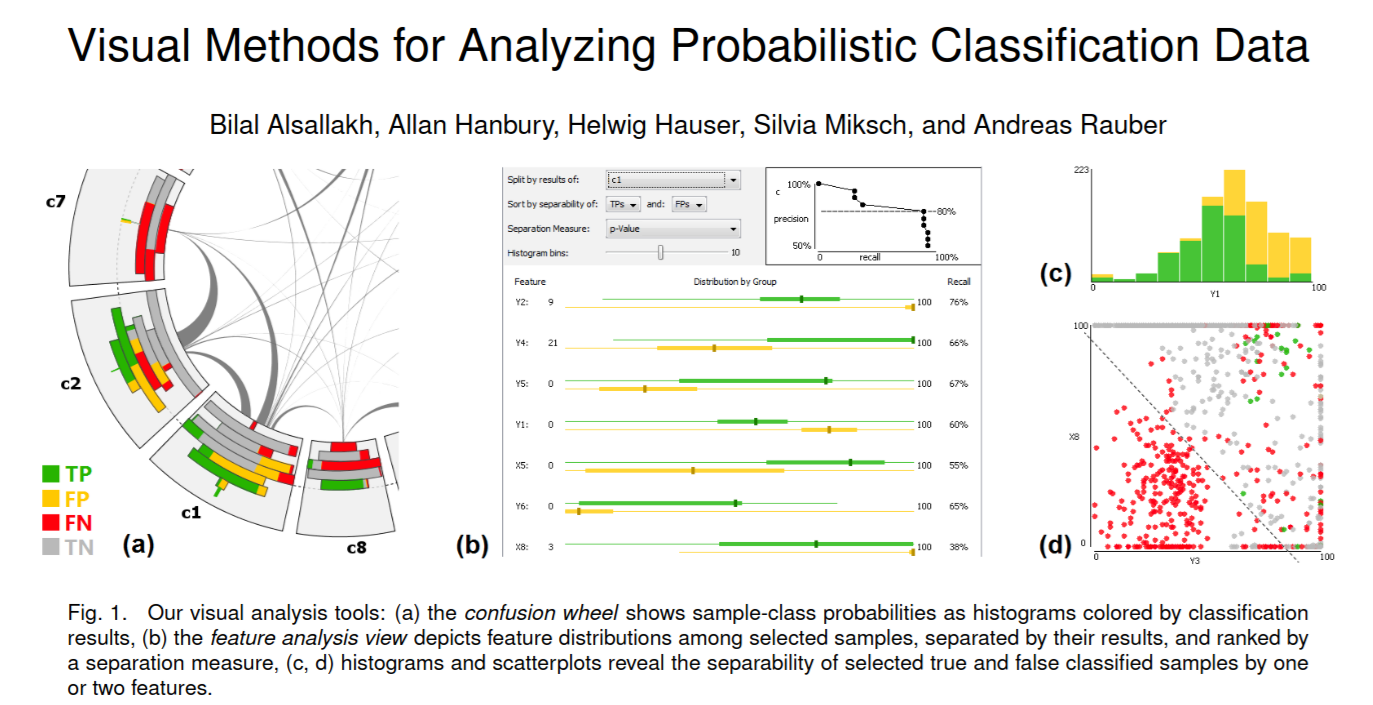
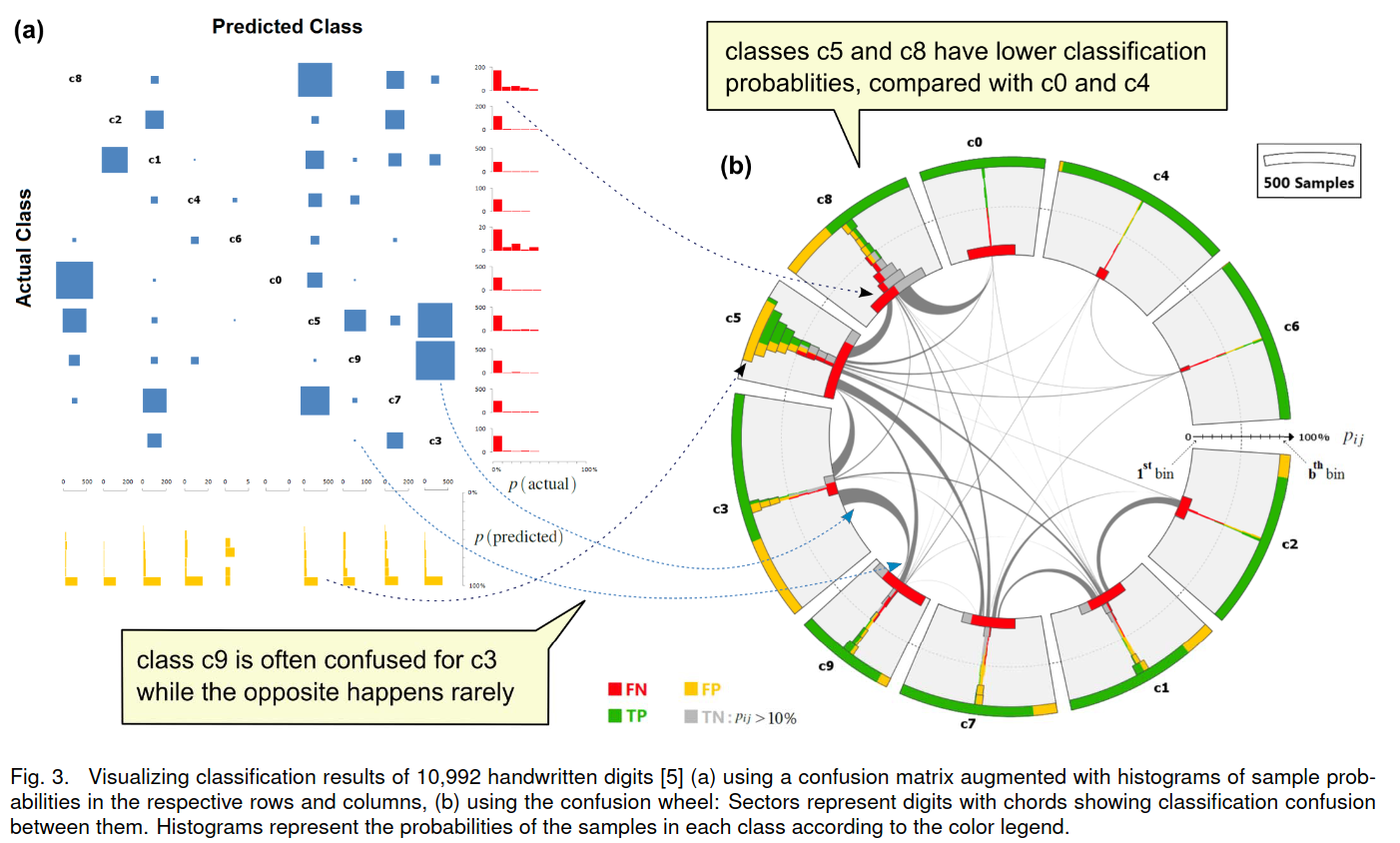
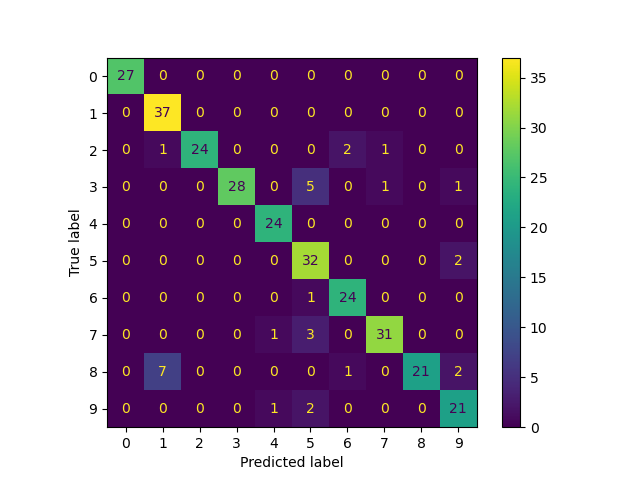
Consider a model to identify handwritten digits. All digits are equally probable and equally represented in the training and test datasets.
The model correctly identifies all of the digits, except for digit \(5\), classifying half of the \(5\)s samples as \(6\) and the other half is correctly identified
The accuracy of this model is \(95\%\). Is this information enough to determine whether the model is good or not?
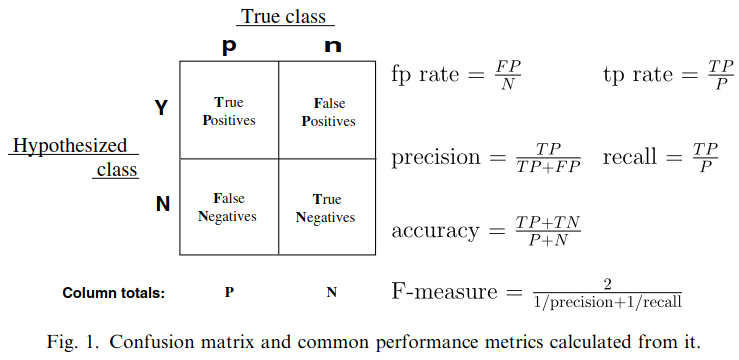
Pros
Cons
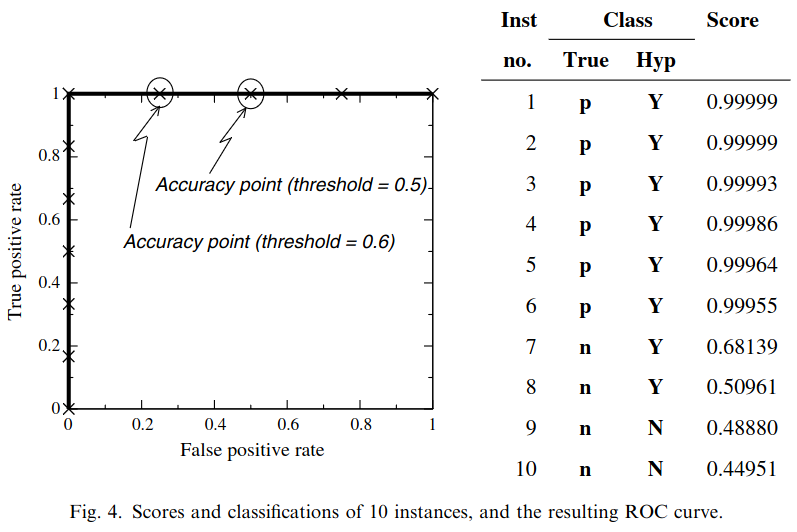
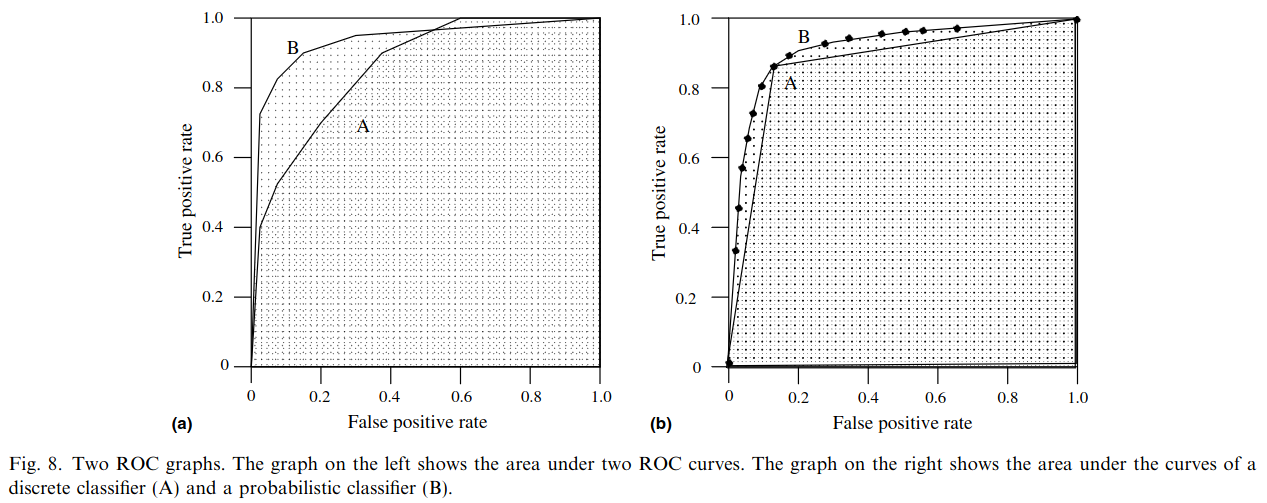
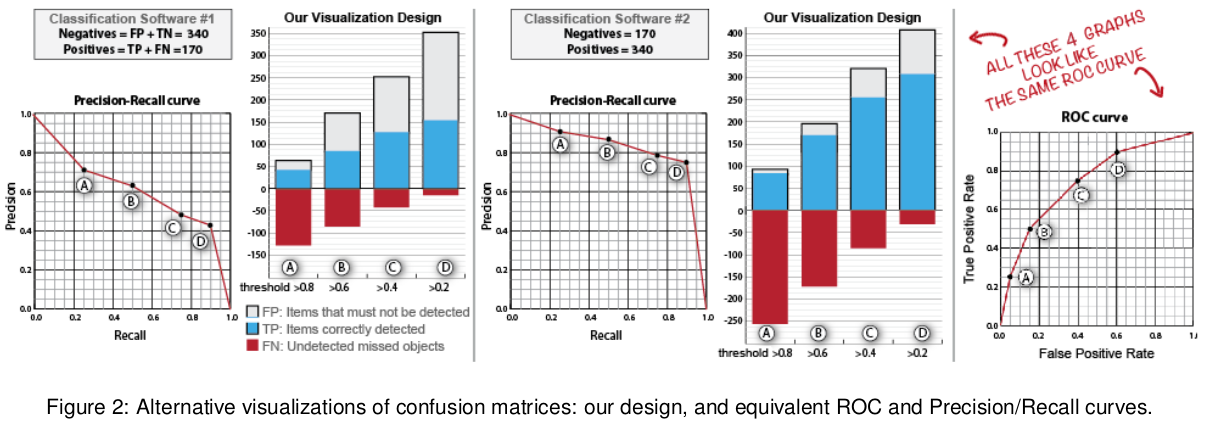
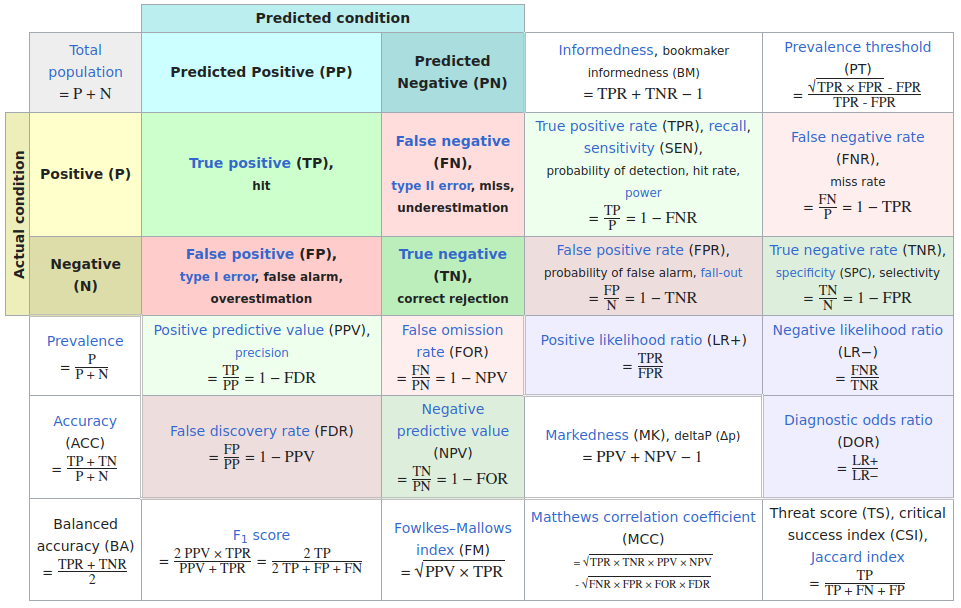
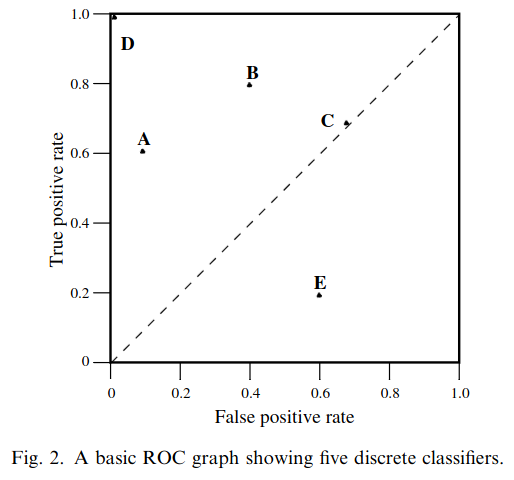
ROC analysis is another way to assess a classifier’s output
ROC analysis developed out of radar operation in the second World War, where operators were interested in detecting signal (enemy aircraft) versus noise
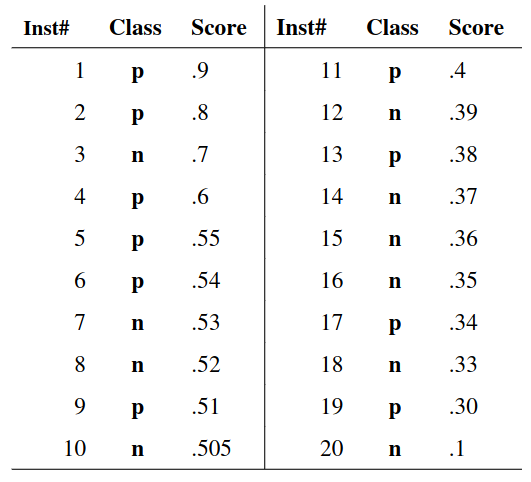
We create an ROC curve by plotting the true positive rate (TPR) against the false positive rate (FPR) at various thresholds



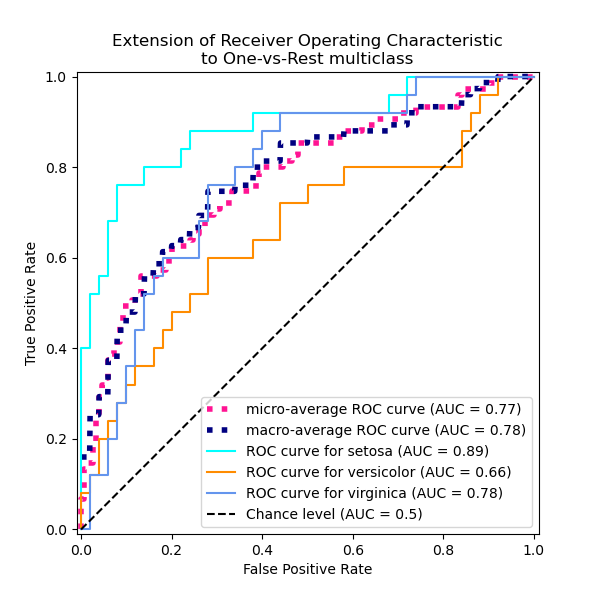
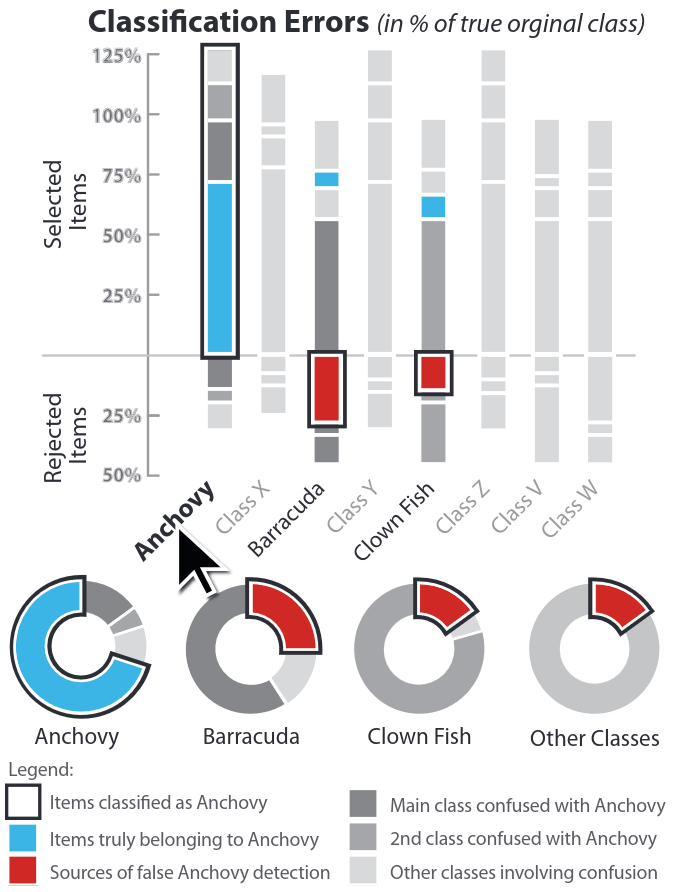
Micro-average: Aggregate contributions of all classes to calculate the metric. Useful if there is class imbalance.
Macro-average: Compute the metric for each class separately, then take average (treats all classes equally)
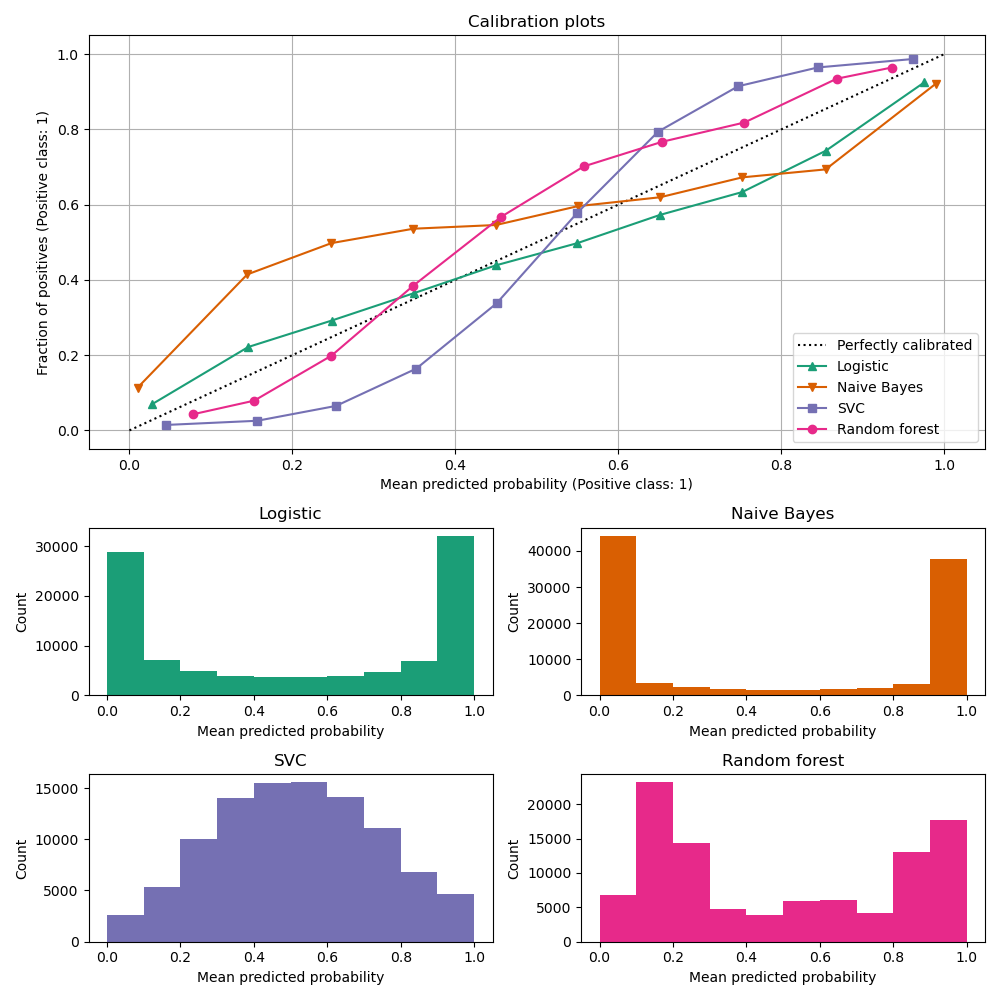
Weather forecasters started thinking about calibration a long time ago (Brier, 1950): a forecast of “70% chance of rain” should be followed by rain 70% of the time. Let’s consider a small toy example:
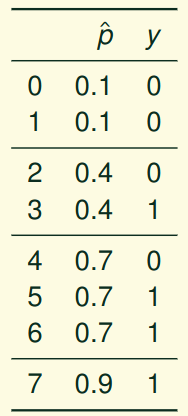
This forecast is doing at predicting the rain:
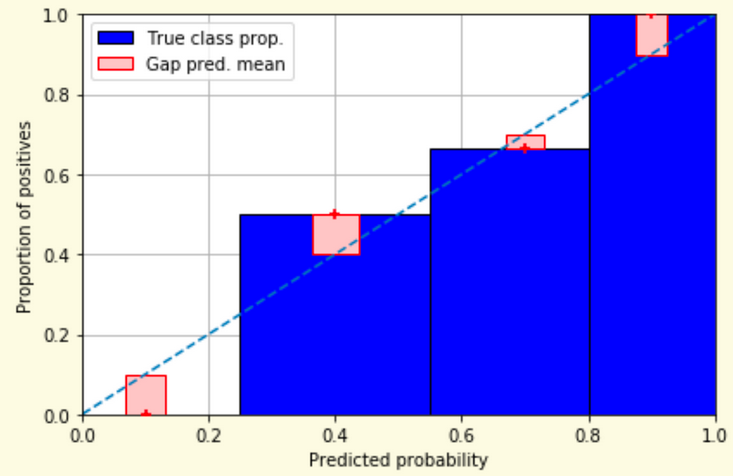

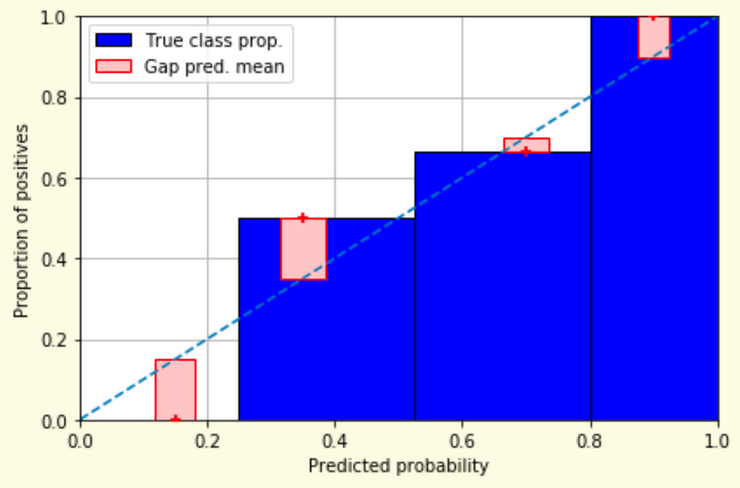
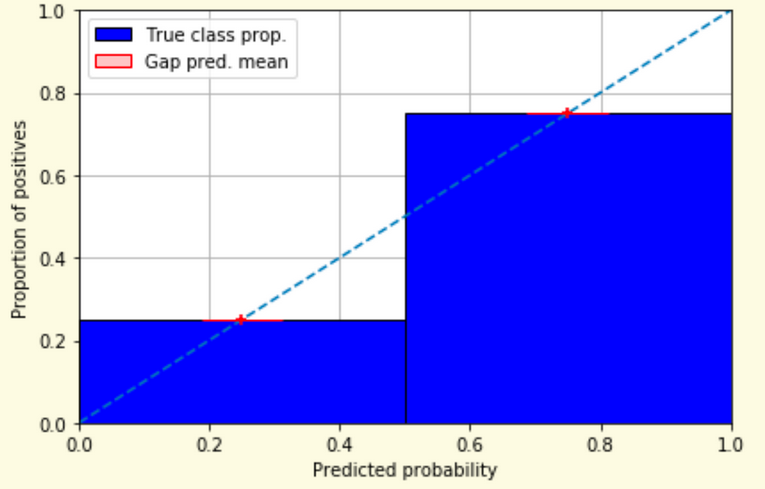
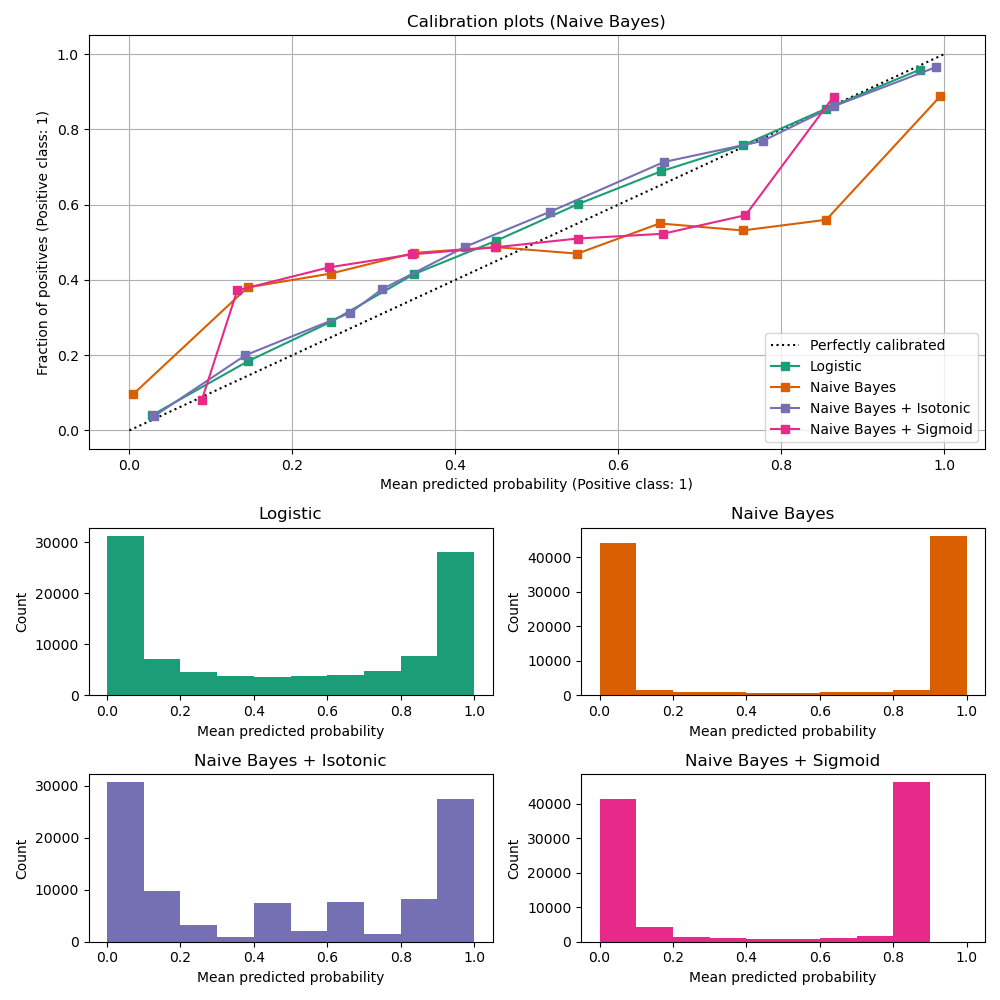
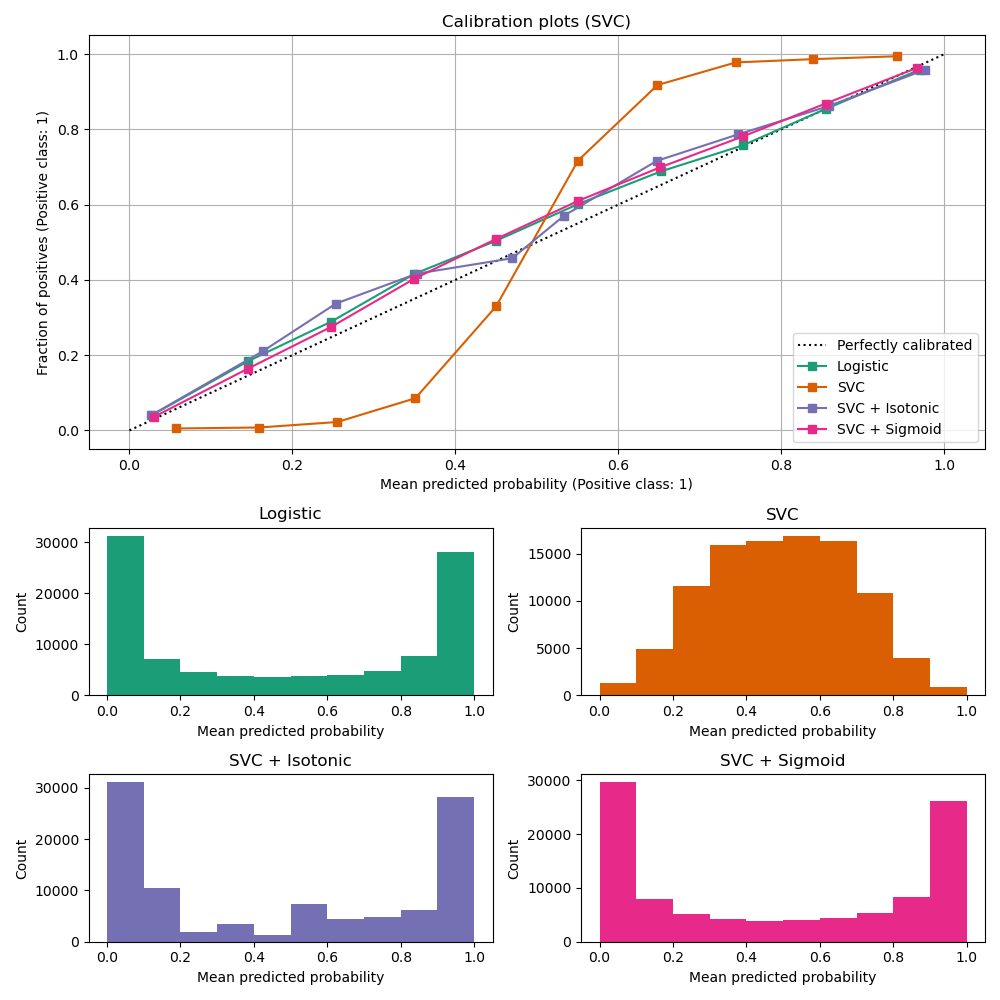
from sklearn.calibration import CalibrationDisplay
fig = plt.figure()
ax = fig.add_subplot(111)
CalibrationDisplay.from_estimator(lg, X_test, y_test, n_bins=10, ax=ax,
label='Logistic Regression')
CalibrationDisplay.from_estimator(nb, X_test, y_test, n_bins=10, ax=ax,
label='Naive Bayes')<sklearn.calibration.CalibrationDisplay at 0x140862c90>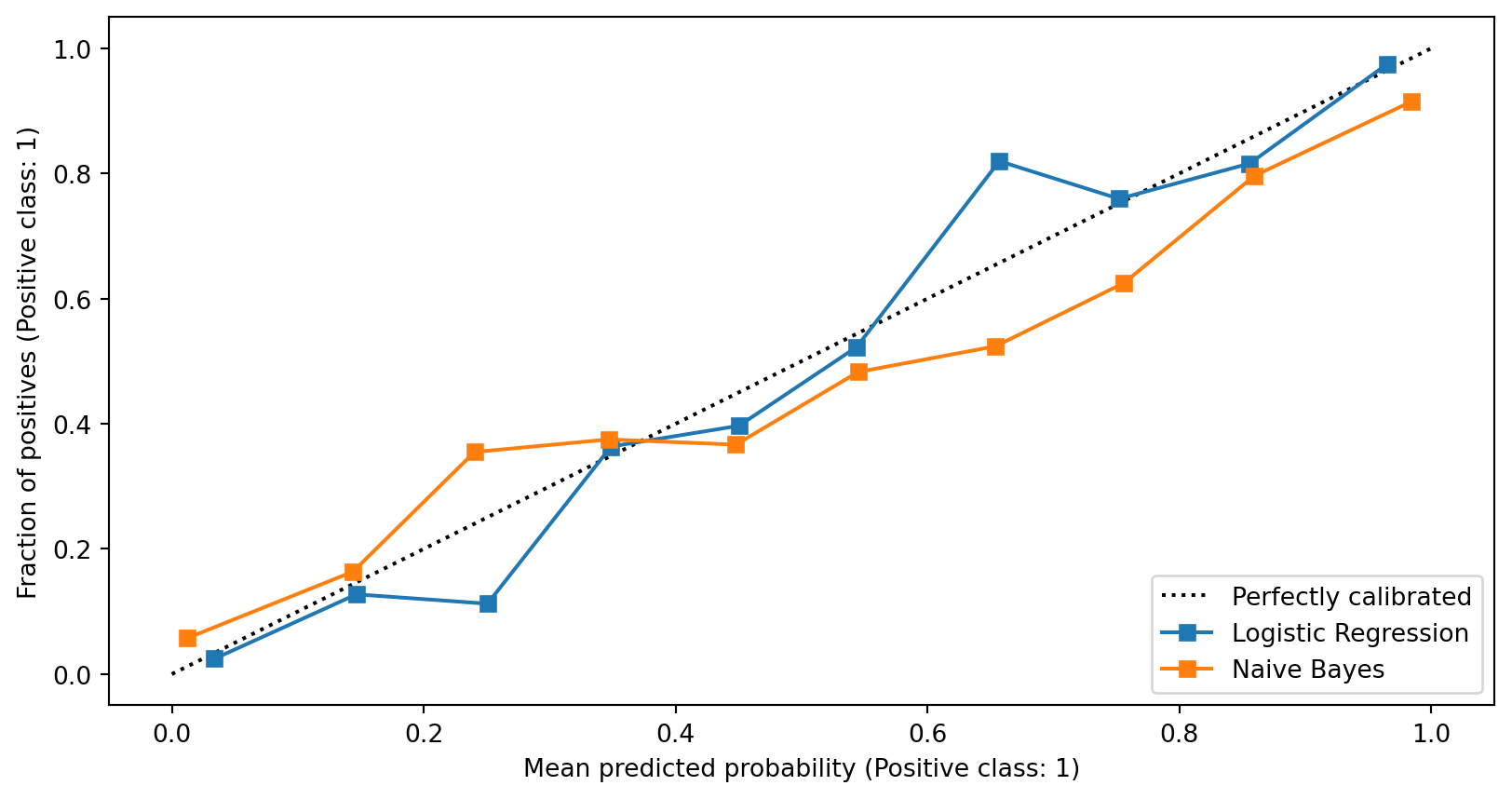
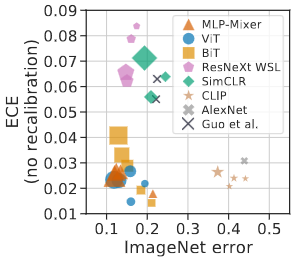
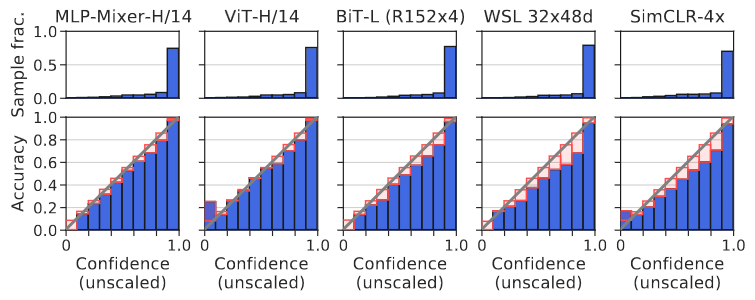
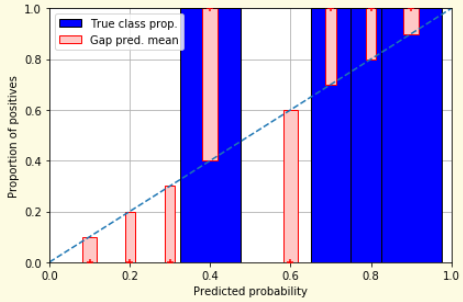
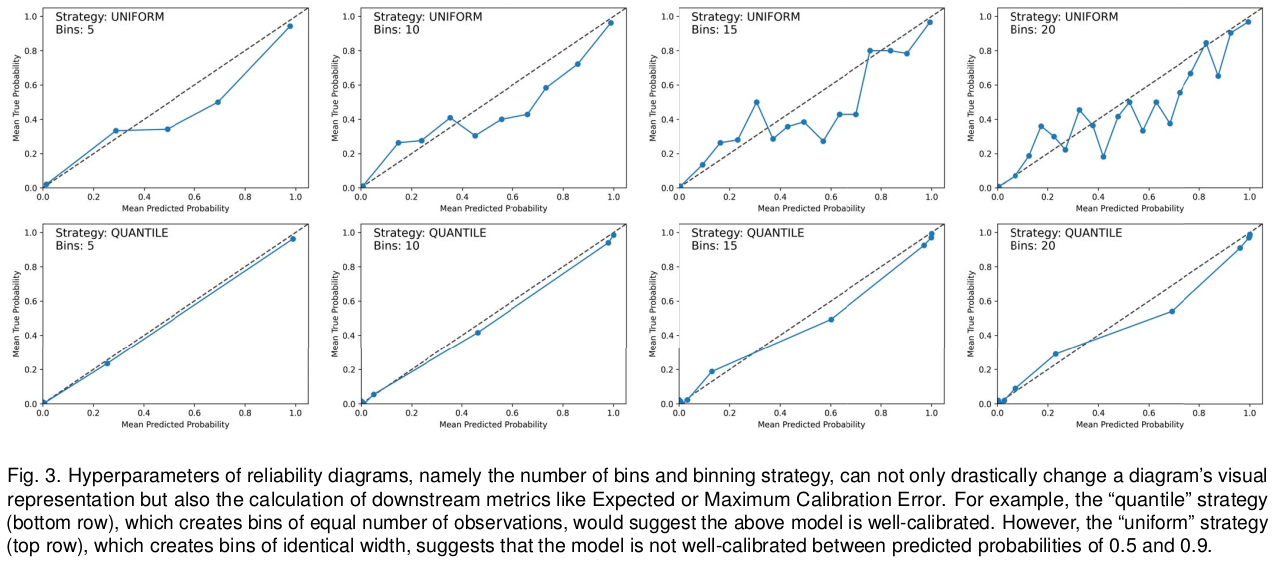
Proper scoring rules are calculated at the observation level, where as ECE is binned
Think of them as putting each item in its separate bin, then computing the average of some loss for each predicted probability and its corresponding observed label
Kull, M., & Flach, P. (2015, September). Novel decompositions of proper scoring rules for classification: Score adjustment as precursor to calibration. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases (pp. 68-85). Springer, Cham.
ECML/PKDD 2020 Tutorial: Evaluation metrics and proper scoring rules