White-box Model Interpretation
CS-GY 9223 - Fall 2025
Claudio Silva
NYU Tandon School of Engineering
2025-09-29
Week 5: White-box Model Interpretation
Model Interpretation and Explanation
White-box Approaches and Visualizations
Related Research in VIS & AI
Today we focus on interpretable machine learning models and their visualization. We’ll explore intrinsically interpretable models like linear regression, GAMs, decision trees, and rule-based systems. We’ll see how visualization helps us understand model behavior and how different model types offer different forms of interpretability.
Outline
Model Interpretation and Explanation
White-box Approaches and Visualizations Related Research in VIS & AI
What is Interpretability?
“Interpretability is the degree to which a human can understand the cause of a decision”
Can you predict what the model will do?
Can you understand why it made a particular decision?
Can you trust the model’s reasoning process?
Key Dimensions: Local (single prediction) vs. Global (overall model logic)
Interpretability fundamentally means understanding causation - why did the model produce this output? A more operational definition: a model is interpretable if a human can correctly and efficiently predict the model’s results. This goes beyond just seeing outputs - it requires understanding the mechanism. Importantly, interpretability has two scopes: Global interpretability means understanding the overall model logic and patterns, while Local interpretability focuses on explaining individual predictions. This distinction becomes crucial when we discuss techniques like LIME and SHAP in later lectures, which provide local explanations for otherwise black-box models.
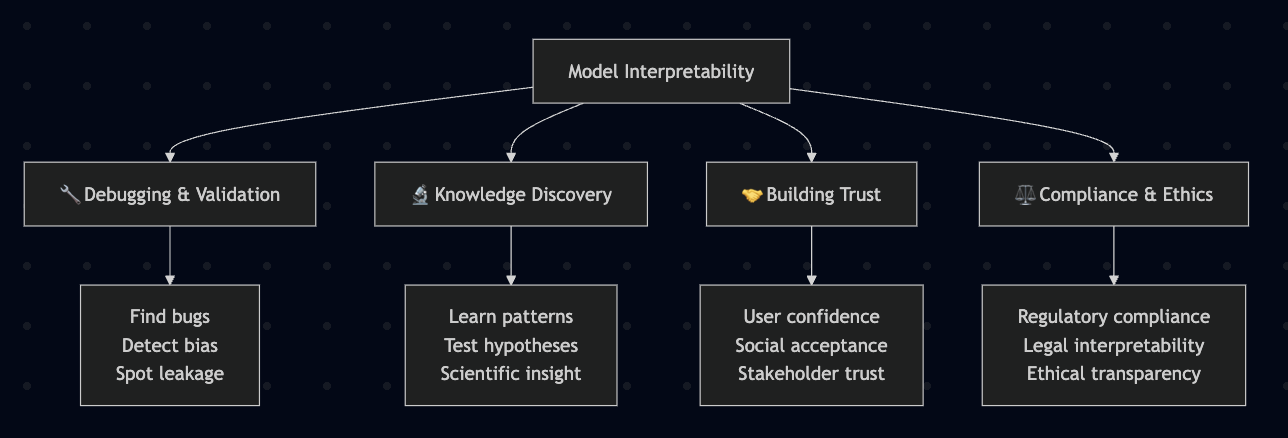
Why Model Interpretation & Explanation?
Four Key Functions:
🔧 Debugging & Validation - Detect bugs, biases, data leakage - Identify spurious correlations
🔬 Knowledge Discovery - Learn patterns, generate hypotheses - Extract scientific insights
🤝 Building Trust - Increase confidence, social acceptance - Enable stakeholder buy-in
⚖️ Compliance & Ethics - Meet legal/ethical requirements - Conduct fairness audits
Interpretability serves multiple critical functions. For debugging, we can catch issues like the model learning spurious correlations. For science, interpretable models reveal domain insights. For deployment, stakeholders need to trust the system. In regulated domains like healthcare and finance, interpretability may be legally required to justify decisions.
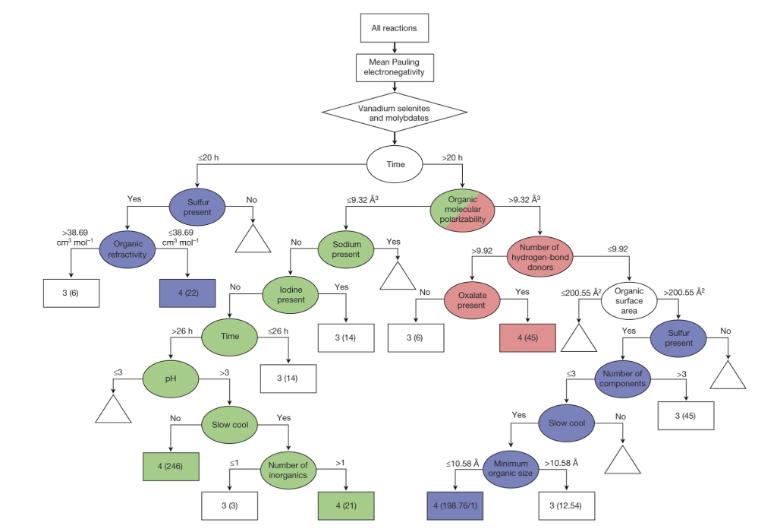
Machine-learning-assisted materials discovery using failed experiments
Researchers firstly built a database of chemistry experiments (new material).
Then they train an SVM to predict whether a new chemistry experiment will be successful.
Then they train a surrogate DT to explain the model to learn more about the experiment.
This Nature paper demonstrates using interpretable models to understand scientific experiments. By training a surrogate decision tree on SVM predictions, researchers could extract human-understandable rules about which experimental conditions lead to success.
Properties of Good Explanations
Human explanations are naturally:
Contrastive : “Why this, rather than that?” (not exhaustive)
Example: “Loan denied because debt-to-income ratio was 45%, not the required ≤30%”
Selective : Focus on 1-3 key reasons (not all causes)Social : Tailored to audience and contextFocused on abnormal : Highlight surprising factorsTruthful but simple : Balance accuracy with understandability
Research on human explanations reveals important patterns. People don’t want exhaustive causal chains - they want contrastive answers comparing to alternatives. Good explanations are selective, providing just a few key factors rather than everything. They should be tailored to the audience’s knowledge and focus on surprising or abnormal causes rather than routine factors. This guides how we should design ML explanations.
Why Model Interpretation & Explanation?
Fairness
Privacy
Reliability or Robustness
Causality
Trust
This paper highlights critical concerns in ML deployment. Fairness requires understanding if protected attributes influence decisions. Privacy needs transparency about what data influences predictions. Robustness demands knowing if the model relies on brittle features. Causality questions whether correlations are meaningful. All these build toward the ultimate goal: trust in AI systems.
Taxonomy of Interpretability Methods
Intrinsic (White-box)
Interpretability built into model structure
Examples: Linear models, short decision trees, sparse models
Understand by examining model internals
Today’s focus
Post-hoc (Black-box)
Explain after training
Works with any model (neural nets, ensembles)
Examples: LIME, SHAP, saliency maps
Next week’s topic
Additional dimensions: Model-specific vs Model-agnostic | Local vs Global | Feature importance vs Feature effects
Intrinsic interpretability means the model structure itself is understandable - you can look at a decision tree and trace the logic. Post-hoc methods generate explanations after the fact for any model. We also distinguish: model-specific (works for one type) vs model-agnostic (works for any), local (explains one prediction) vs global (explains overall behavior), and feature importance (which features matter) vs feature effects (how do features influence predictions). Today we focus on intrinsically interpretable white-box models.
Outline
Model Interpretation and Explanation White-box Approaches and Visualizations
Related Research in VIS & AI
White-box Models
We discuss the following models that are intrinsically interpretable:
Linear Regression
Generalized Additive Models (GAM)
Tree-based Models
Decision Rules
These model families offer varying degrees of expressiveness and interpretability. Linear models are simplest but most limited; GAMs add non-linear flexibility; trees provide natural visual structure; rules offer explicit logic.
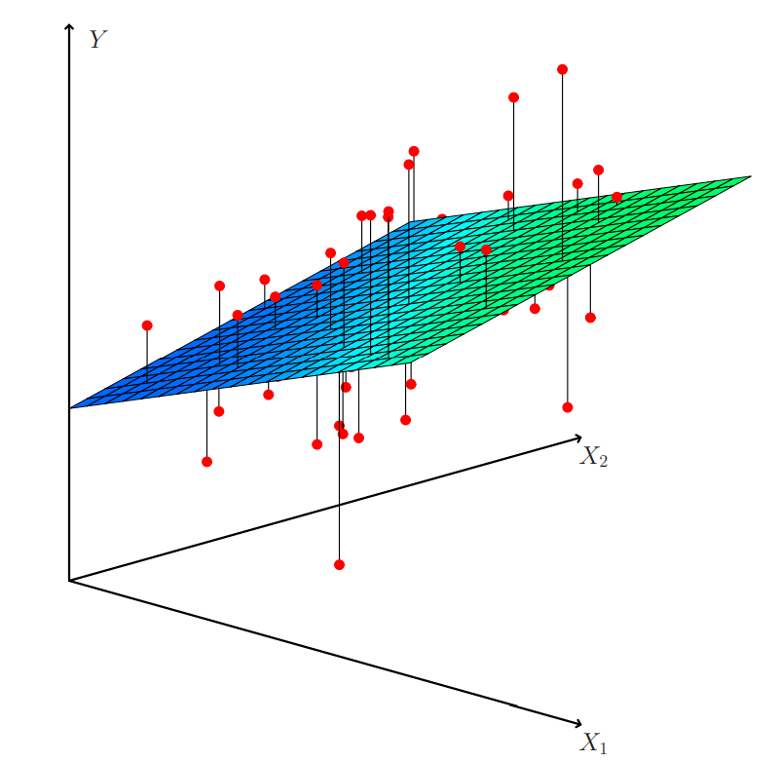
Linear Regression
Linear models can be used to model the dependence of a regression target y on some features x in a format as below: \[\begin{equation}
y = \beta_0 + \beta_1 x_1 + \ldots + \beta_n x_n + \varepsilon\end{equation}\]
The predicted target \(y\) is a linear combination of the weighted features \(\beta_i x_i\) . The estimated linear equation is a hyperplane in the feature/target space (a simple line in the case of a single feature).
The weights specify the slope (gradient) of the hyperplane in each direction.
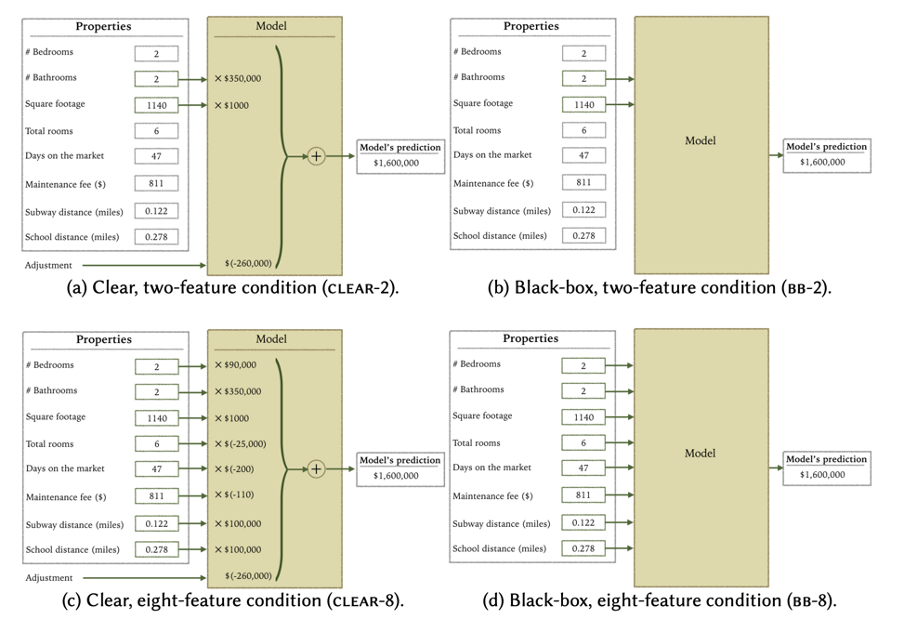
Linear regression remains one of the most interpretable models. Each coefficient directly tells us how much the prediction changes when that feature increases by one unit, holding all else constant. This direct interpretability makes linear models valuable for policy decisions and scientific inference.
Linear Regression
This visualization shows the geometric interpretation of linear regression as fitting a hyperplane through the data points. The residuals (vertical distances from points to the plane) are minimized during training using least squares optimization.
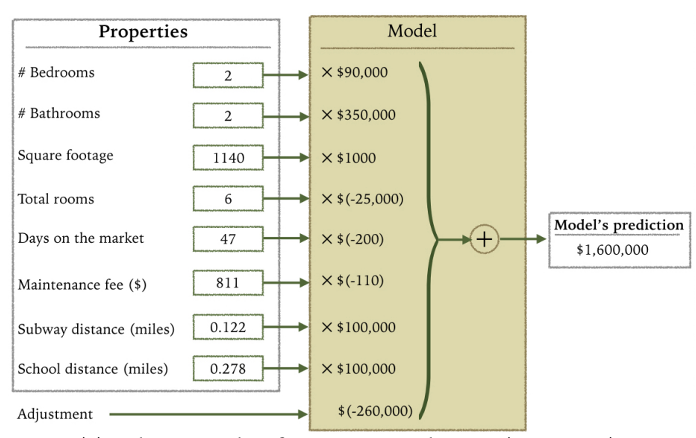
Linear Regression: An Example of Housing Price
How do you interpret the influence of each property on the prediction of housing price?
In this housing price model, we can directly read off the coefficients: each additional bedroom adds a certain amount to the price, each square foot contributes its value, proximity to schools has a measurable effect. The sign tells us direction (positive/negative), the magnitude tells us importance. This direct interpretability makes linear models valuable for explaining decisions to stakeholders.
Interpreting Linear Model Coefficients
Basic interpretation: An increase in feature \(x_j\) by one unit changes the prediction by \(\beta_j\) units
✅ Numerical features : Direct marginal effect (holding others constant)
✅ Categorical features : Coefficients show difference from reference category
⚠️ Scale-dependent : Coefficients change with feature units
⚠️ “Holding others constant” assumes Feature Independence (a strong assumption!)
The standard interpretation is deceptively simple: each coefficient tells you the marginal effect of that feature. But be careful - this interpretation assumes you can change one feature while holding others constant, which may not be realistic. For example, in housing, you can’t easily change square footage without affecting other features. Coefficients are also scale-dependent - standardizing features helps comparisons.
Important Assumptions for Interpretation
Linear models make strong assumptions:
Linearity : Effects are additive (no interactions unless explicitly added)
Independence : Features are not strongly correlated
Homoscedasticity : Constant error variance
No multicollinearity : Correlated features can flip coefficient signs!
Example: Housing model with both “square footage” AND “number of rooms”
These features are highly correlated (VIF > 10)
Coefficients become unstable and unreliable for interpretation
Model predicts well, but individual coefficients are meaningless
When features are correlated (multicollinearity), coefficients become unstable and can even change signs in counterintuitive ways. VIF (Variance Inflation Factor) measures this: VIF = 1 means no correlation, VIF > 10 indicates severe multicollinearity. In the housing example, square footage and rooms are highly correlated - bigger houses have more rooms. Their individual coefficients become unreliable because the model can’t separate their independent effects. The model can still predict well, but you shouldn’t interpret individual coefficients. Always check VIF or correlation matrices before interpreting coefficients.
Evaluation of Linear Regression Model
Notation:
\(y_i\) = actual/true value for sample \(i\) \(\hat{y}_i\) = predicted value for sample \(i\) \(\bar{y}\) = mean of all actual values\(N\) = number of samples
R Square
\(R^2\) (R-squared): Proportion of variance explained \[\begin{equation}
R^2 = 1 - \frac{\sum (y_i - \hat{y}_i)^2}{\sum (y_i - \bar{y})^2}
\end{equation}\]
Mean Square Error (MSE)/Root Mean Square Error (RMSE) \[\begin{equation}
MSE = \frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2, \quad RMSE = \sqrt{MSE}
\end{equation}\]
Mean Absolute Error (MAE) \[\begin{equation}
MAE = \frac{1}{N} \sum_{i=1}^{N} |y_i - \hat{y}_i|
\end{equation}\]
R-squared tells us the proportion of variance explained by the model (ranges 0-1, higher is better). MSE/RMSE penalize large errors more heavily than MAE due to squaring. Choose metrics based on your application’s tolerance for outliers - use MAE if you want robust estimates, MSE if large errors are particularly costly. Note that R-squared can be misleading with many features - adjusted R-squared accounts for model complexity.
Visual Analytics (VA) Systems for Linear Regression
Core Visualizations:
Scatterplot Matrix : Explore feature relationships and partitionsParallel Coordinates : Analyze high-dimensional patternsInteractive Partitioning : Split data to test model stability
Key Insights:
Trade-off between model complexity and accuracy
Feature ranking and selection
Model validation across partitions
This IEEE TVCG Best Paper (VAST 2013) presents an interactive system for exploring the accuracy-complexity tradeoff in linear models. The system uses scatterplot matrices to visualize relationships between features and identify potential partitions in the data. Parallel coordinates help analysts understand high-dimensional patterns and feature interactions. Users can interactively partition the data, add or remove features, and immediately see the impact on model performance metrics like R-squared and cross-validation error. This combination of visualizations helps identify the simplest model that achieves acceptable accuracy while understanding how the model performs across different data subsets.
Pros, Cons, and Limitations of Linear Models
✅ Pros:
Highly interpretable : Each coefficient has clear meaningStatistical guarantees : Inference possible when assumptions holdFast : Analytical solution, no hyperparametersTransparent : Easy to explain to stakeholders
⚠️ Cons & Limitations:
Linearity assumption : Cannot capture non-linear relationshipsGaussian assumption : Features assumed to follow normal distributionMulticollinearity : Correlated features break interpretationNo interactions : Must manually add interaction termsAssumption violations : Wrong inference if residuals not normal
What if your dataset does not follow these assumptions?
Linear models shine when relationships are truly linear and assumptions hold (normal residuals, homoscedasticity, no multicollinearity). But real-world data often violates these assumptions - many real phenomena have non-linear relationships (e.g., diminishing returns, threshold effects) and feature interactions (e.g., temperature × humidity jointly affecting comfort). When data violates linear assumptions, we need more flexible models like GAMs.
Generalized Additive Models (GAMs)
GAMs extend linear models by replacing linear terms with flexible shape functions:
\[\begin{equation}
g(\mathbb{E}[y|X]) = \beta_0 + \sum_{j=1}^{p} f_j(x_{j})
\end{equation}\]
Key idea: Replace \(\beta_j x_j\) (linear) with \(f_j(x_j)\) (flexible smooth function)
Each \(f_j\) is learned from data (typically using splines)
Maintains additive structure → still interpretable
Can mix linear and non-linear terms
GAMs replace linear terms with smooth functions that can capture non-linear patterns. Each feature gets its own learned shape function (often splines or smoothing functions). The model remains additive (no interactions by default) which preserves interpretability - we can visualize each function independently. The link function g allows for different target distributions (normal for regression, logistic for classification).
GAMs are Interpretable via Partial Dependence Plots (PDPs)
Linear Model: \(y = \beta_j x_j\)
Fixed slope \(\beta_j\)
Constant effect across all values
Example: Each year of age adds $1,000 to salary
GAM: \(y = f_j(x_j)\)
Flexible shape function
Effect varies across feature range
Example: Salary peaks at age 45-55, declines after
Visualization: PDPs show \(f_j(x_j)\) - the contribution of feature \(x_j\) to the prediction across its range
Partial Dependence Plots are what make GAMs interpretable. Instead of a single coefficient, we get a curve showing how the feature’s contribution changes across its range. This reveals patterns like U-shapes (high at extremes), S-shapes (threshold effects), or plateaus (saturation). PDPs answer: “How does changing this feature affect predictions, on average?” The y-axis shows contribution relative to the mean prediction.
How GAMs Work: Splines as Building Blocks
GAMs use splines (piecewise polynomial functions) to approximate smooth curves:
Technical approach:
Replace feature \(x_j\) with basis functions
Fit weights to these basis functions
Add penalty term for smoothness
Interpretation:
Visualize each \(f_j(x_j)\) as a curve
Y-axis shows contribution to prediction
Relative to mean prediction
Under the hood, GAMs convert each feature into multiple “basis functions” (like polynomial terms or spline segments). The model learns weights for these basis functions, similar to how linear regression learns coefficients. A smoothness penalty prevents overfitting by penalizing overly wiggly curves. This is controlled by cross-validation. The result: smooth, interpretable curves showing each feature’s effect.
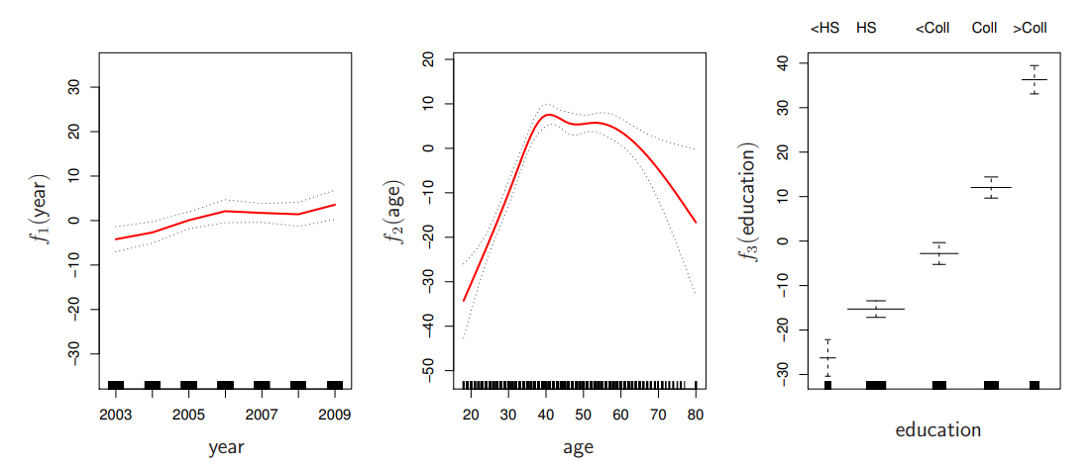
Generalized Additive Models (GAMs): An Example
\[\begin{equation}
Wage = f(year, age, education) = b_0 + f_1(year) + f_2(age) + f_3(education)
\end{equation}\]
This wage prediction example shows how GAMs capture different functional forms: year has a roughly linear upward trend, age shows a non-monotonic curve peaking in mid-career years, and education shows discrete jumps between levels. Each function is learned from data while the additive structure keeps the model interpretable.
Generalized Additive Models (GAMs): Pros and Cons
✅ Pros:
Non-linear flexibility : Automatically learns smooth curves for each featureBetter predictions : Captures non-linear relationships without manual feature engineeringStill interpretable : Visualize each \(f_j(x_j)\) independentlyMaintains additivity : Easy to understand feature contributions
⚠️ Cons:
No interactions by default : Must explicitly add interaction termsComputationally expensive : Finding all pairwise interactions is infeasible with many featuresHarder to explain : Shape functions less intuitive than linear coefficientsOverfitting risk : Requires careful smoothness tuning
GAMs balance flexibility and interpretability nicely - more expressive than linear models but still visualizable. But the no-interaction constraint can be limiting. If temperature and humidity interact to affect outcomes (e.g., heat index), a pure GAM will miss this synergistic effect and may underfit.
Explainable Boosting Machines
\[\begin{equation}
g(\mathbb{E}[y]) = \beta_0 + \sum f_j(x_j)
\end{equation}\]
\[\begin{equation}
g(\mathbb{E}[y]) = \beta_0 + \sum f_j(x_j) + \sum f_{ij}(x_i, x_j)
\end{equation}\]
What if we have a lot of interactions? How do we choose our interactions?
Automatically selecting which interactions to include is an active research area. EBMs use gradient boosting to greedily select the most important pairwise interactions during training. The boosting process alternates between improving main effects and interactions, naturally prioritizing the most impactful terms.
Explainable Boosting Machines
VIDEO
This video from Microsoft Research demonstrates the InterpretML library and EBMs in action. Watch how the system automatically discovers important feature interactions and visualizes their effects on predictions using partial dependence plots and interaction heatmaps.
Partial Dependence Plots (PDPs)
What PDPs show: The marginal effect of a feature on the predicted outcome
Mathematical idea: Average the model’s predictions across all data points while varying one feature
Y-axis : Change in prediction (relative to baseline)X-axis : Feature valuesCurve shape : Reveals linear, monotonic, or complex relationships (U-shaped in example)
PDPs marginalize the model output over the distribution of other features. For each value of feature X, we compute predictions for all data points with X set to that value, then average those predictions. This shows the average effect of X on predictions. The curve reveals whether the relationship is linear (straight line), monotonic (always increasing/decreasing), or more complex with peaks and valleys.
PDPs: Advantages and Limitations
✅ Advantages:
Intuitive : Easy to understand and explainModel-agnostic : Works with any modelCausal hints : Suggests feature importanceShows shape : Reveals non-linear patterns
⚠️ Limitations:
Independence assumption : Assumes features are independent (often violated!)Averages hide details : Misses heterogeneous effectsUnrealistic combinations : May average over impossible feature valuesMax 2 features : Can’t visualize high-dimensional interactions
The independence assumption is critical: PDPs assume you can vary one feature while holding others at their marginal distribution. But if features are correlated (e.g., house size and number of rooms), the PDP may average over unrealistic combinations. For example, it might average predictions for “1000 sq ft with 10 bedrooms” which doesn’t exist in reality. ICE plots (coming next) help reveal when PDPs are misleading by showing individual trajectories instead of averages.
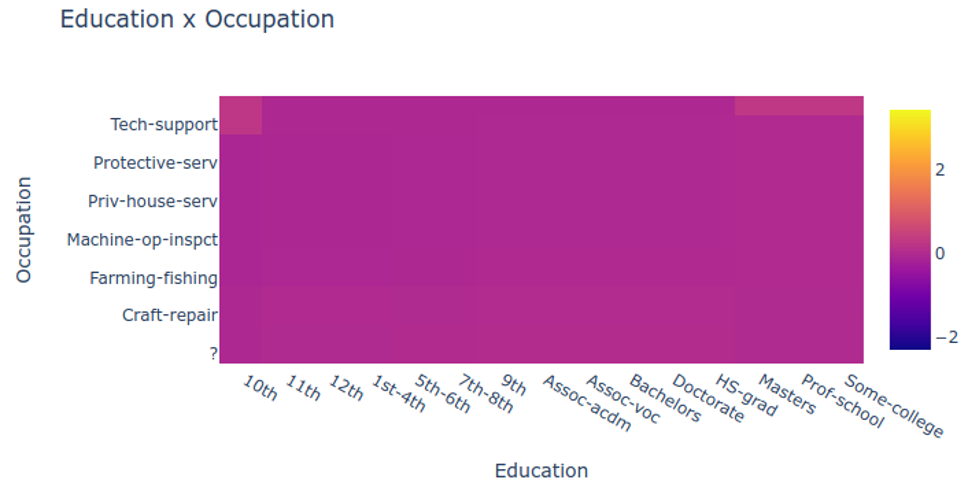
Visualizing EBMs (or GAMs)
Partial dependency plot
This PDP shows how predictions change as we vary one feature while marginalizing over all others. The y-axis shows the average prediction change from the baseline, making it easy to see each feature’s isolated effect. The rug plot at bottom shows the distribution of actual feature values - always check this to ensure you’re not extrapolating beyond the data.
Visualizing EBMs (or GAMs)
Partial dependency plot
Here we see multiple partial dependence plots arranged in a dashboard layout. This allows comparing the relative importance and functional forms of different features at a glance. Features with flat lines have little effect, while steep curves indicate strong influence on predictions.
Visualizing EBMs (or GAMs)
Partial dependency plot
This shows a 2D partial dependence plot for an interaction term between two features. The heatmap reveals how the two features jointly affect predictions, capturing synergistic effects that 1D plots would miss. Darker regions indicate combinations that strongly influence predictions.
Visualizing EBMs (or GAMs)
Partial dependency plot
Individual Conditional Expectation (ICE) plots show how predictions change for individual instances rather than averaging across the dataset. Each line represents one data point. This reveals heterogeneity - different instances may respond differently to the same feature change, suggesting important interactions or subpopulations.
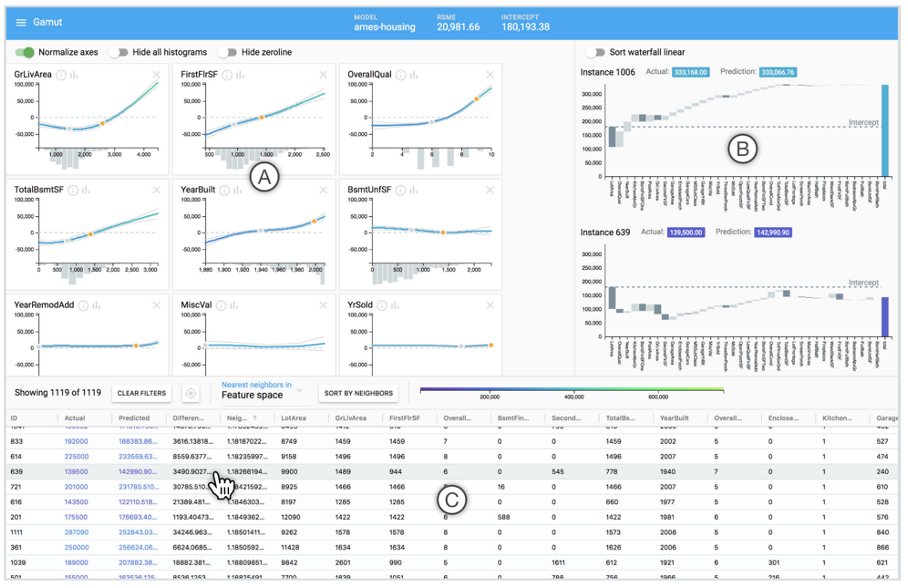
Visual Analytics (VA) Systems Using GAMs
GAMUT from Microsoft Research explores how data scientists interact with GAM visualizations through a design probe study. The system shows individual feature contributions for each observation, helping users understand both global patterns (overall feature effects) and local predictions (why this specific instance got this prediction). The research revealed that interpretability is not monolithic - data scientists have different reasons to interpret models and tailor explanations for specific audiences.
Visual Analytics (VA) Systems Using GAMs
This slide from Steven Drucker’s Microsoft Research presentation shows a GAM visualization system with multiple coordinated views, including partial dependence plots for understanding feature effects, residual analysis for identifying model weaknesses, and instance-level explanations. Interactive brushing and linking allows users to select interesting subgroups and explore their characteristics. Drucker leads Microsoft’s Visualization and Data Analysis Group (VIDA).
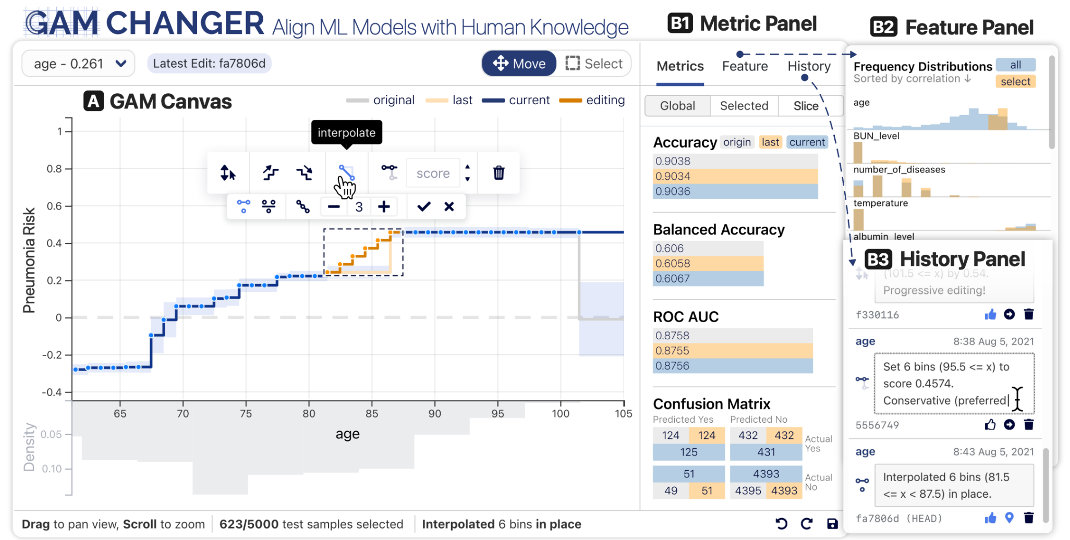
GAM Changer: Injecting Domain Knowledge via Interactive Editing
Human-in-the-Loop Features:
Edit shape functions to encode domain knowledgeEnforce monotonicity where business logic requiresSmooth noisy patterns to improve generalizationReal-time feedback on model performance
Key Innovation: Bridges data-driven learning with expert knowledge through interactive visualization
GAM Changer exemplifies the human-in-the-loop paradigm for model development. Users can interactively edit learned shape functions to inject domain knowledge - for example, enforcing that credit risk must monotonically increase with debt-to-income ratio, even if the data suggests otherwise due to sampling bias. Data scientists can manually adjust function shapes while seeing real-time impacts on model performance metrics. This approach is crucial when you need models that are not just accurate but also align with business logic and regulatory requirements. The tool runs locally in computational notebooks or browsers without requiring extra compute resources.
Decision Trees: How They Work
Decision trees recursively split data based on feature thresholds:
Internal nodes : Tests on featuresBranches : Test outcomes (Yes/No)Leaf nodes : Final predictionsAlgorithm : CART
Prediction : Follow path from root to leaf
Example: 3 splits, 4 leaves, depth 2
Decision trees work by recursively partitioning the feature space. At each internal node, the algorithm chooses a feature and threshold that best splits the data (measured by Gini impurity for classification or variance reduction for regression). This creates a hierarchical structure where each path represents a decision rule. To make a prediction, follow the decision path from root to leaf based on the instance’s feature values.
Decision Trees: Interpretation
Reading a tree : “If feature \(x_j\) is [smaller/larger] than threshold \(c\) AND … then predict \(\hat{y}\) ”
✅ Strengths:
Natural interactions : Captures feature interactions automaticallyVisual logic : Clear decision rulesNo preprocessing : Works with raw featuresHuman-friendly : Mimics human reasoning
⚠️ Limitations:
Linear relationships : Poor at modeling smooth trendsHigh variance/instability : Small data changes → different treeDepth problem : Deep trees become uninterpretableStep functions : Predictions jump at thresholds
→ This instability motivates ensemble methods (Random Forests, Gradient Boosting) which average many trees
Trade-off: Ensembles gain accuracy but lose white-box interpretability → Need for global surrogates (discussed later)
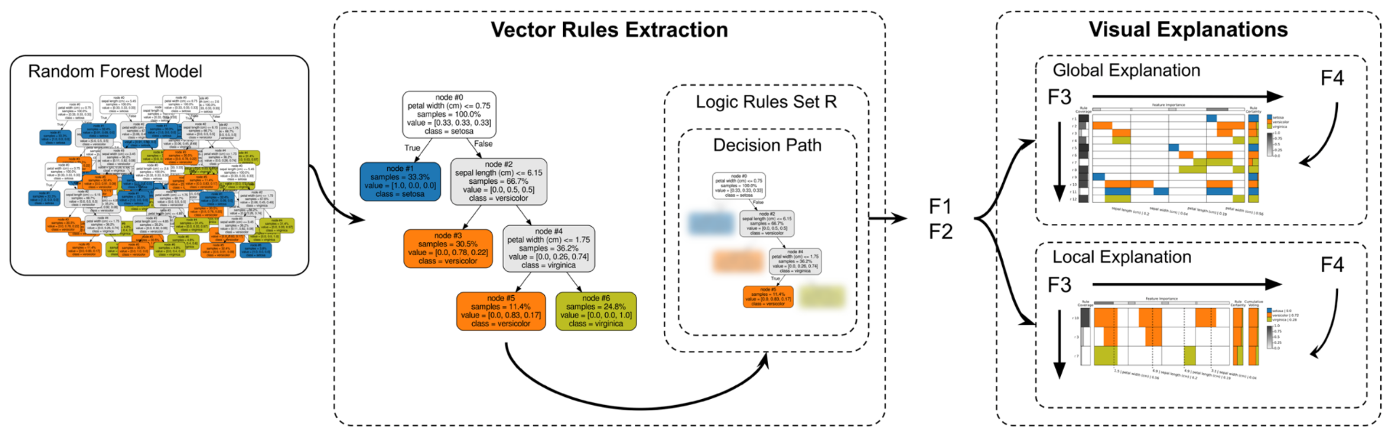
The key limitation of decision trees is their instability (high variance) - small changes in training data can produce completely different tree structures. This motivated the development of ensemble methods like Random Forests and Gradient Boosting, which average predictions from hundreds of trees to reduce variance and improve accuracy. However, this comes at a major cost: we lose the white-box interpretability of individual trees. You can’t meaningfully inspect 500 trees! This trade-off between accuracy and interpretability is why we need techniques like global surrogate models (discussed later) to explain ensemble predictions.
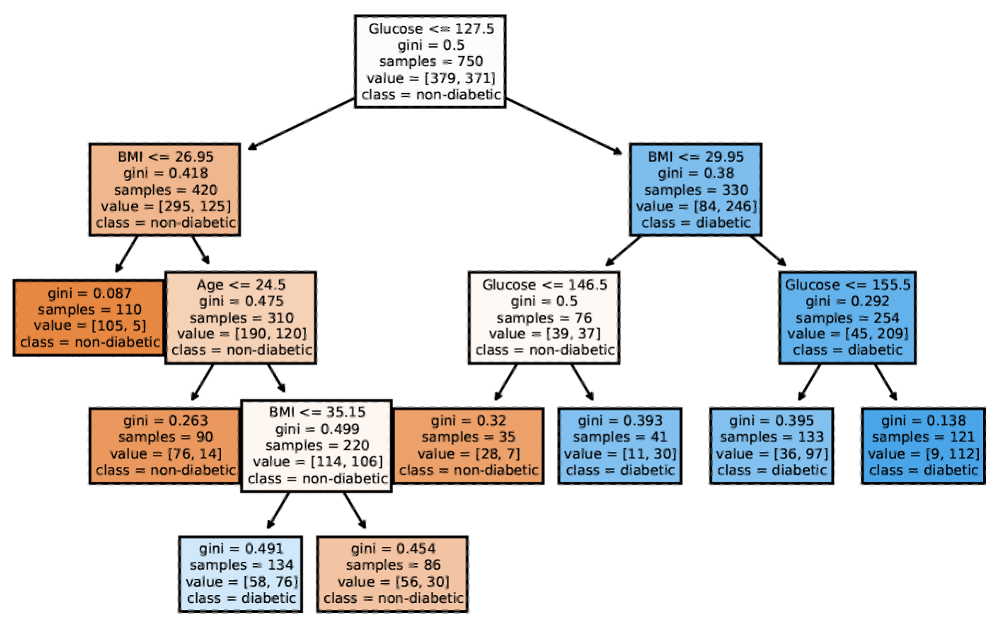
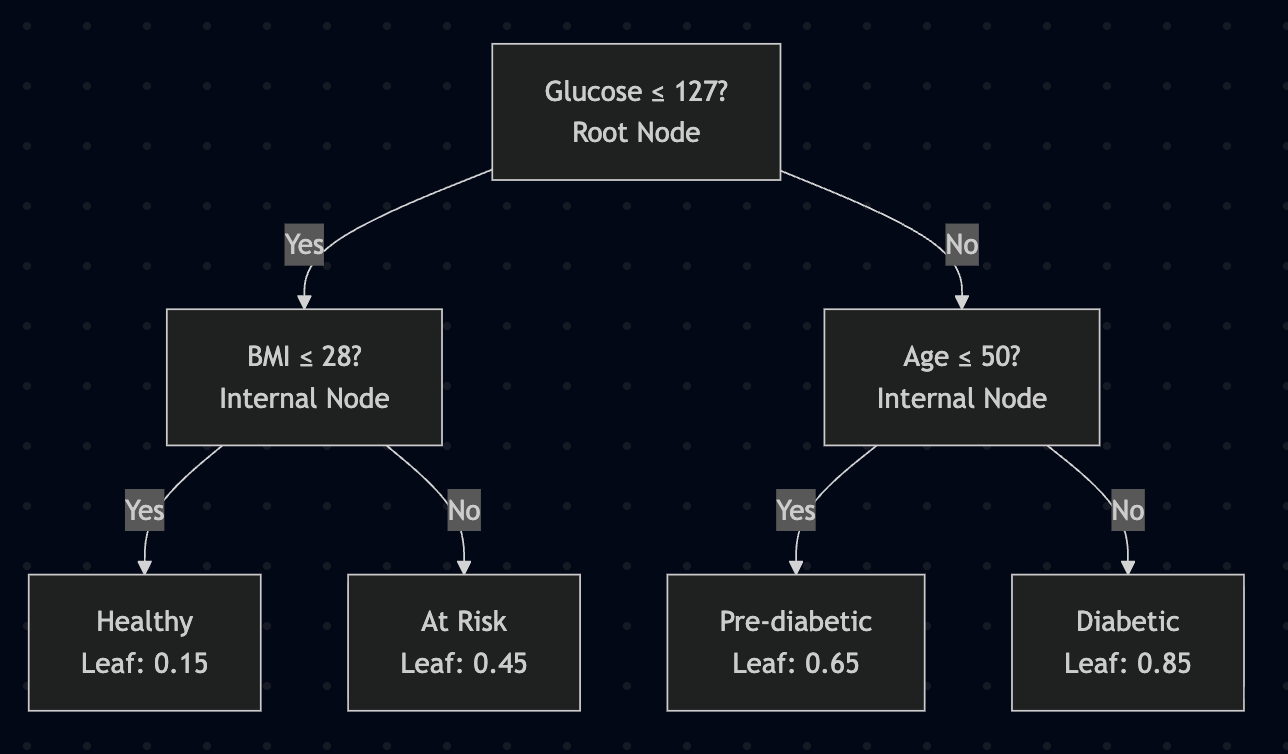
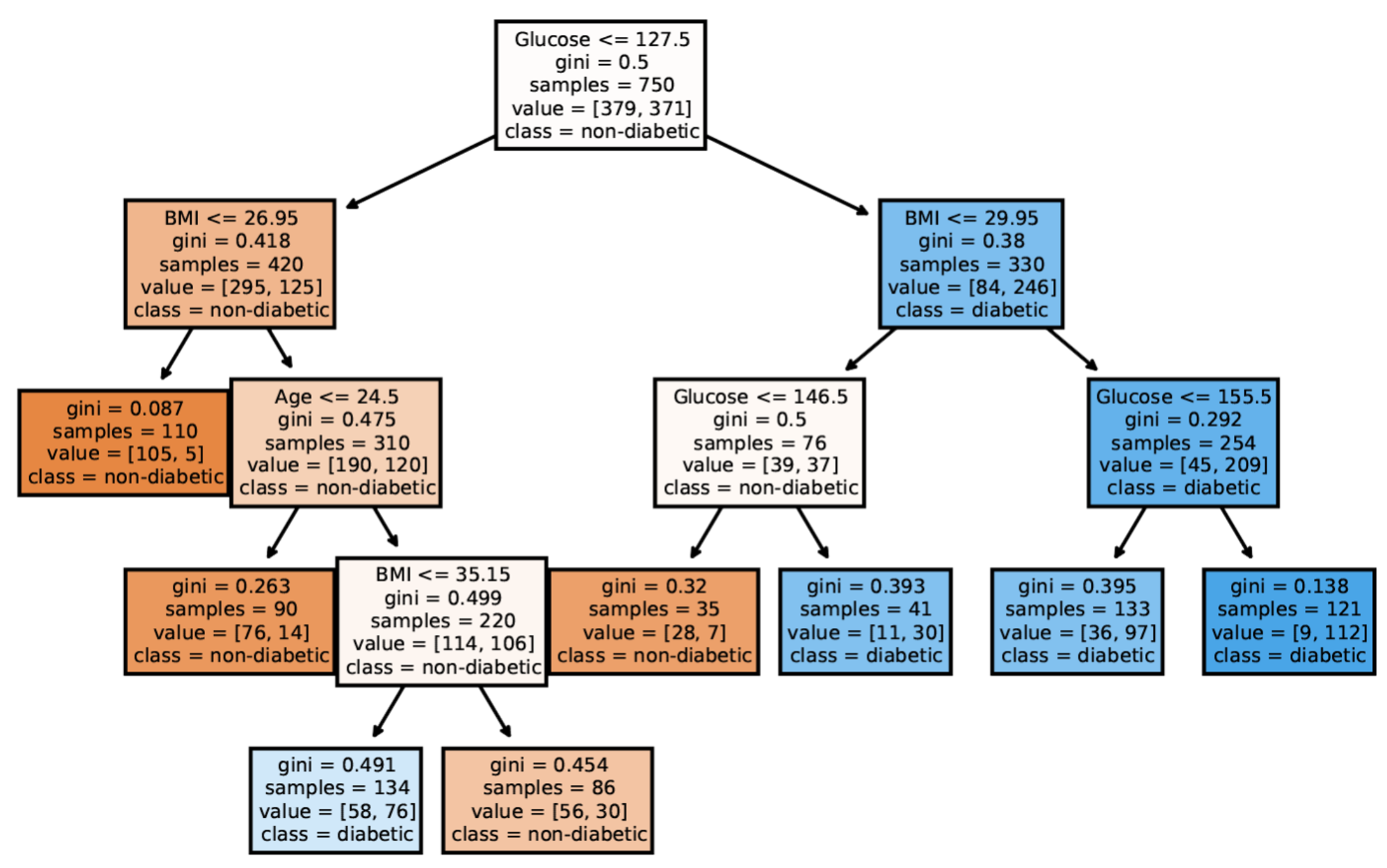
Tree-based Models: Example
A decision tree of diabetes diagnosis
This diabetes diagnosis tree demonstrates decision tree structure in practice. Each path from root to leaf represents a decision rule with explicit conditions. The tree shows how glucose level, BMI, age, and other factors combine hierarchically to predict disease risk. Notice how the tree naturally captures interactions - the same glucose threshold might have different meanings depending on BMI. Trees are highly interpretable when shallow like this, but can become unwieldy when deep.
VA Systems Using Tree-based Models
It shows the flow of different class, and the class distribution along the feature values.
BaobabView (van den Elzen & van Wijk, VAST 2011) uses a custom layout optimized for classification trees. The width of edges encodes the number of instances flowing through each branch, and color shows class distribution at each node. This makes it easy to see where the model is confident vs uncertain, and which features do the most splitting work. The system allows interactive construction and analysis of decision trees.
VA Systems Using Tree-based Models
iForest
iForest (Zhao et al., IEEE TVCG 2019) visualizes random forest ensembles rather than individual trees. The system aggregates predictions across trees to show which regions of feature space have high consensus vs disagreement among ensemble members. Areas of disagreement may indicate decision boundaries, noisy data, or underspecified regions where the model is uncertain. This addresses the key interpretability challenge with random forests - understanding the collective behavior of many trees.
Interactive Construction and Analysis of Decision Trees
Novel node-link visualization for very large decision trees
Interactive construction: users can split nodes, prune branches
Multiple views: overview, detail, rules
Elzen and van Wijk’s VAST 2011 paper presents an interactive system for constructing and analyzing decision trees. The visualization uses a novel compact layout that can display very large trees. Users can interactively split nodes, prune branches, and explore different tree configurations. The system combines overview, detail, and rule extraction views.
Interactive Construction: Video Demonstration
This video demonstrates the interactive capabilities of the Elzen & van Wijk system. Watch how users can interactively construct decision trees, explore different splits, prune branches, and analyze the resulting tree structure. The system provides real-time feedback on tree performance as users make modifications.
Interactive Construction: Colored Flow Visualization
Decision paths colored by class and features
This view shows decision paths colored by class labels (e.g., neck=no, lung, breast, bone=no). The flow visualization makes it easy to trace how different classes are separated through the tree. Width encodes the number of instances following each path. This design helps identify which features are most discriminative for each class.
Interactive Construction: Rule Visualization
Decision rules with feature splits
This view shows the explicit decision rules at each node (e.g., y-bar ≤ 9.00, x2ybr > 2.00). The rainbow coloring helps distinguish different paths through the tree. Users can see the complete rule set from root to any leaf, making it easy to extract interpretable decision rules from the trained tree.
Decision Rules: What Are They?
Definition: A decision rule is a simple IF-THEN statement consisting of a condition (antecedent) and a prediction (consequent).
Structure : IF (condition) THEN (prediction)Example : IF glucose > 120 AND age > 50 THEN diabetes_risk = highNatural language : Rules mirror human decision-making processesSparse representation : Only relevant features appear in conditionsFast prediction : Simple logical evaluationTransparent : Each rule’s logic is fully exposedCompliance-ready : Rules can be directly translated into legal/regulatory documentation
Decision rules represent one of the most interpretable forms of machine learning models. They directly mirror human decision-making processes by explicitly stating conditions and outcomes. This makes them particularly valuable in domains where transparency and explainability are crucial, such as healthcare, finance, and legal applications.
Key Difference: Trees vs. Rule Systems
Decision Trees:
Mutually Exclusive : Each instance follows exactly one pathNo conflicts : Instance reaches exactly one leafHierarchical : Rules are ordered by tree structureExample : A patient is either “high risk” OR “low risk”, never both
Rule Systems:
Not Mutually Exclusive : Instance can match multiple rulesConflict resolution needed : Voting, priority, or confidence-basedFlat structure : Rules can be evaluated in any orderExample : A loan can trigger both “high income” AND “high debt” rules
Implication: Rule systems need strategies to handle overlapping rules (majority vote, highest confidence, first match)
This is a fundamental distinction often overlooked. In decision trees, the hierarchical structure guarantees mutual exclusivity - you can’t be in two leaves simultaneously. Rule systems allow multiple rules to fire for the same instance, which can be more flexible but requires conflict resolution. Common strategies include: majority voting (classification), weighted average (regression), or priority ordering (first matching rule wins).
Decision Rules: Key Characteristics
Evaluation Metrics:
Support : Percentage of instances matching rule conditionsConfidence/Accuracy : Percentage of correct predictions when rule firesCoverage : How much of the dataset is explained by the rule set
Learning Approaches:
OneR : Selects single best feature, discretizes it, creates one rule per valueSequential Covering : Learns rules greedily - finds best rule, removes covered instances, repeatsBayesian Rule Lists : Pre-mines frequent patterns, uses Bayesian model selection for optimal orderingRIPPER : Fast rule learner with pruning to prevent overfitting
Support measures breadth - does the rule apply to many instances? Confidence measures precision - when the rule fires, is it usually correct? Good rules balance both metrics. Very specific rules (low support) may overfit, while very general rules (high support, low confidence) may be too simplistic. Sequential covering is the classic approach: learn one rule, remove the data it covers, repeat until all data is covered.
Decision Rules: Pros and Cons
✅ Strengths:
Easy to interpret : Natural language reasoningFast prediction : Simple logical checksRobust : Invariant to feature transformationsFeature selection : Automatically identifies relevant featuresHuman-aligned : Matches how experts explain decisions
⚠️ Limitations:
Regression challenges : Works best for classificationFeature discretization : Continuous features need binningLinear relationships : Hard to capture smooth trendsOverfitting risk : Complex rules may not generalizeRule conflicts : Overlapping rules need resolution
Decision rules excel when you need transparent, auditable models. They’re particularly valuable in regulated industries where you must explain each decision. However, they struggle with continuous relationships - you can’t easily express “price increases smoothly with size” as rules. The discretization required for continuous features can lose information and create artificial boundaries.
Decision Rules: Different Structures
The final decision is made based on a voting mechanism.
A recent user study shows that “if-then structure without any connecting else statements enables users to easily reason about the decision boundaries of classes.”
Rule lists have a clear priority ordering with if-then-else chains - rules are tried sequentially until one fires. Rule sets allow multiple rules to fire simultaneously and vote on the final decision. User studies show people find rule sets more intuitive because they don’t require mentally tracking a cascading else chain. Each rule stands independently.
Decision Rules: Different Structures
Disjunctive normal form (DNF, OR-of-ANDs) Conjunctive normal form (CNF, AND-of-ORs)
What form does this rule set follow?
This example shows DNF (Disjunctive Normal Form) rules: each rule is a conjunction (AND) of conditions, and we predict positive if ANY rule fires (OR). DNF is more common in ML because it naturally represents disjoint decision regions in feature space. CNF would require all conditions across rules to be met simultaneously, which is less useful for classification.
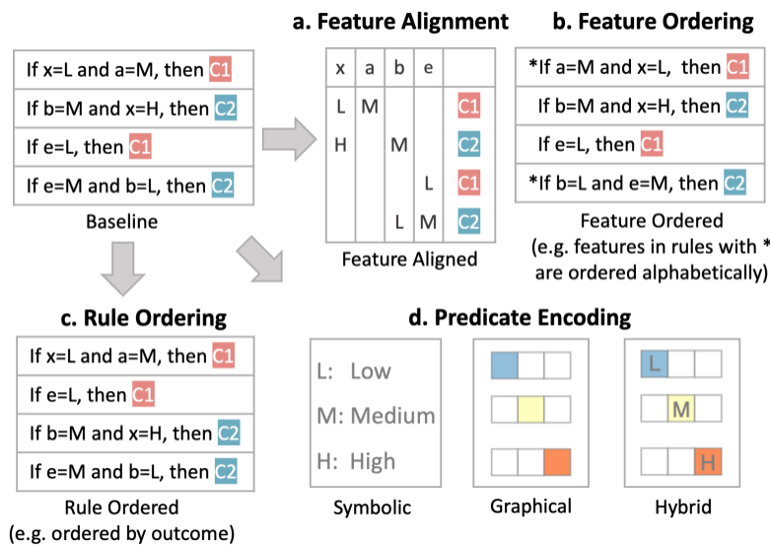
Decision Rules: Visual Factors Influence Rule Understanding
Research Questions:
Can different visualizations of rules lead to different levels of understanding?
What visual factors influence understanding and how do they affect rule comprehension?
Key findings: Visual encoding choices significantly impact interpretability
This research by Yuan et al. investigates how visual presentation affects rule comprehension. They found that factors like rule ordering, grouping, highlighting, and textual formatting all influence how quickly and accurately people understand rule-based models. Good visual design can make complex rule sets much more accessible to non-experts, while poor design obscures patterns. The study provides empirical evidence that visualization design matters as much as the underlying model for interpretability.
Evaluation of Rules
Given a rule below:
If \(X\) , then class \(Y\) .
Support / Coverage of a rule:
\[\begin{equation}
\text{Support} = \frac{\text{number of instances that match the conditions in } X}{\text{total number of instances}}
\end{equation}\]
Confidence / Accuracy of a rule:
\[\begin{equation}
\text{Confidence} = \frac{\text{number of instances that match conditions in } X \text{ and belong to class } Y}{\text{number of instances that match conditions in } X}
\end{equation}\]
Support measures how frequently the rule applies (what fraction of data it covers). Confidence measures how accurate the rule is when it fires (what fraction of covered instances are correctly classified). Good rules balance both - high confidence but very low support means the rule is too specific. High support but low confidence means it’s too general and inaccurate.
Global Surrogate
Imagine that we have a black-box model (too complex to understand the internal structure), can we use white-box models to help us understand the model behavior of the black-box model?
Global surrogate models approximate a complex black-box model with an interpretable white-box model. Train a decision tree or rule set to mimic the black-box’s predictions. This trades some accuracy for interpretability - you’re explaining the black-box’s behavior, not the underlying true relationship. Useful when you need interpretability but your best-performing model is opaque.
Global Surrogate
Open the black box by understanding a “surrogate model” that approximate the behavior of the original black-box model.
The surrogate training process: feed data through the black-box to get predictions, then train an interpretable model (decision tree, linear model, rules) to predict what the black-box would predict. The surrogate’s feature importances and structure reveal what the black-box learned. Check surrogate fidelity - how well does it match the black-box predictions?
The Fidelity-Interpretability Trade-off
The Fidelity-Interpretability Trade-off: A fundamental challenge in XAI where increasing model interpretability often decreases fidelity to the original model’s behavior
What you want:
Simple, interpretable surrogate with high fidelity to the black-box model
What you get:
Either low fidelity (simple but inaccurate) or low interpretability (accurate but complex)
This is the Fidelity-Interpretability Trade-off, a foundational problem in Explainable AI (XAI). You want a simple, interpretable surrogate that’s also highly faithful to the black-box model’s decisions. But there’s an inherent tension: simple surrogates miss important patterns (low fidelity), while high-fidelity surrogates become too complex to interpret. This trade-off appears throughout XAI - in global surrogates, local explanations (LIME/SHAP), and even in choosing between white-box and black-box models initially. Understanding this trade-off is crucial for setting realistic expectations about what explanations can achieve.
VA System for Rule List
RuleMatrix
RuleMatrix visualizes rule lists using a matrix layout where rows are rules and columns are features. Cell color/intensity shows feature values in each rule’s conditions. This compact representation lets you quickly scan for redundant rules, identify which features are most commonly used, and spot patterns across the rule set. Interactive features support rule refinement and editing.
VA Systems for Rules in Random Forest
Explainable Matrix
Explainable Matrix extends rule visualization to random forest ensembles. Each tree generates rules, and the system aggregates and visualizes rule consensus across the forest. Users can see which rules appear consistently vs which are unique to specific trees. This helps understand ensemble behavior and identify stable patterns that the forest relies on.
Other white-box models?
Naive Bayes
K-nearest neighbors
etc.
Beyond the models we’ve covered, other naturally interpretable models include: Naive Bayes (shows probability contributions from each feature via Bayes rule), K-Nearest Neighbors (predictions explained by showing similar training examples), and Logistic Regression (similar to linear regression but for classification). Each provides different forms of interpretability suited to different explanation needs.
Outline
Model Interpretation and Explanation White-box Approaches and Visualizations Related Research in VIS & AI
Manipulating and Measuring Model Interpretability
This paper asks fundamental questions: Can we quantitatively measure interpretability? Can we manipulate model structure to increase interpretability while maintaining performance? The authors propose metrics for tree complexity, sparsity, and other interpretability factors. This work is important because it moves interpretability from a vague concept to something measurable and optimizable.
Stop explaining black box machine learning models for high stakes decisions
Cynthia Rudin’s influential paper argues that for high-stakes decisions (healthcare, criminal justice, lending), we should use inherently interpretable models rather than explaining black-boxes post-hoc. Post-hoc explanations can be misleading, incomplete, or unfaithful to the model. Instead, invest effort in building accurate interpretable models from the start. This sparked important debates about the interpretability-accuracy tradeoff.
Slice Finder: Automated Data Slicing for Model Validation
How about we use whether the model prediction is wrong or not to train a “surrogate tree”?
Slice Finder uses a clever approach: train a decision tree to predict where your model makes errors. The tree splits identify data slices where performance degrades. This automates the manual process of searching for problematic subgroups. The resulting tree provides an interpretable description of failure modes - “the model struggles when age > 65 AND income < 30k”.
Toolkits
InterpretML: https://github.com/interpretml/interpret
InterpretML is Microsoft’s open-source library for interpretable machine learning. It implements GAMs, Explainable Boosting Machines (EBMs), and various explanation techniques. The library includes both glass-box models (inherently interpretable) and black-box explanation methods (LIME, SHAP). It provides unified APIs and visualization tools, making it easy to compare different interpretability approaches. Highly recommended for practical work.
Practice 1
Notebook: https://colab.research.google.com/drive/1nKE6WIApebHi67yfhH6k5mZN86evLZOM?usp=sharing
Some other libraries for PDP visualization: https://scikit-learn.org/stable/modules/partial_dependence.html https://interpret.ml/docs/pdp.html
This hands-on exercise walks through training GAMs with Python’s interpret library and creating partial dependence visualizations. You’ll explore how to identify non-linear patterns, detect feature interactions, and interpret model behavior through visualizations. Try comparing linear regression vs GAM on the same dataset.
Practice 2
Notebook: https://colab.research.google.com/drive/12LV2Z_1BbP3efACYp2QxzsPaOrIn8a8l?usp=sharing
This hands-on exercise covers decision tree training, visualization, and rule extraction with sklearn. You’ll experiment with tree depth, pruning strategies, and extracting interpretable rules from trained trees. Try comparing different tree visualization libraries and see how tree structure affects interpretability and performance.


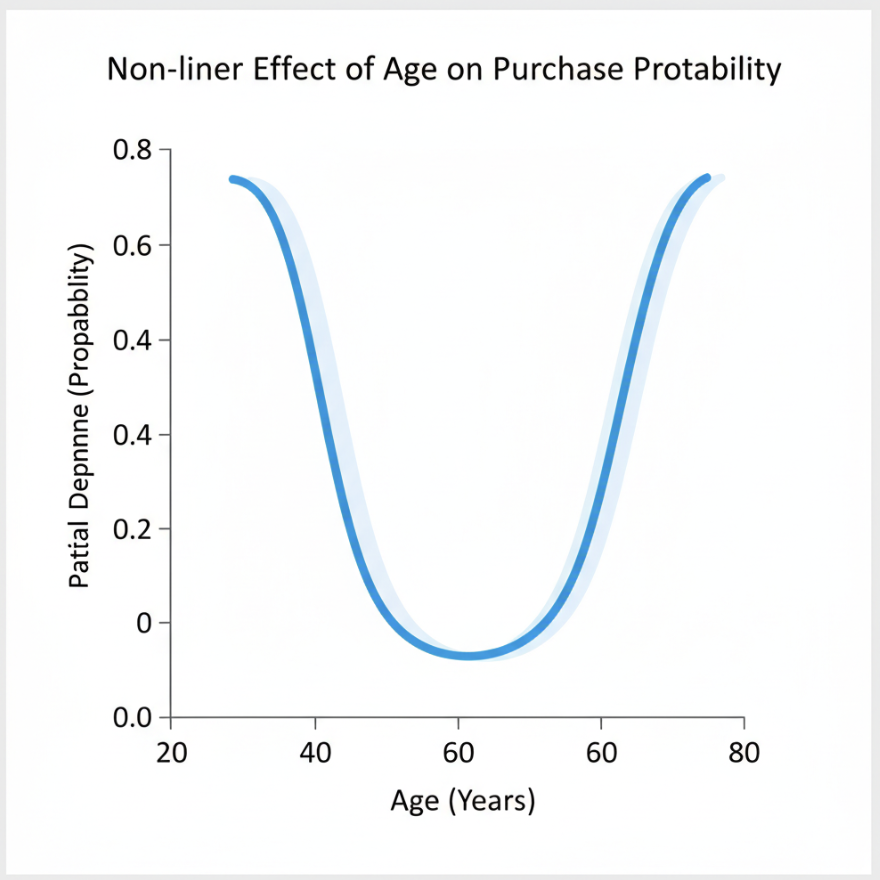
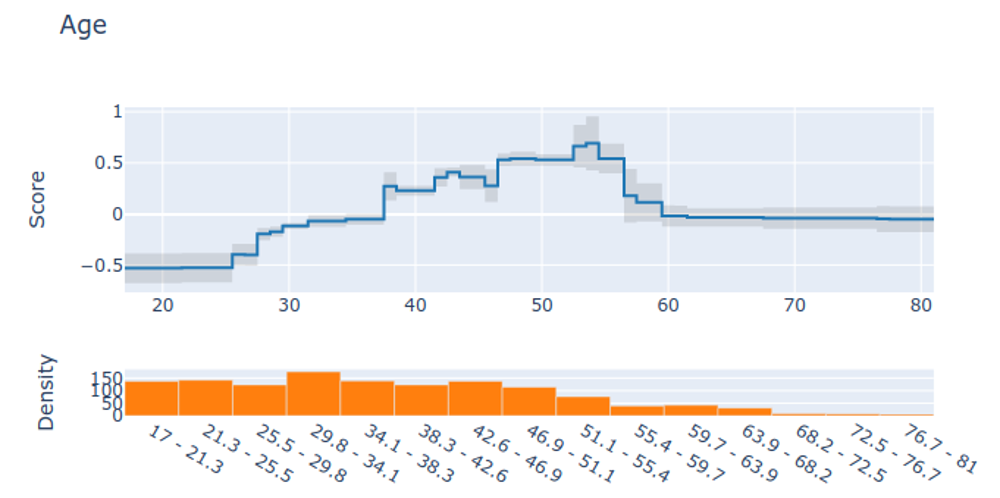
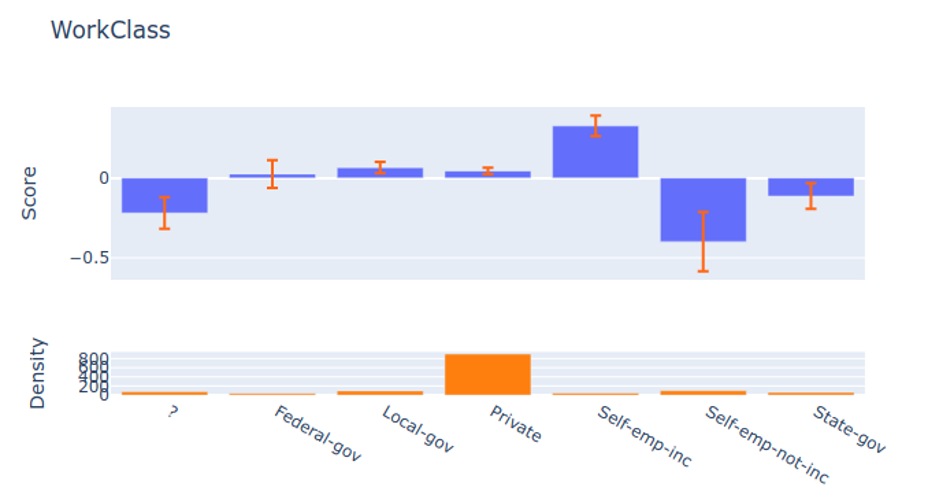
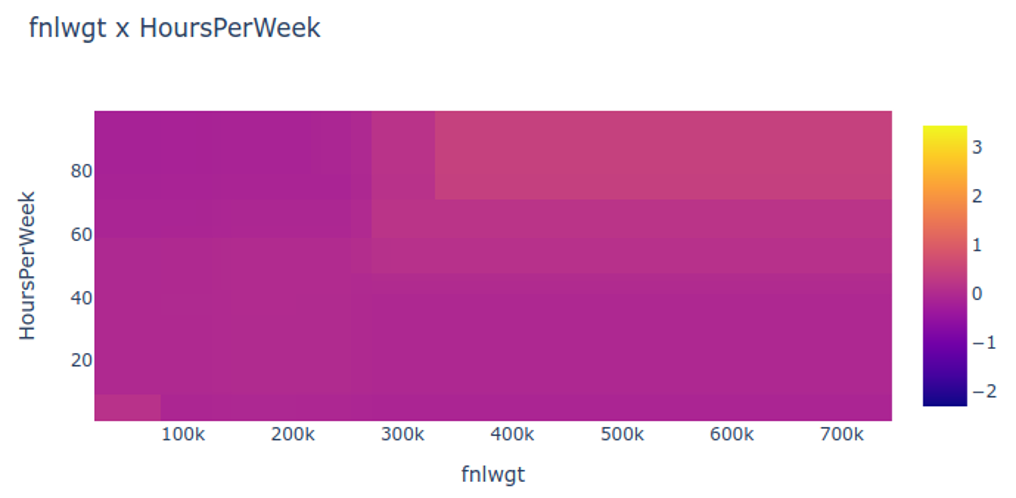

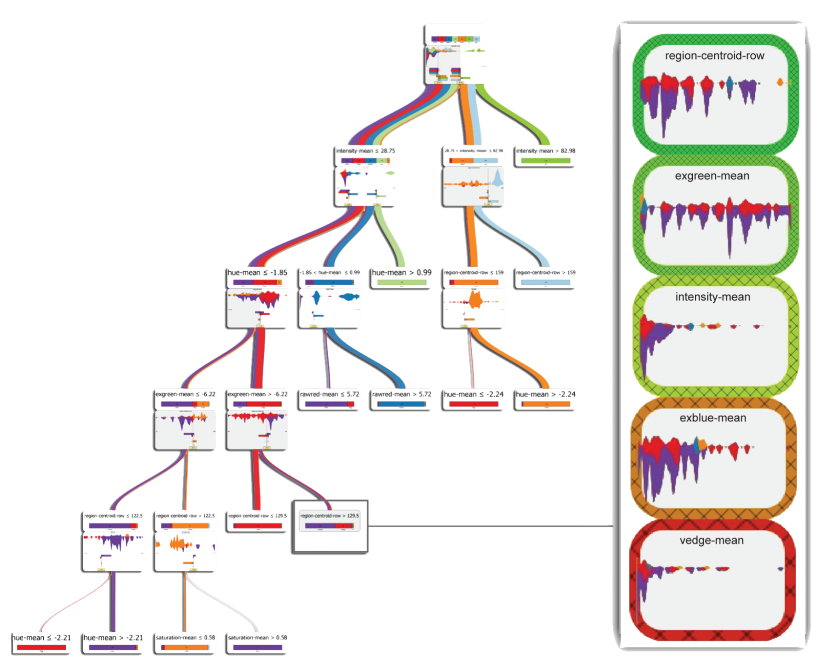
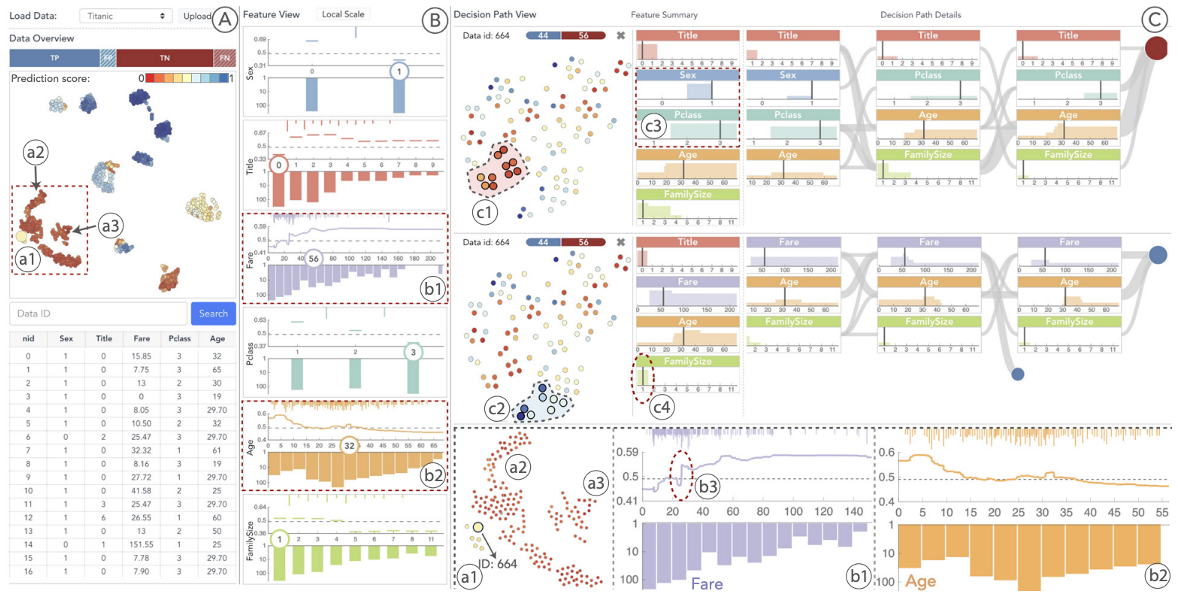
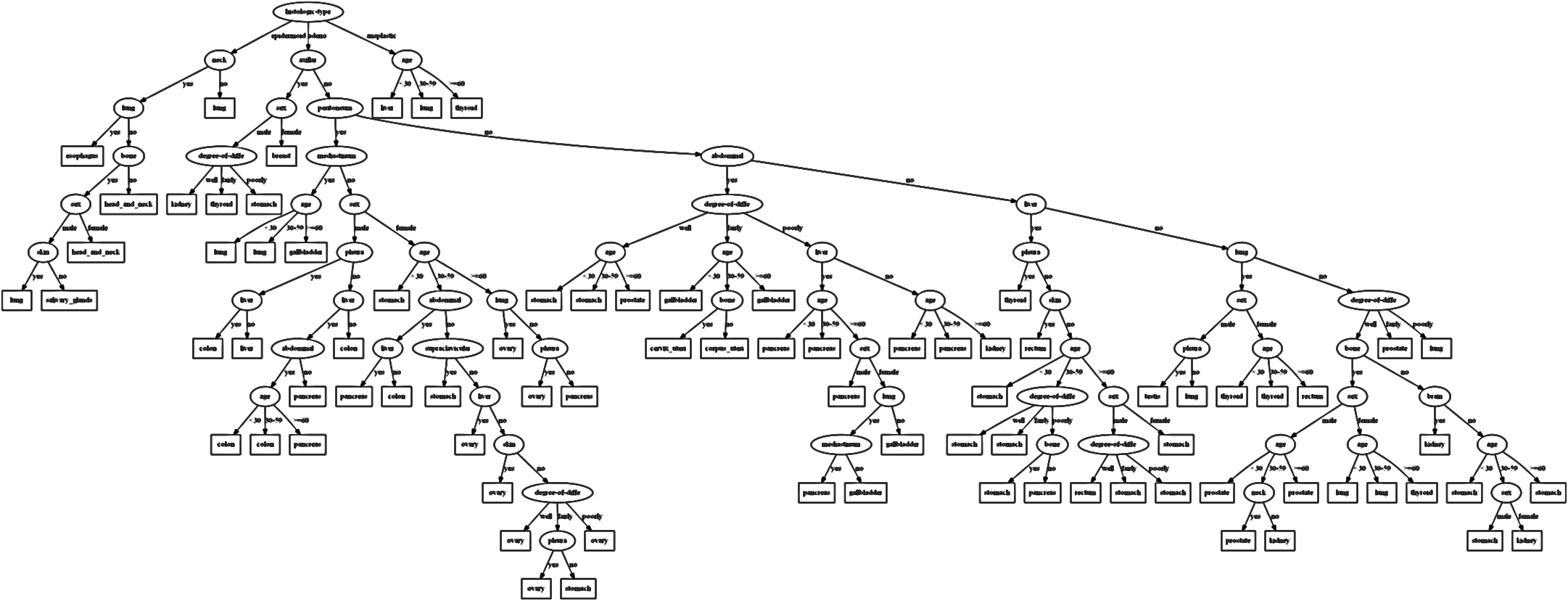
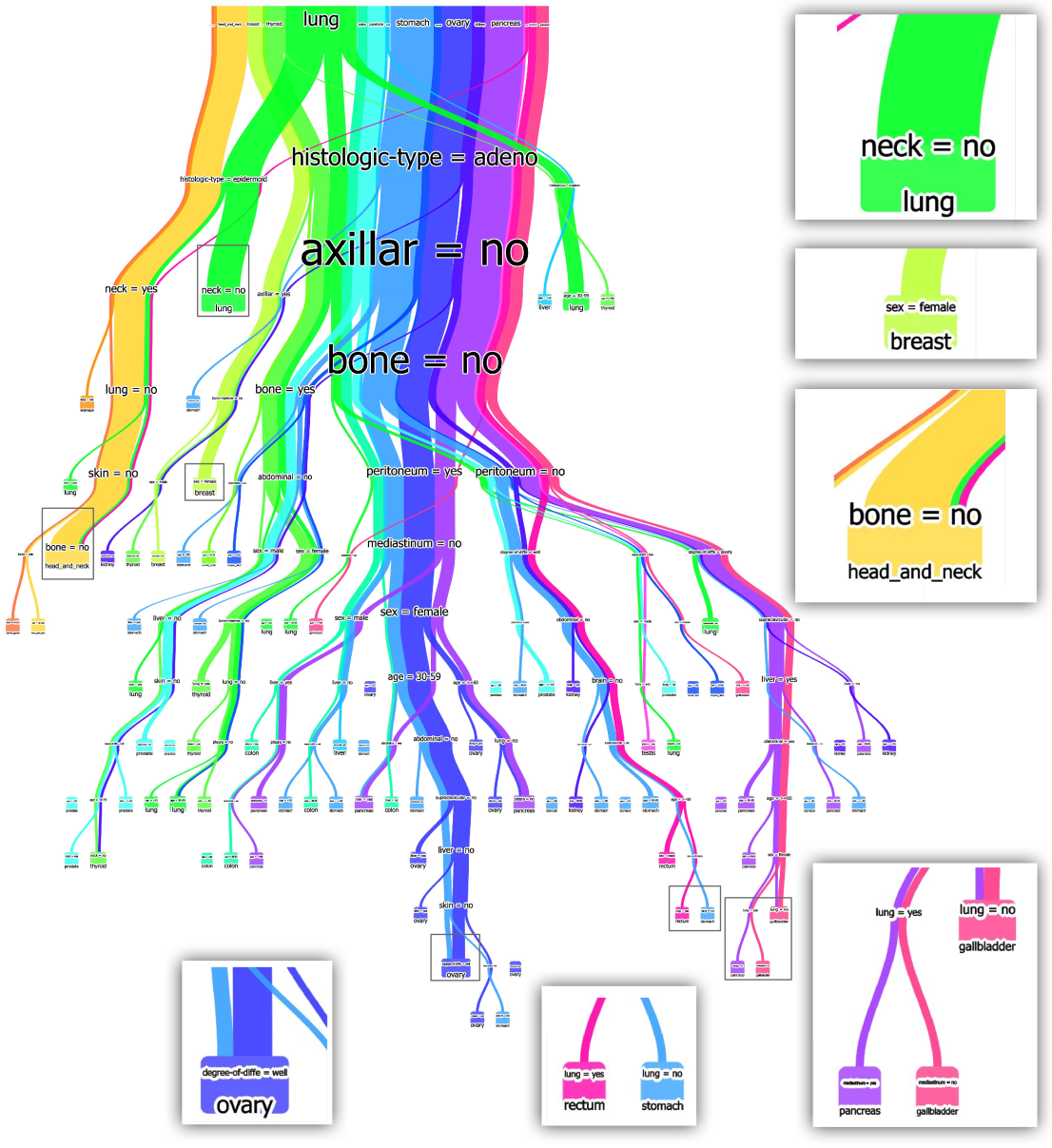
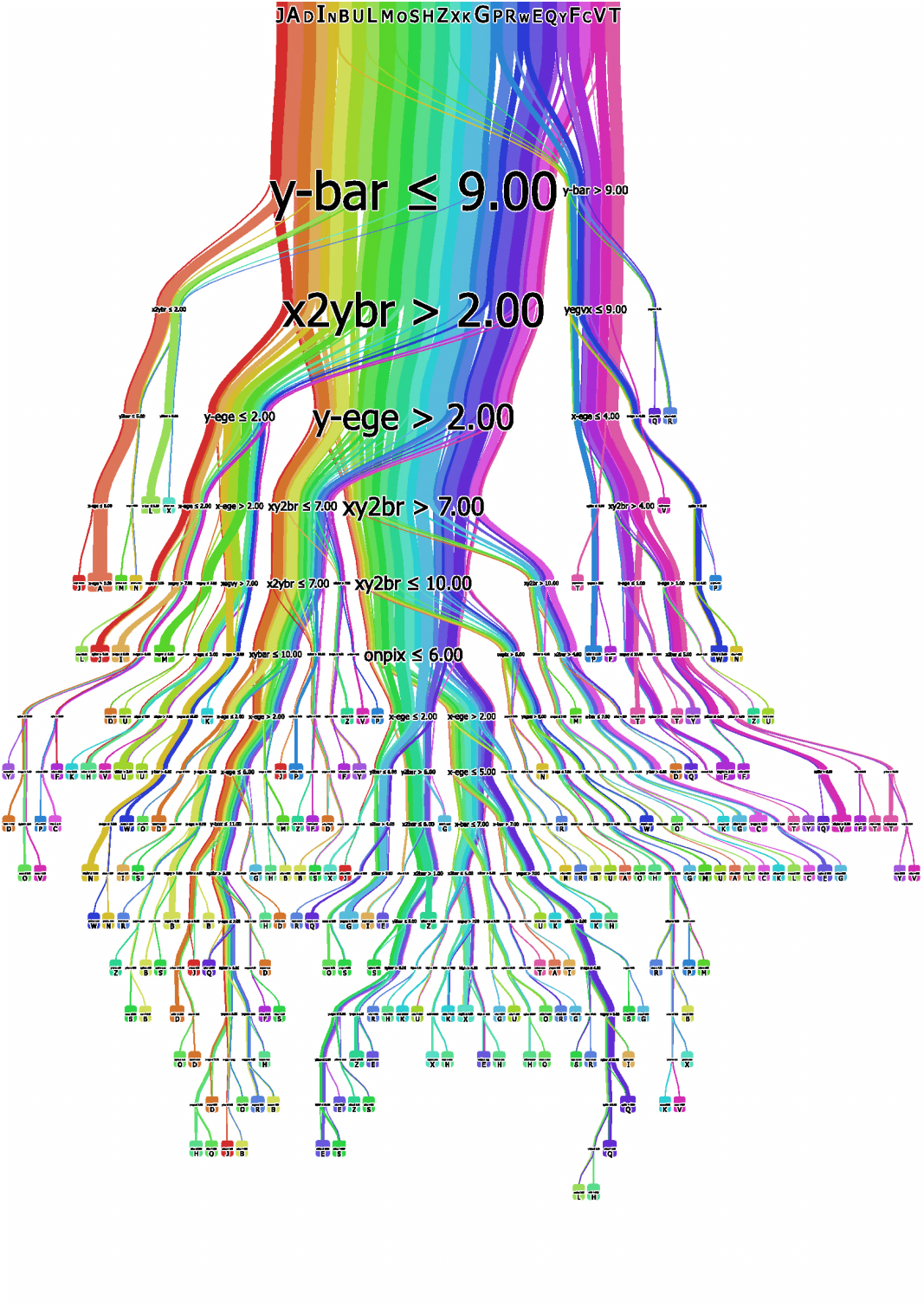
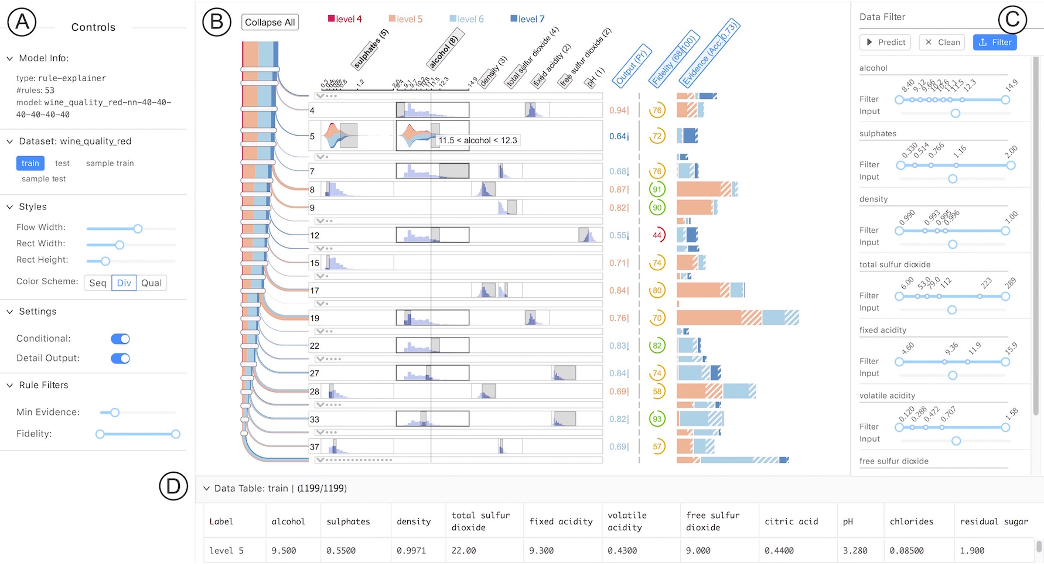
 Clearly see how the decision is made and which rule is more important.
Clearly see how the decision is made and which rule is more important.