This dataset contains daily counts of rented bicycles from the bicycle rental company Capital-Bikeshare in Washington D.C., along with weather and seasonal information. The goal is to predict how many bikes will be rented depending on the weather and the day. The data can be downloaded from the UCI Machine Learning Repository.
Here is the list of features used in Molnar’s book:
Count of bicycles including both casual and registered users. The count is used as the target in the regression task.
The season, either spring, summer, fall or winter.
Indicator whether the day was a holiday or not.
The year, either 2011 or 2012.
Number of days since the 01.01.2011 (the first day in the dataset). This feature was introduced to take account of the trend over time.
Indicator whether the day was a working day or weekend.
The weather situation on that day. One of: clear, few clouds, partly cloudy, cloudy mist + clouds, mist + broken clouds, mist + few clouds, mist light snow, light rain + thunderstorm + scattered clouds, light rain + scattered clouds heavy rain + ice pallets + thunderstorm + mist, snow + mist
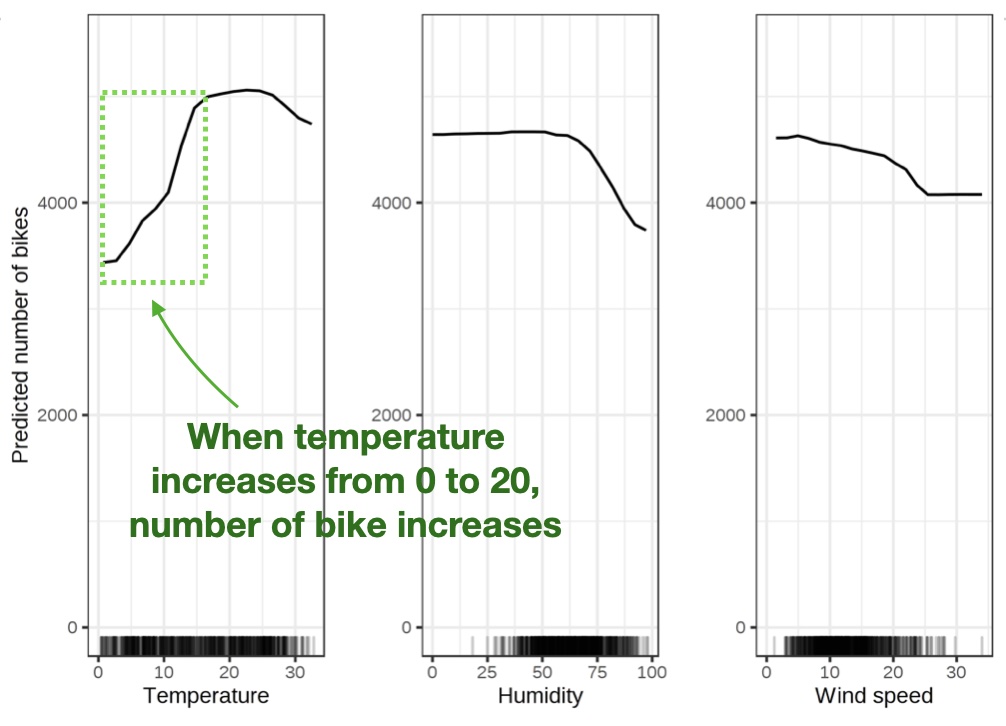
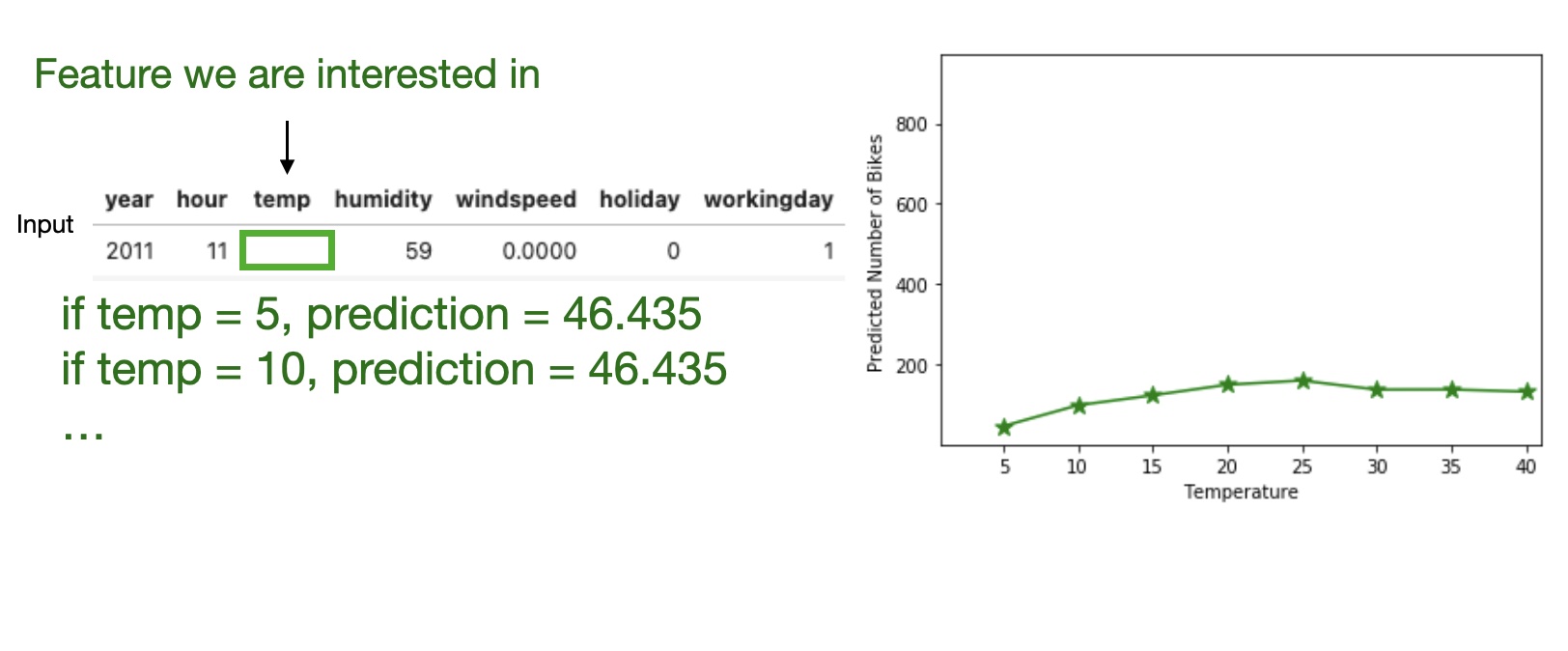
Temperature in degrees Celsius.
Relative humidity in percent (0 to 100).
Wind speed in km per hour.
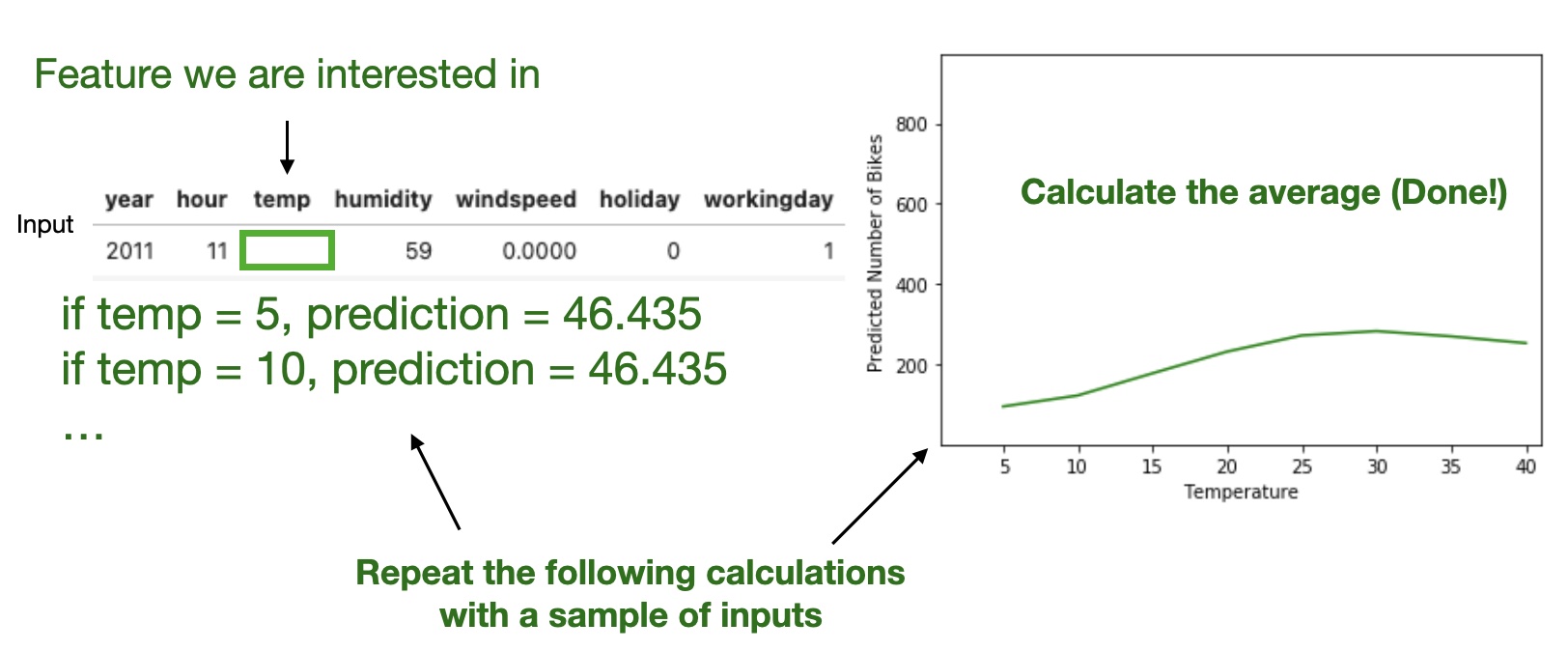
Partial Dependence Plot (PDP)
Shows the marginal effect one or two features have on the predicted outcome of a machine learning model (J. H. Friedman 2001).
1D PDP: Line plot showing effect of single feature
2D PDP (Interaction Plots):
For two features, PDP generates a heatmap showing interactions.
🟦🟦🟨🟧🟧 🟦🟦🟨🟧🟧 🟩🟩🟨🟨🟨 🟩🟩🟨🟨🟨
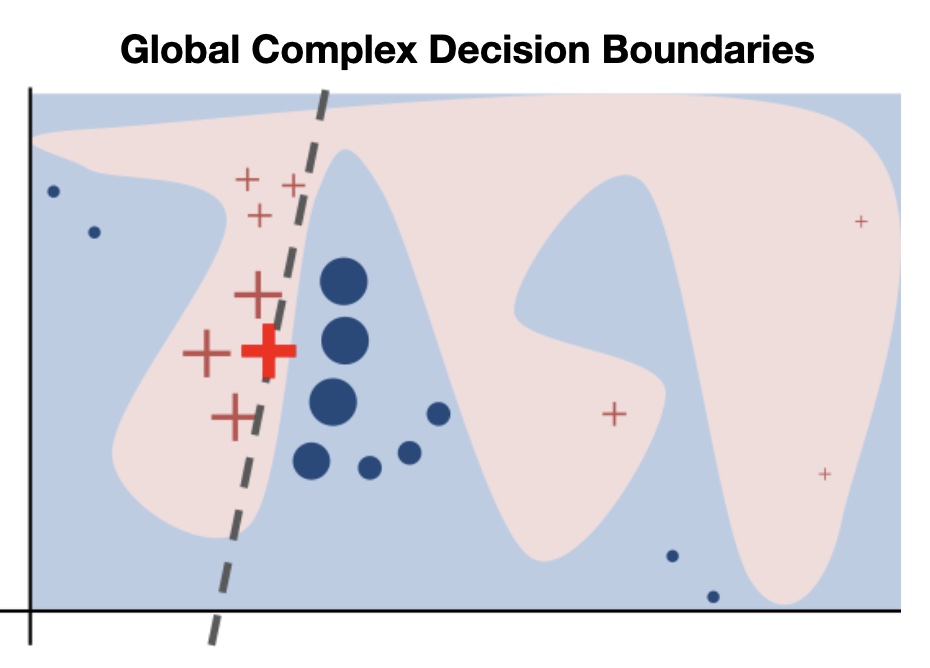
Complex contours = strong feature interaction
PDP Visualization: Interpreting Feature Effects
1. Monotonic/Linear
↗ ↗ ↗
Straight diagonal line
↑ Feature → ↑ Prediction
Feature has consistent positive (or negative) effect
2. Non-linear/Sweet Spot
╱‾╲ ╱ ╲ ╱ ╲
Curve peaks and drops
Optimal range exists
(like temperature example)
3. Flat Line
━━━━━━━
Horizontal line
No marginal effect
Feature is globally unimportant
Partial Dependence Plot (PDP)
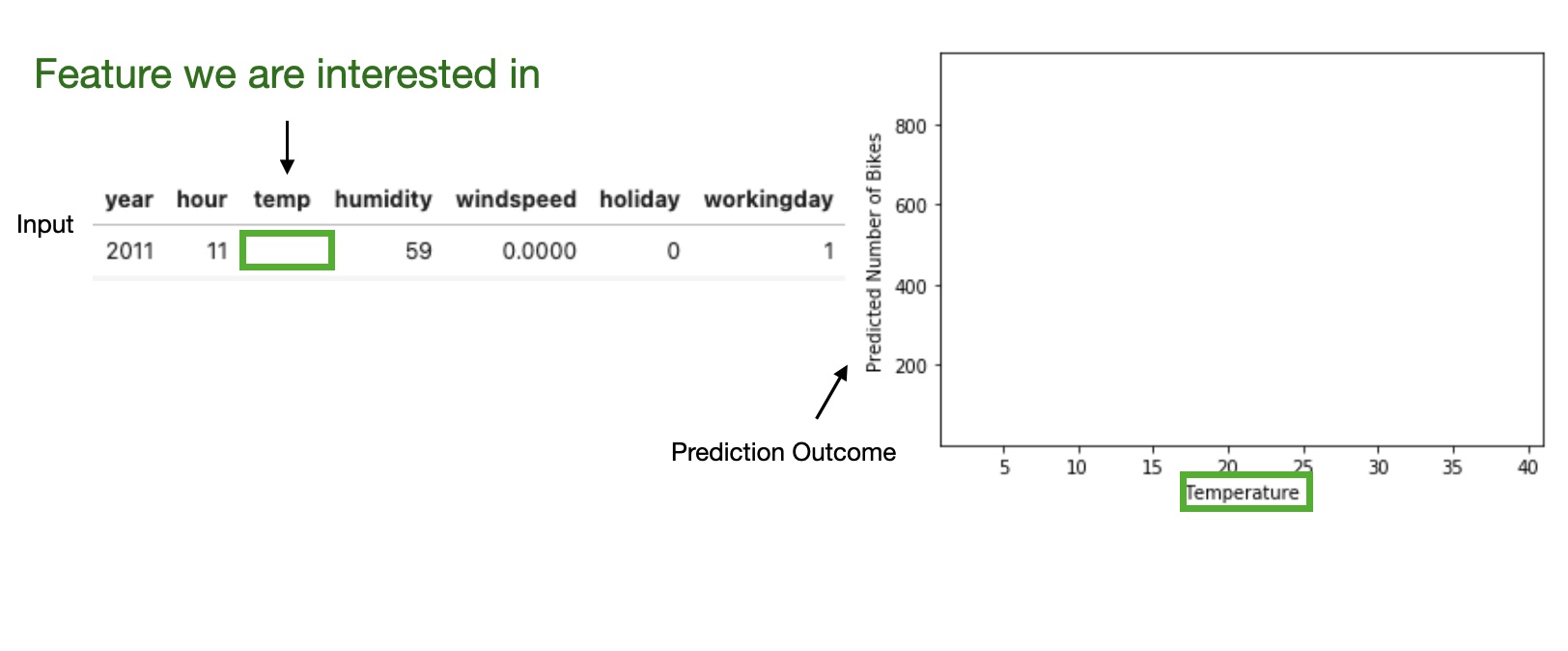
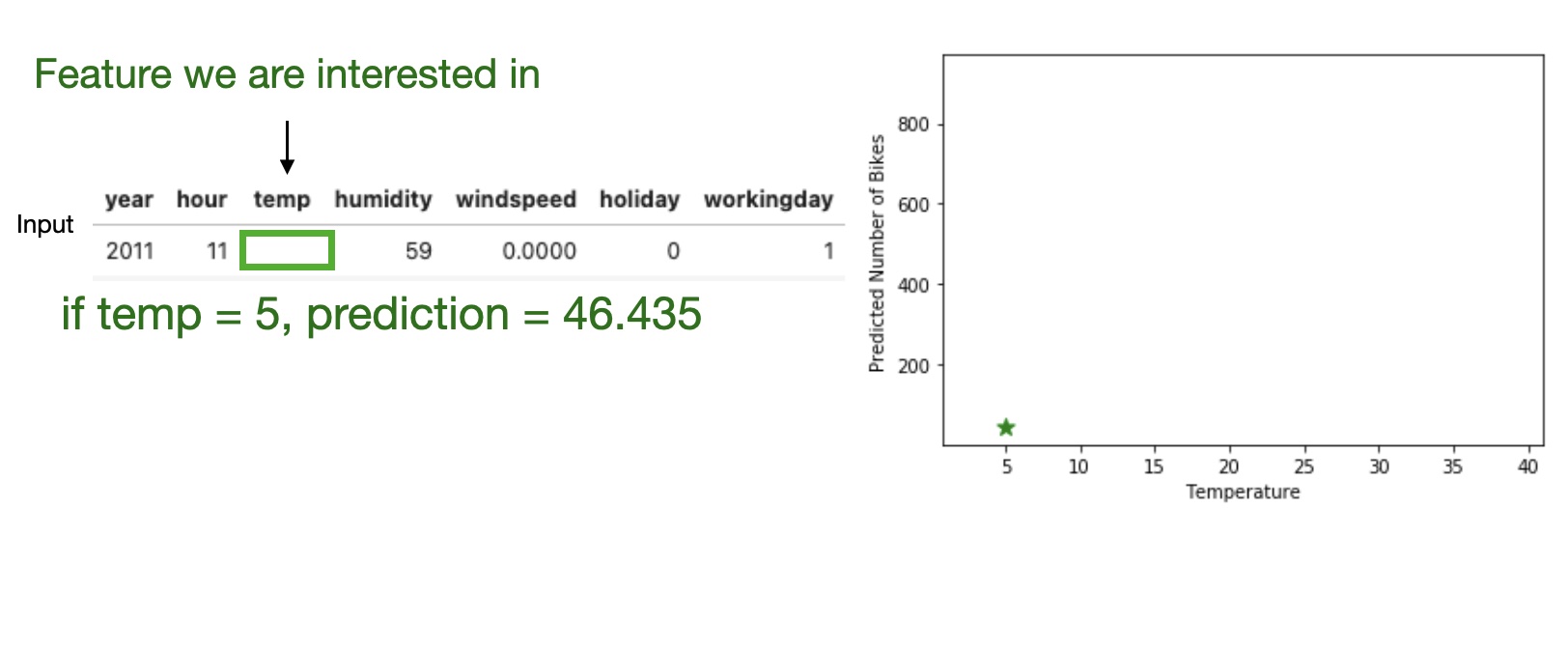
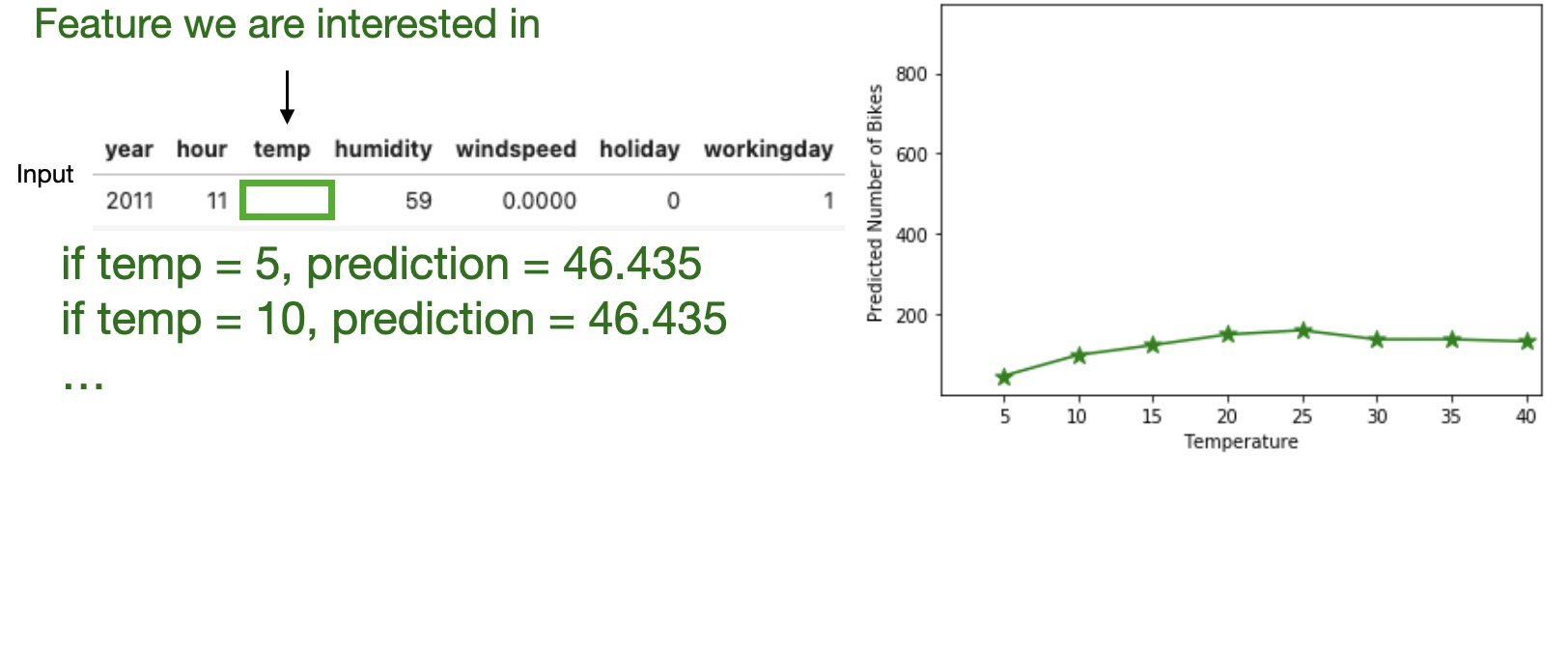
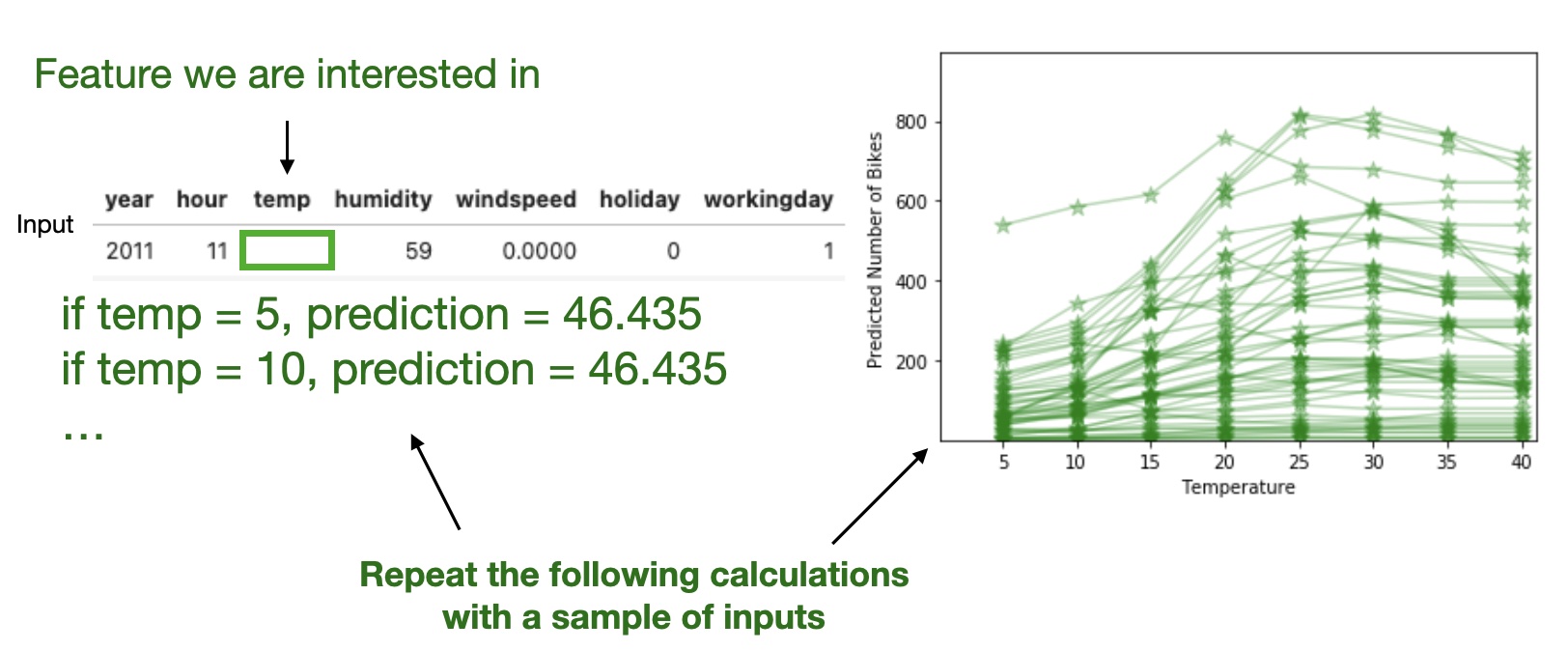
High level idea: marginalizing the machine learning model output over the distributions of the all other features to show the relationship between the feature we are interested in and the predicted outcome.
PDP: Code Example with scikit-learn
Dataset: California Housing - median house value prediction (8 features)
from sklearn.datasets import fetch_california_housingfrom sklearn.ensemble import GradientBoostingRegressorfrom sklearn.inspection import PartialDependenceDisplayimport matplotlib.pyplot as plt# Load California housing dataset# Features: median income, house age, average rooms, etc.housing = fetch_california_housing()X, y = housing.data, housing.target# Train a gradient boosting regressormodel = GradientBoostingRegressor( n_estimators=100, max_depth=4, learning_rate=0.1, random_state=0).fit(X, y)# Create PDPs for: MedInc (0), HouseAge (1), and their interaction# MedInc = median income, HouseAge = median house agefeatures = [0, 1, (0, 1)]display = PartialDependenceDisplay.from_estimator( model, X, features, feature_names=housing.feature_names)
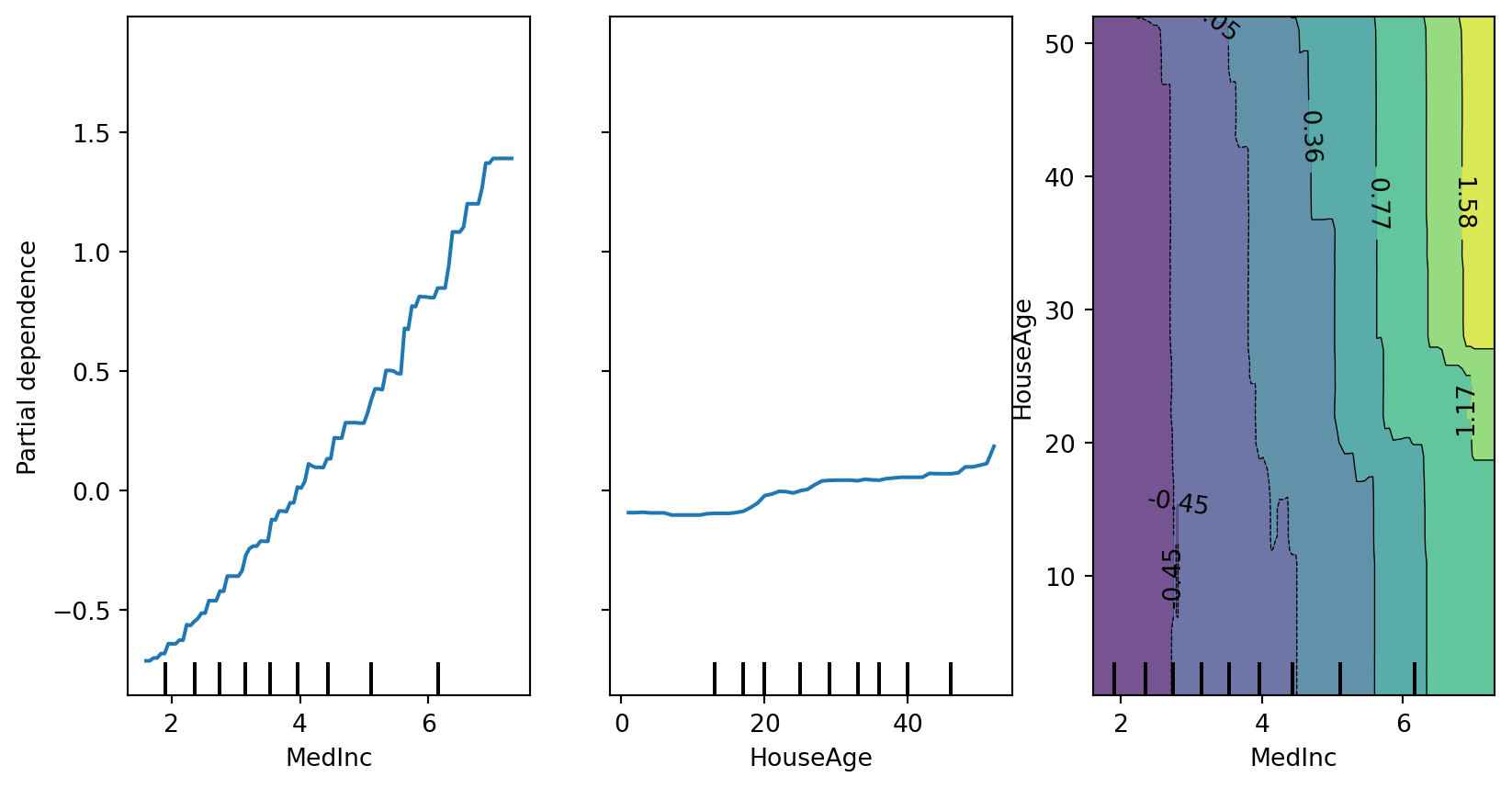
PDP: Output Visualization
Interpretation:
Left (MedInc): Strong positive monotonic relationship - higher median income → higher house prices (as expected)
Middle (HouseAge): Non-monotonic effect - newer and very old houses have lower values, middle-aged houses peak
Right (Interaction): Shows how income and age combine - high income dominates regardless of age (vertical gradient)
PDP shows the average effect across all instances.
But what if the effect differs between: - Cold days vs. warm days? - New customers vs. loyal customers? - Low-income vs. high-income applicants?
PDP cannot tell you!
The Solution:
Move from global to local explanations.
Instead of asking: > “How does temperature affect rentals on average?”
Ask: > “Why did the model predict this specific value for this particular day?”
→ Enter LIME
Local Interpretable Model-agnostic Explanations (LIME)
Training local surrogate models to explain individual predictions
Training local surrogate models to explain individual predictions
The idea is quite intuitive. First, forget about the training data and imagine you only have the black box model where you can input data points and get the predictions of the model. You can probe the box as often as you want. Your goal is to understand why the machine learning model made a certain prediction. LIME tests what happens to the predictions when you give variations of your data into the machine learning model.
LIME generates a new dataset consisting of perturbed samples and the corresponding predictions of the black box model.
On this new dataset LIME then trains an interpretable model, which is weighted by the proximity of the sampled instances to the instance of interest. The interpretable model can be anything from the interpretable models chapter, for example Lasso or a decision tree. The learned model should be a good approximation of the machine learning model predictions locally, but it does not have to be a good global approximation. This kind of accuracy is also called local fidelity.
Mathematically, local surrogate models with interpretability constraint can be expressed as follows:
Local Interpretable Model-agnostic Explanations (LIME)
Algorithm
Pick an input that you want an explanation for.
Sample the neighbors of the selected input (i.e. perturbation).
Train a linear classifier on the neighbors.
The weights on the linear classifier is the explanation.
Local Interpretable Model-agnostic Explanations (LIME)
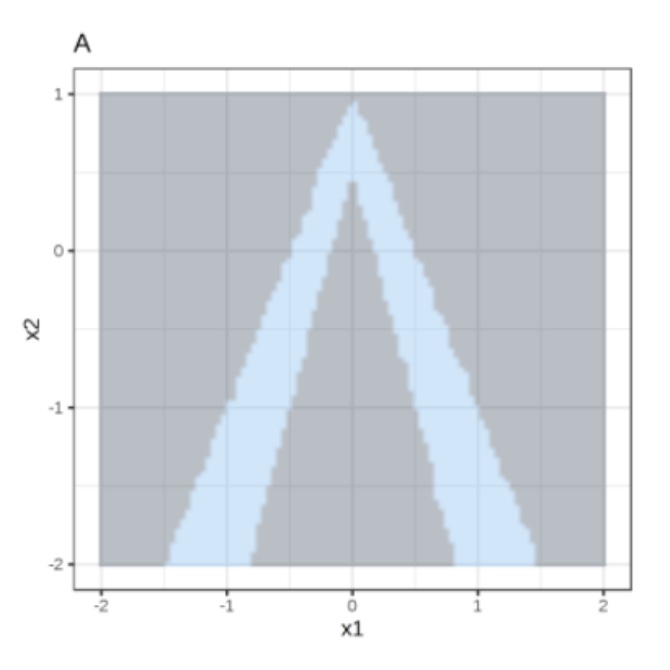
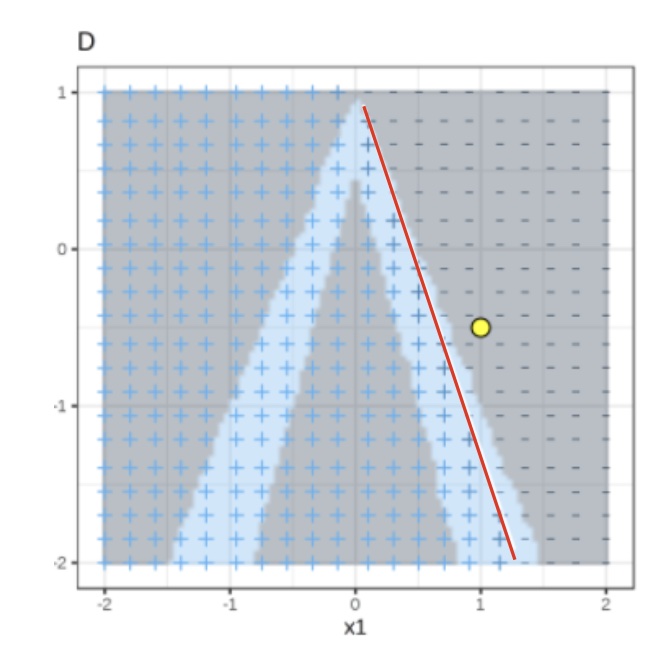
Random forest predictions given features x1 and x2.
Predicted classes: 1 (dark) or 0 (light).
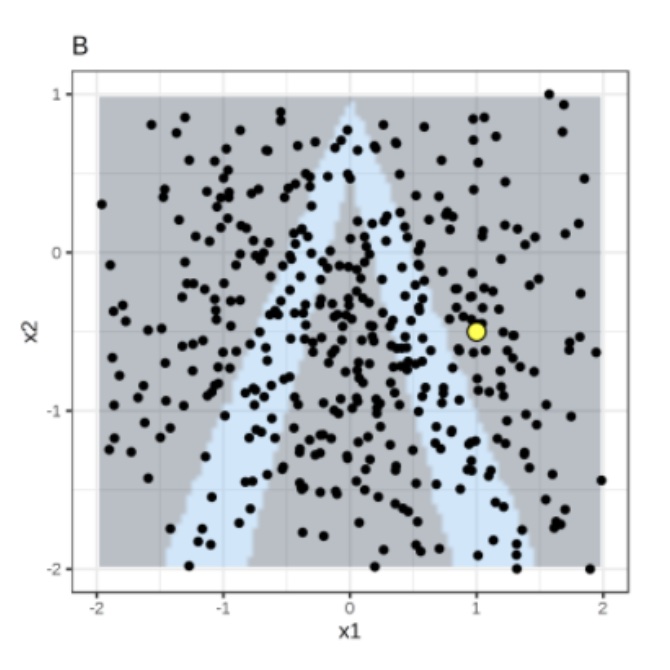
Local Interpretable Model-agnostic Explanations (LIME)
Instance of interest (big yellow dot) and data sampled from a normal distribution (small dots).
Local Interpretable Model-agnostic Explanations (LIME)
Assign higher weight to points near the instance of interest. I.e., \(weight(p) = \sqrt{\frac{e^{-d^2}}{w^2}}\) where \(d\) is the distance between \(p\) and the instantce of interest, and \(w\) is the kernel width (self-defined).
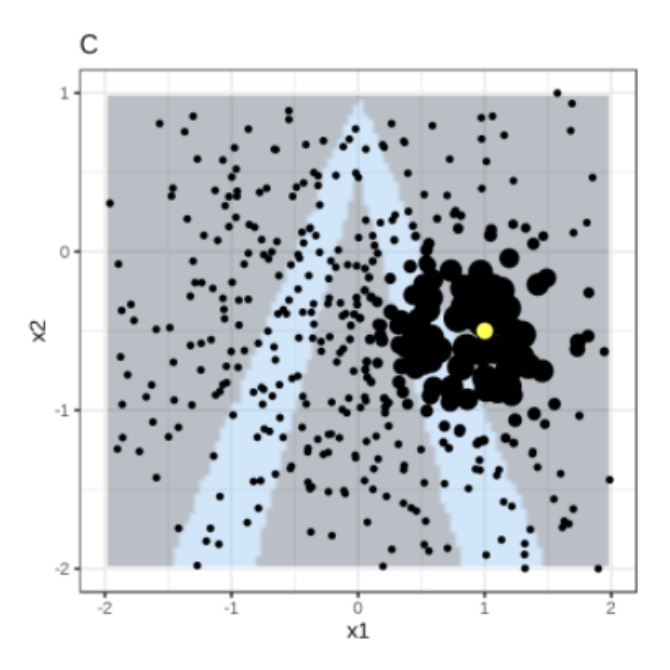
Local Interpretable Model-agnostic Explanations (LIME)
Use both the samples and sample weights to train a linear classifier.
Signs of the grid show the classifications of the locally learned model from the weighted samples. The red line marks the decision boundary (P(class=1) = 0.5).
The official implementation uses a Ridge Classifier as the linear model for explanation.
Training local surrogate models to explain individual predictions
\(s_i\) = sample weight, \(\lambda\) = regularization term
\(w_j\) = trained weight to explain the importance of feature j
The higher the \(\lambda\), the more sparse the \(w\) (more zeros) will become.
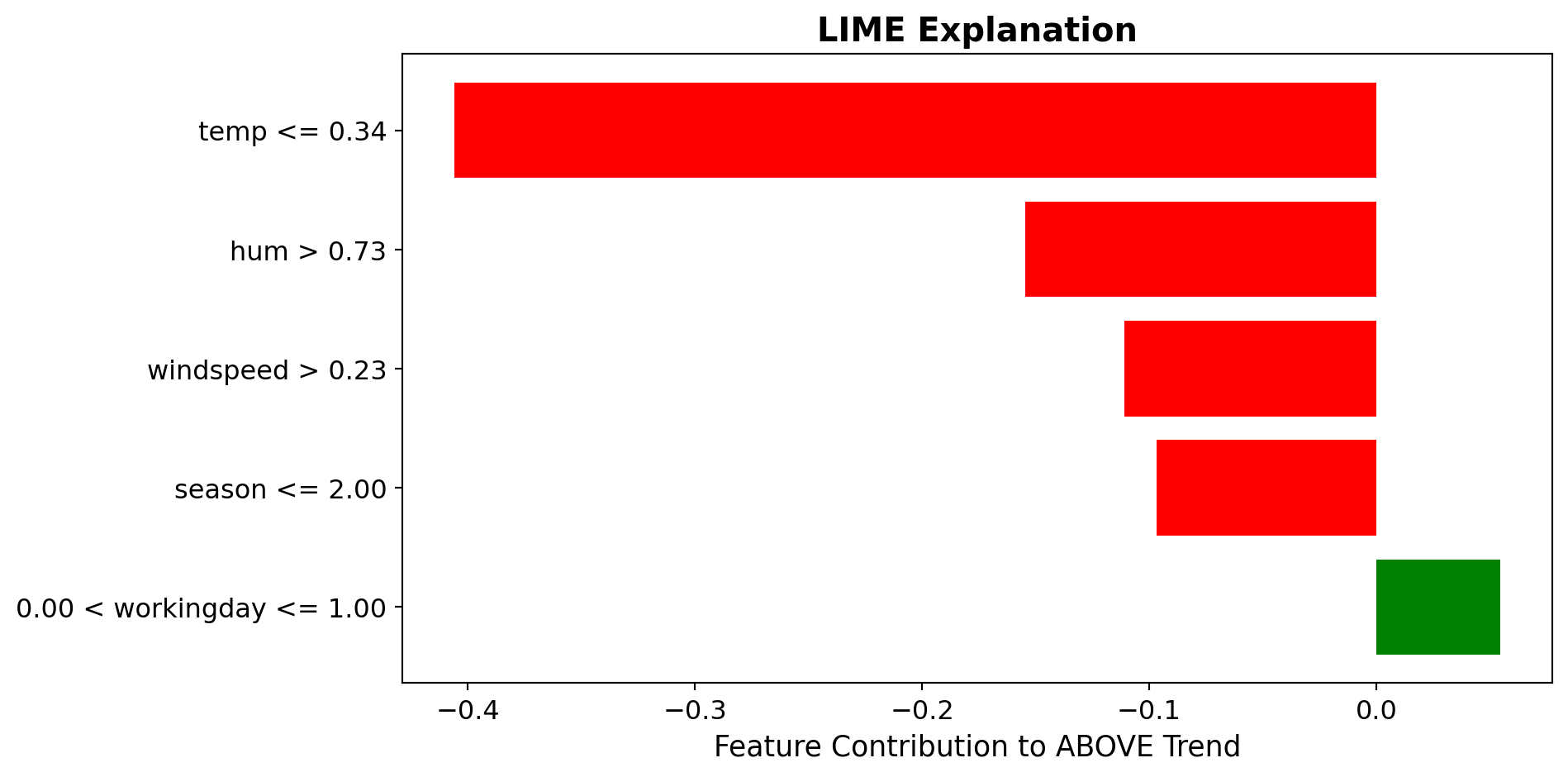
LIME Visualization: Bar Charts for Local Explanations
Primary LIME Output: Sparse Bar Charts
Case 1: High Rental DayPrediction: ABOVE Trend
▬▬▬▬▬▬▬▬▬▬Temp > 20°C
▬▬▬▬▬▬▬Windspeed Low
▬▬▬Holiday = False
✓ Warm temperature strongly supports high rentals ✓ Low wind moderately supports ✗ Non-holiday slightly opposes
Case 2: Low Rental DayPrediction: BELOW Trend
▬▬▬▬▬▬▬▬▬▬▬▬Weather: Rain
▬▬▬▬▬▬▬▬Temp < 5°C
▬▬Weekday = True
✗ Rain strongly opposes high rentals ✗ Cold temperature opposes ✓ Weekday weakly supports
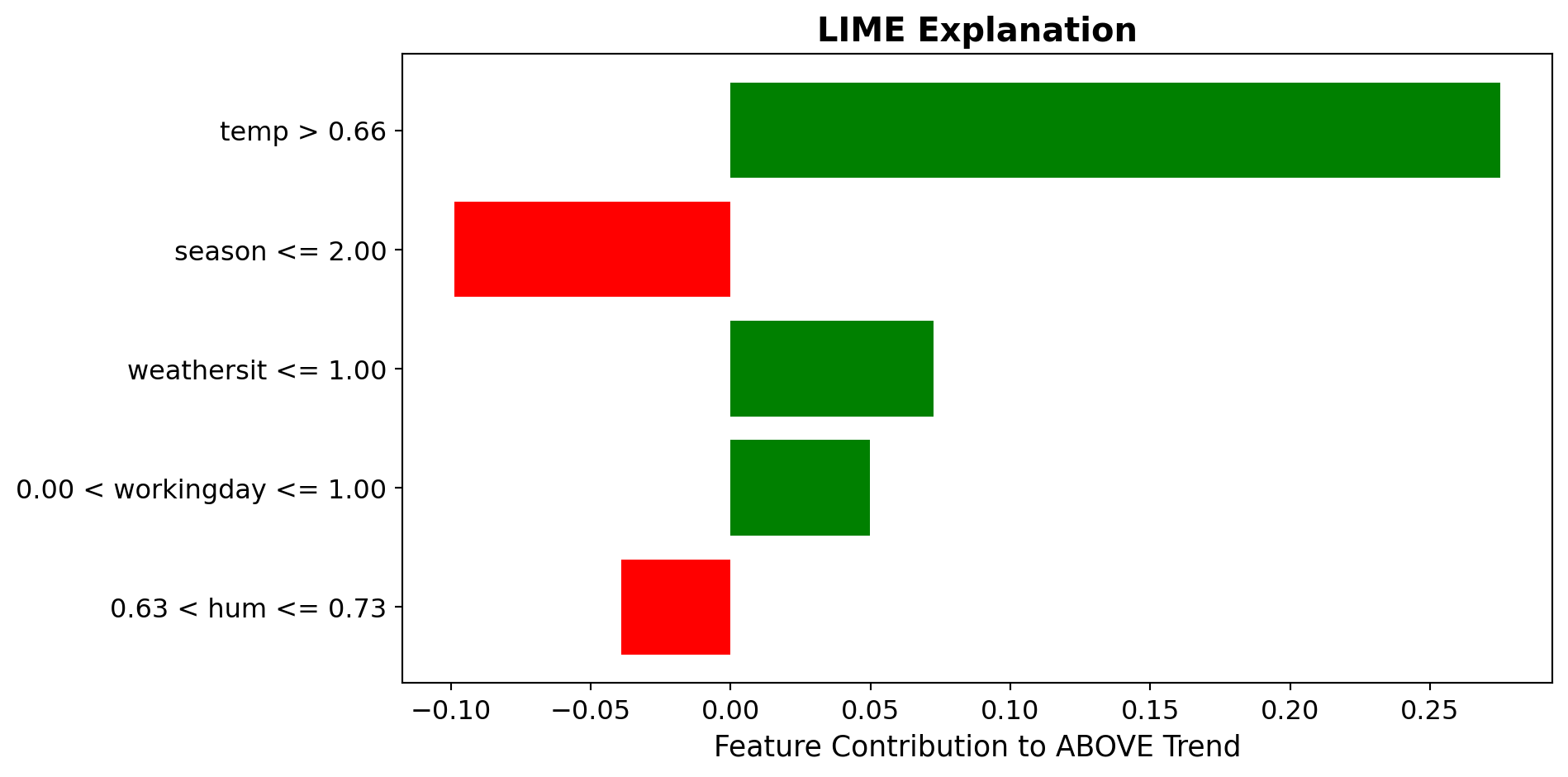
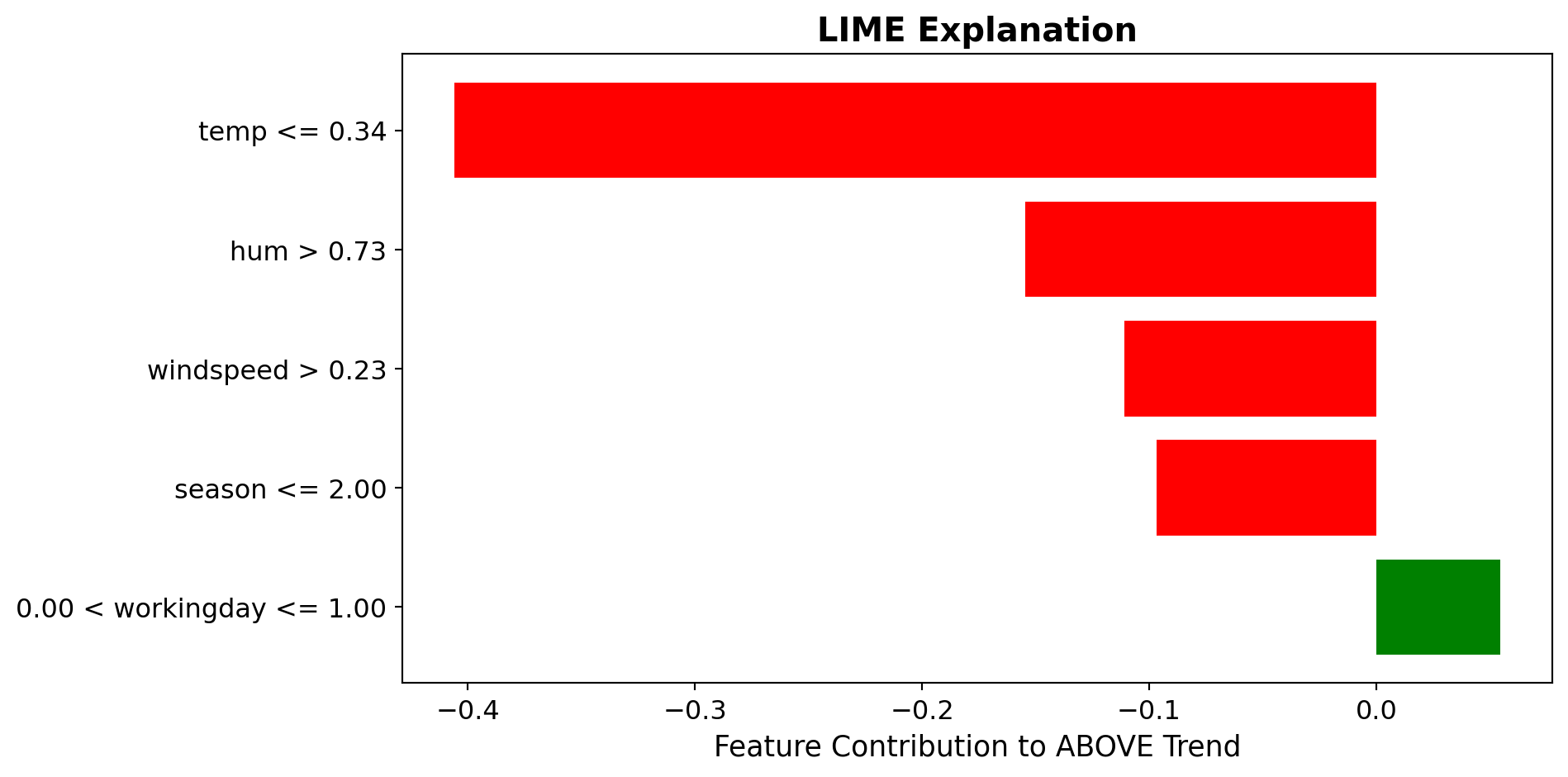
Local Surrogate (LIME): Bike Rental Example
Task: Predict if bike rentals will be above or below trend
High Rental Day
Prediction: {python} f”{pred_high[1]:.2f}“ probability ABOVE trend
✓ High temperature strongly supports ✓ Good weather condition supports
Low Rental Day
Prediction: {python} f”{pred_low[0]:.2f}“ probability BELOW trend
✗ Bad weather strongly opposes ✗ Low temperature opposes
Local Surrogate (LIME)
Training local surrogate models to explain individual predictions
Local Surrogate (LIME)
Raw data and explanation of a bad model’s prediction in the “Husky vs Wolf” task
LIME: Code Example
Dataset: California Housing (same model as PDP example)
import limeimport lime.lime_tabularimport numpy as np# Reload California Housing data for this examplehousing = fetch_california_housing()X_housing, y_housing = housing.data, housing.target# Retrain model on California Housingmodel = GradientBoostingRegressor( n_estimators=100, max_depth=4, learning_rate=0.1, random_state=0).fit(X_housing, y_housing)# Create LIME explainer using training dataexplainer = lime.lime_tabular.LimeTabularExplainer( training_data=X_housing, feature_names=housing.feature_names, mode='regression', random_state=0)# Select an instance to explain (e.g., instance 0)instance_idx =0instance = X_housing[instance_idx]# Generate explanation for this instance# predict_fn should return predictionsexp = explainer.explain_instance( instance, model.predict, num_features=5# Show top 5 features)
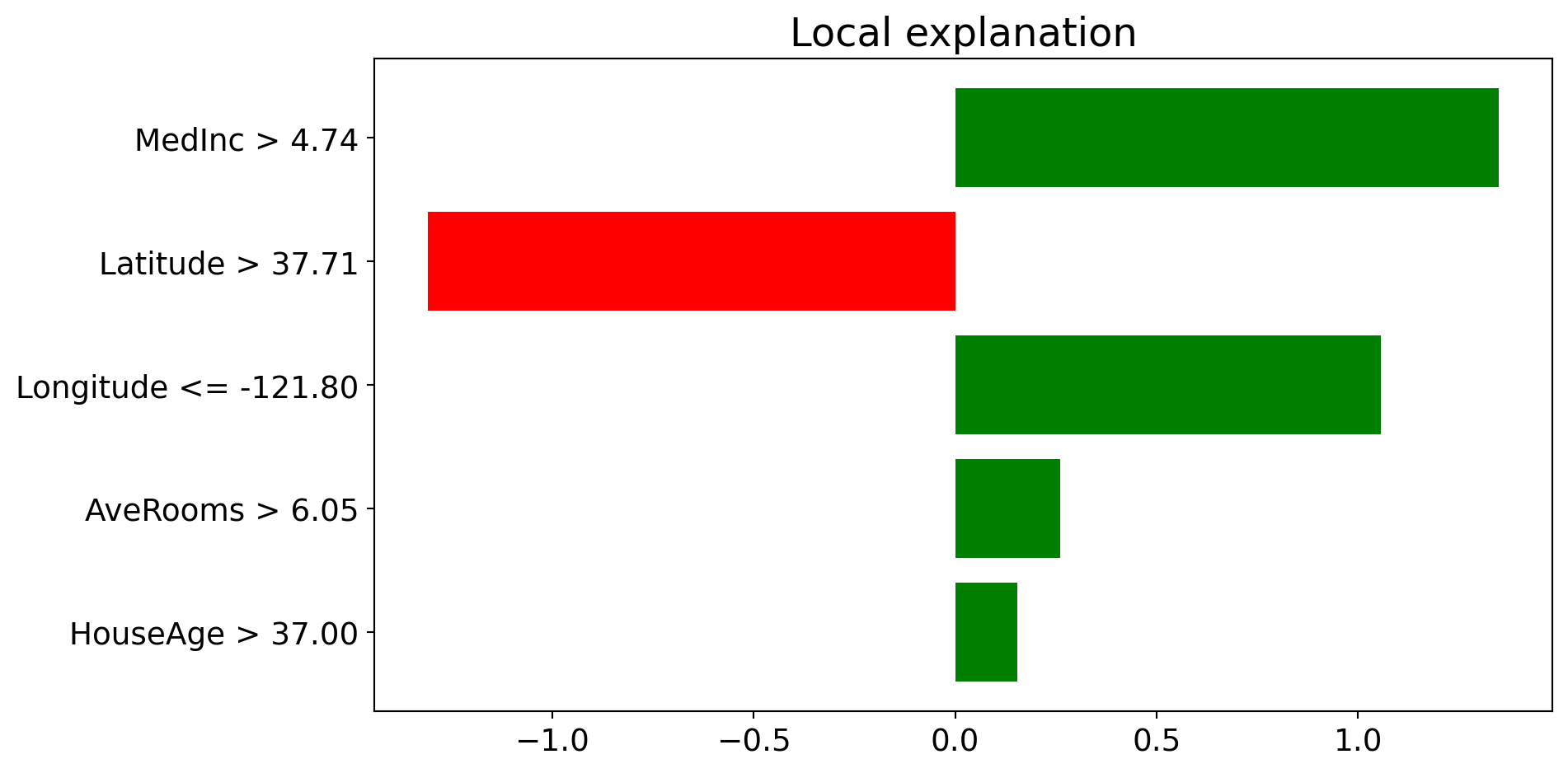
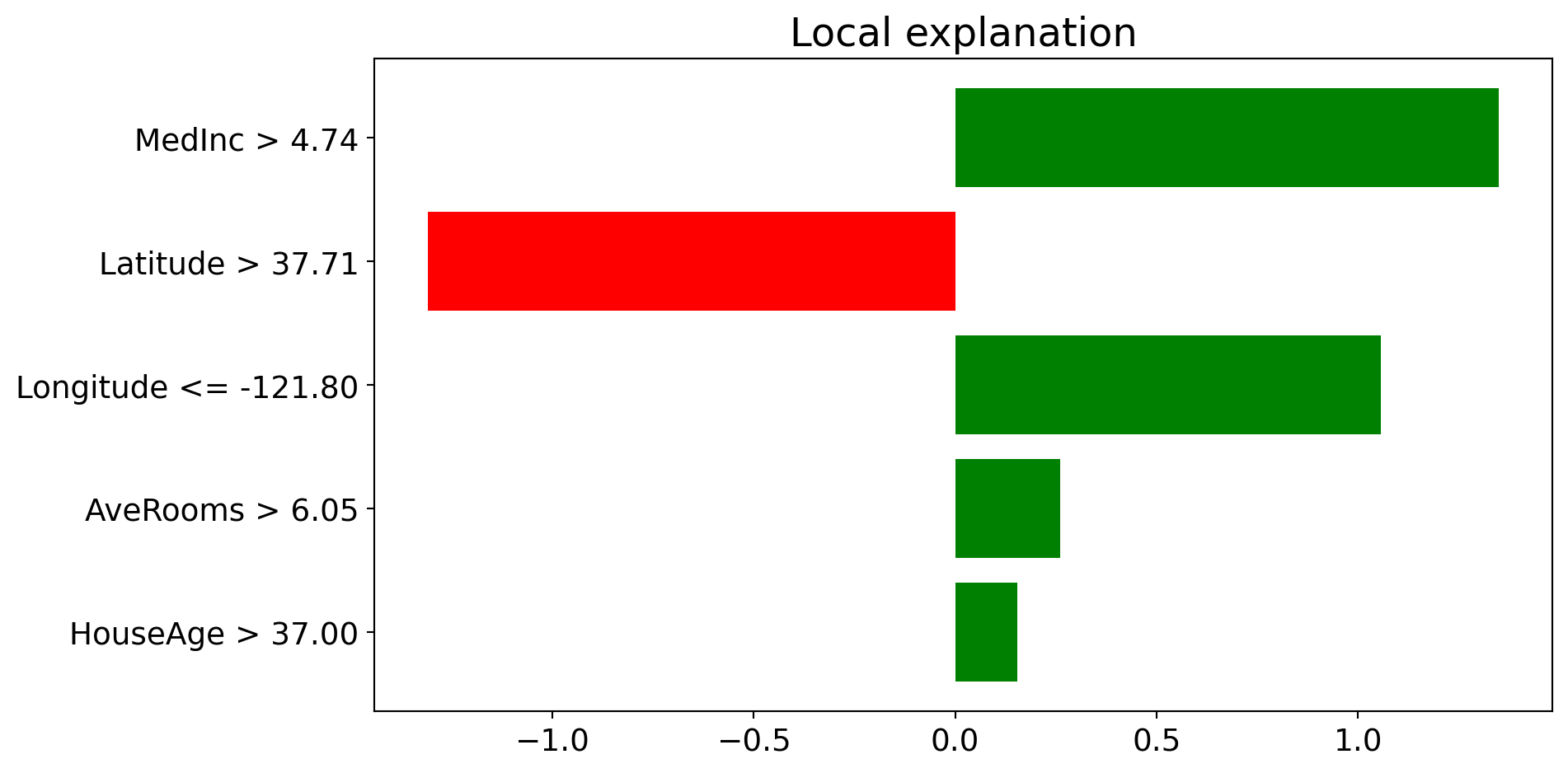
LIME: Output Visualization
Explanation for Instance 0:
Predicted value: 4.29 (in units of $100k)
The bar chart shows which features push the prediction higher (positive) or lower (negative) for this specific house.
Local Interpretable Model-agnostic Explanations (LIME)
Pros
Explanations are short (= selective) and possibly contrastive.
we can control the sparsity of weight coefficients in the regressions method.
Very easy to use.
Cons
Unstable results due to sampling.
Hard to weight similar neighbors in a high dimensional dataset.
Many parameters for data scientists to hide biases.
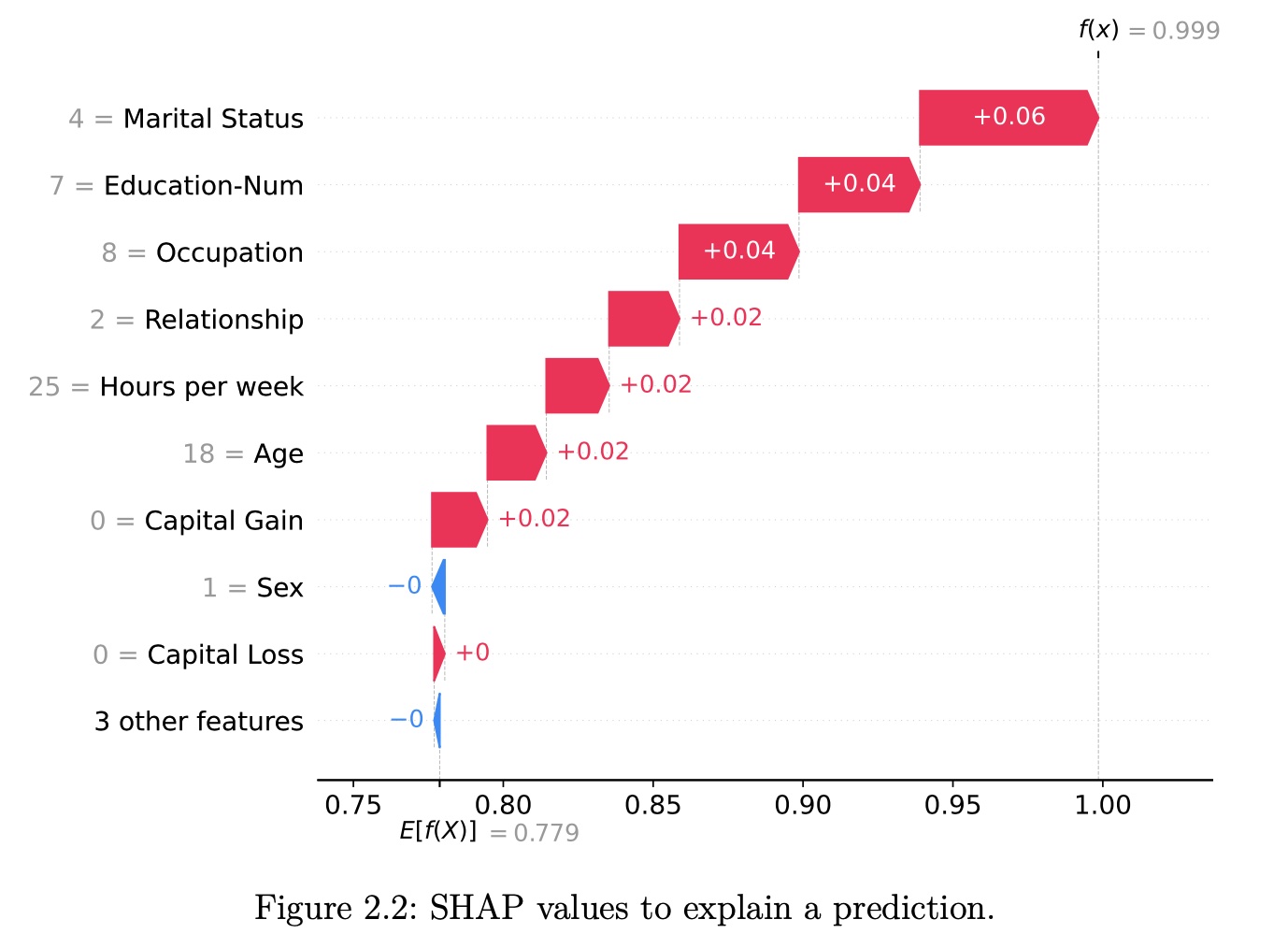
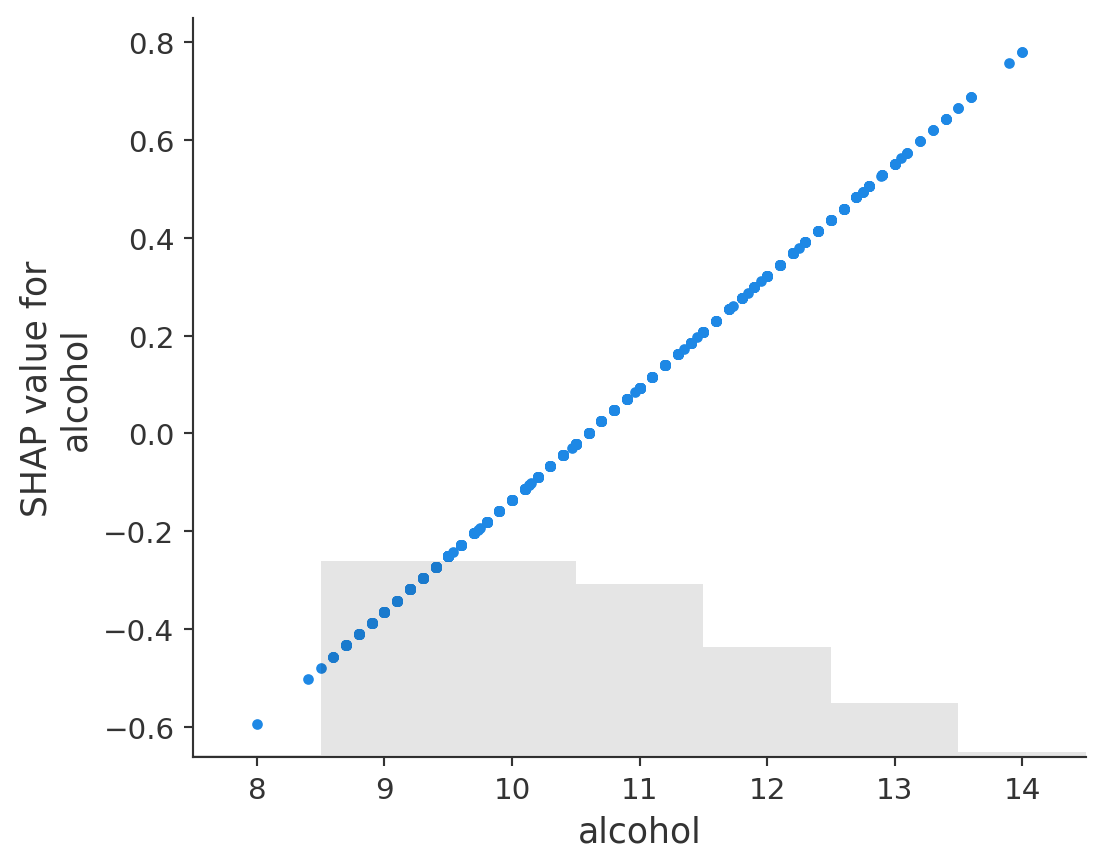
SHAP (SHapley Additive exPlanations)
SHAP (Lundberg and Lee 2017a) is a game-theory-inspired method created to explain predictions made by machine learning models. SHAP generates one value per input feature (also known as SHAP values) that indicates how the feature contributes to the prediction of the specified data point.
A Short History of Shapley Values and SHAP
Three key milestones:
1953: The introduction of Shapley values in game theory
2010: The initial steps toward applying Shapley values in machine learning
2017: The advent of SHAP, a turning point in machine learning
Lloyd Shapley’s Pursuit of Fairness (1953)
Lloyd Shapley - “The greatest game theorist of all time”
PhD at Princeton (post-WWII): “Additive and Non-Additive Set Functions”
1953 paper: “A Value for n-Person Games”
2012 Nobel Prize in Economics (with Alvin Roth) for work in market design and matching theory
The Problem: How to fairly divide payouts among players who contribute differently to a cooperative game?
The Solution: Shapley values provide a mathematical method for fair distribution based on marginal contributions
Applications of Shapley values:
Political science
Economics
Computer science
Dividing profits among shareholders
Allocating costs among collaborators
Assigning credit in research projects
Key insight: By 1953, Shapley values were well-established in game theory, but machine learning was still in its infancy.
Early Days in Machine Learning (2010)
2010: Erik Štrumbelj and Igor Kononenko propose using Shapley values for ML
Paper: “An efficient explanation of individual classifications using game theory”
2014 follow-up: Further methodology development
Why didn’t it gain immediate traction?
❌ Barriers to adoption:
Explainable AI/Interpretable ML not widely recognized yet
No code released with the papers
Estimation method too slow for images/text
Limited awareness outside specialized communities
✅ What was needed:
Growing demand for interpretability
Open-source implementation
Faster computation methods
High-profile publication venue
Integration with popular ML frameworks
The SHAP Cambrian Explosion (2017)
2016: LIME paper catalyzes the field
Ribeiro et al. introduce Local Interpretable Model-Agnostic Explanations → growing interest in model interpretability
2017: Lundberg and Lee publish SHAP at NeurIPS
“A Unified Approach to Interpreting Model Predictions”
Key contributions beyond 2010 work:
Kernel SHAP: New estimation method using weighted linear regression
Unification framework: Connected SHAP to LIME, DeepLIFT, and Layer-Wise Relevance Propagation
Open-source shap package: Wide range of features and plotting capabilities
High-profile venue: Published at major ML conference (NIPS/NeurIPS)
Why SHAP Gained Popularity
Critical success factors:
✓ Published at prestigious venue (NeurIPS) ✓ Pioneering work in rapidly growing field ✓ Open-source Python package - enabled integration ✓ Ongoing development by original authors ✓ Strong community contributions ✓ Comprehensive visualization tools
2020 breakthrough: TreeSHAP
Efficient computation for tree-based models
Enabled SHAP for state-of-the-art models
Made global interpretations possible
Naming conventions:
Shapley values: Original game theory method (1953)
SHAP: Application to machine learning (2017)
SHAP values: Resulting feature importance values
shap: The Python library implementation
“SHAP” became a brand name like Post-it or Band-Aid - well-established in the community and distinguishes game theory from ML application.
Theory of Shapley Values
Who’s going to pay for that taxi?
Alice, Bob, and Charlie have dinner together and share a taxi ride home. The total cost is $51.
The question is: How should they divide the costs fairly?
Passengers
Cost
Note
∅
$0
No taxi, no costs
{Alice}
$15
Standard fare
{Bob}
$25
Luxury taxi
{Charlie}
$38
Lives further away
{Alice, Bob}
$25
Bob gets his way
{Alice, Charlie}
$41
Drop Alice first
{Bob, Charlie}
$51
Drop Bob first
{Alice, Bob, Charlie}
$51
Full fare
Key observations:
Alice alone: $15
Bob alone: $25 (insists on luxury)
Charlie alone: $38 (lives farther)
All three: $51
Naive approach: $51 ÷ 3 = $17 each
Problem: Is this fair? Alice is subsidizing the others!
We need a principled way to divide costs based on marginal contributions.
Calculating Marginal Contributions
Marginal Contribution = Value with player − Value without player
In words: The SHAP value \(\phi_j^{(i)}\) of feature \(j\) is the weighted average marginal contribution of feature value \(x_j^{(i)}\) across all possible coalitions of features.
This is Shapley values with an ML-specific value function!
Interpreting SHAP Values Through Axioms
Since SHAP values are Shapley values, they satisfy the four axioms:
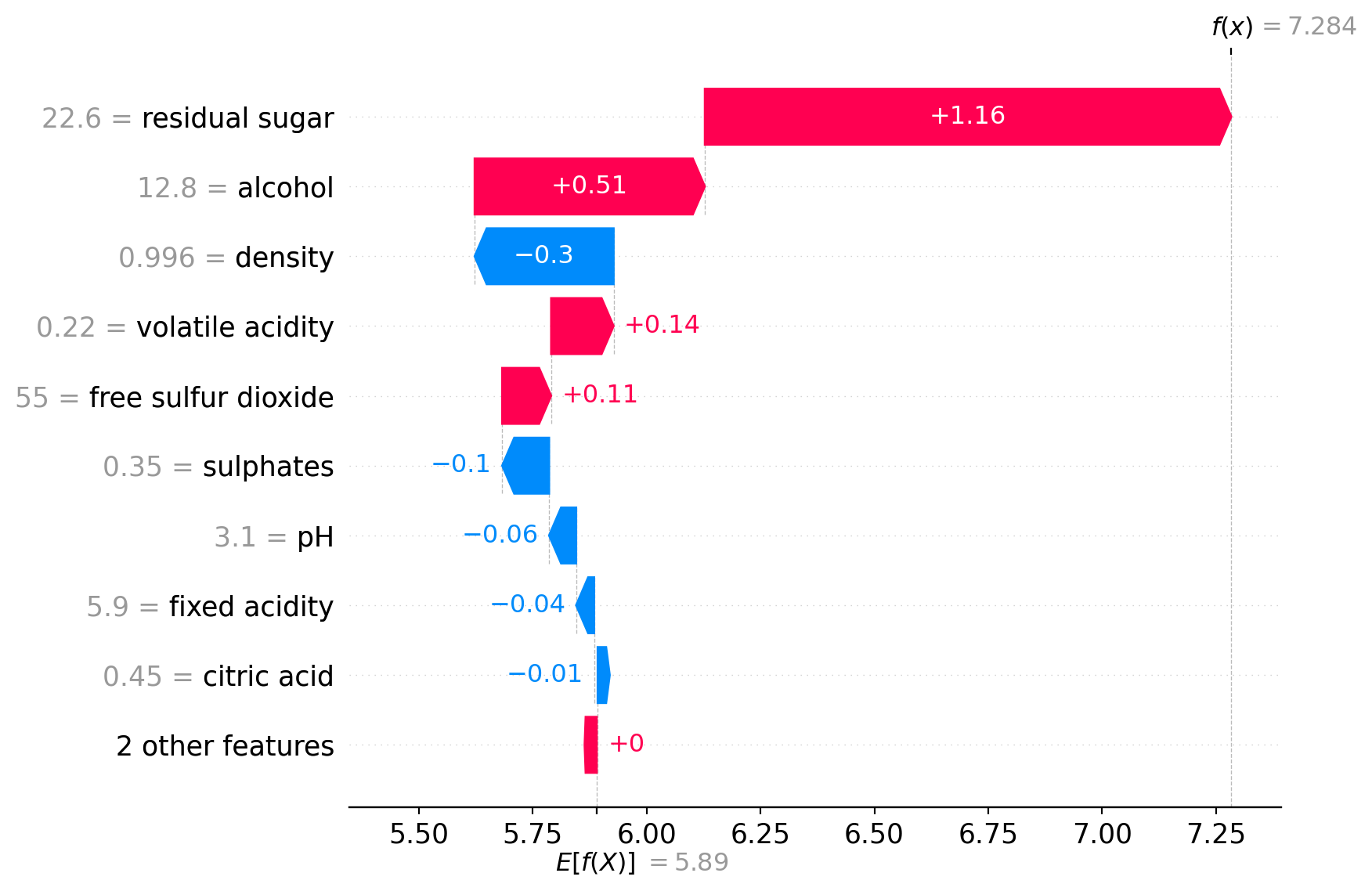
# Create SHAP explainer for linear modelsexplainer = shap.LinearExplainer(model, X_train)# Compute SHAP values for test setshap_values = explainer(X_test)print(f"SHAP values shape: {shap_values.values.shape}")print(f"Base value (average prediction): {shap_values.base_values[0]:.3f}")print(f"\nSHAP values for first test instance:")for feature, value inzip(X.columns, shap_values.values[0]):print(f" {feature:25s}: {value:+.4f}")print(f"\nPrediction for first instance: {model.predict(X_test.iloc[[0]])[0]:.3f}")print(f"Sum: base_value + sum(shap_values) = {shap_values.base_values[0] + shap_values.values[0].sum():.3f}")
SHAP values shape: (980, 11)
Base value (average prediction): 5.890
SHAP values for first test instance:
fixed acidity : -0.0348
volatile acidity : +0.0031
citric acid : -0.0055
residual sugar : +0.3151
chlorides : -0.0001
free sulfur dioxide : +0.1074
total sulfur dioxide : -0.0023
density : +0.0256
pH : -0.0654
sulphates : +0.0529
alcohol : +0.0855
Prediction for first instance: 6.372
Sum: base_value + sum(shap_values) = 6.372