Deep Learning Visualization
CS-GY 9223 - Fall 2025
2025-10-27
Understanding Deep Learning
Understanding Deep Learning by Simon J.D. Prince
Published by MIT Press, 2023
Available free online: https://udlbook.github.io/udlbook
Why this book?
- Modern treatment (includes transformers, diffusion models)
- Excellent visual explanations
- Free and accessible
- Strong mathematical foundations with intuitive explanations

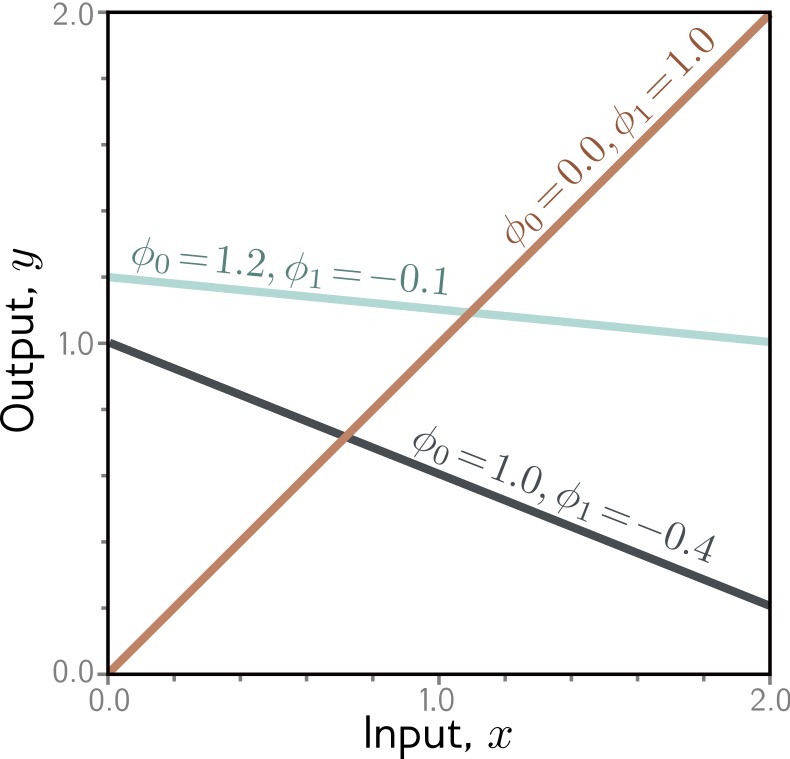
1-D Linear Regression Model
The simplest supervised learning model:
\[y = f[x, \Phi] = \Phi_0 + \Phi_1 x\]
- \(\Phi_0\): Intercept (bias term)
- \(\Phi_1\): Slope (weight)
- Only 2 parameters to learn
Linear Regression: Measuring Error
How do we quantify “good fit”?
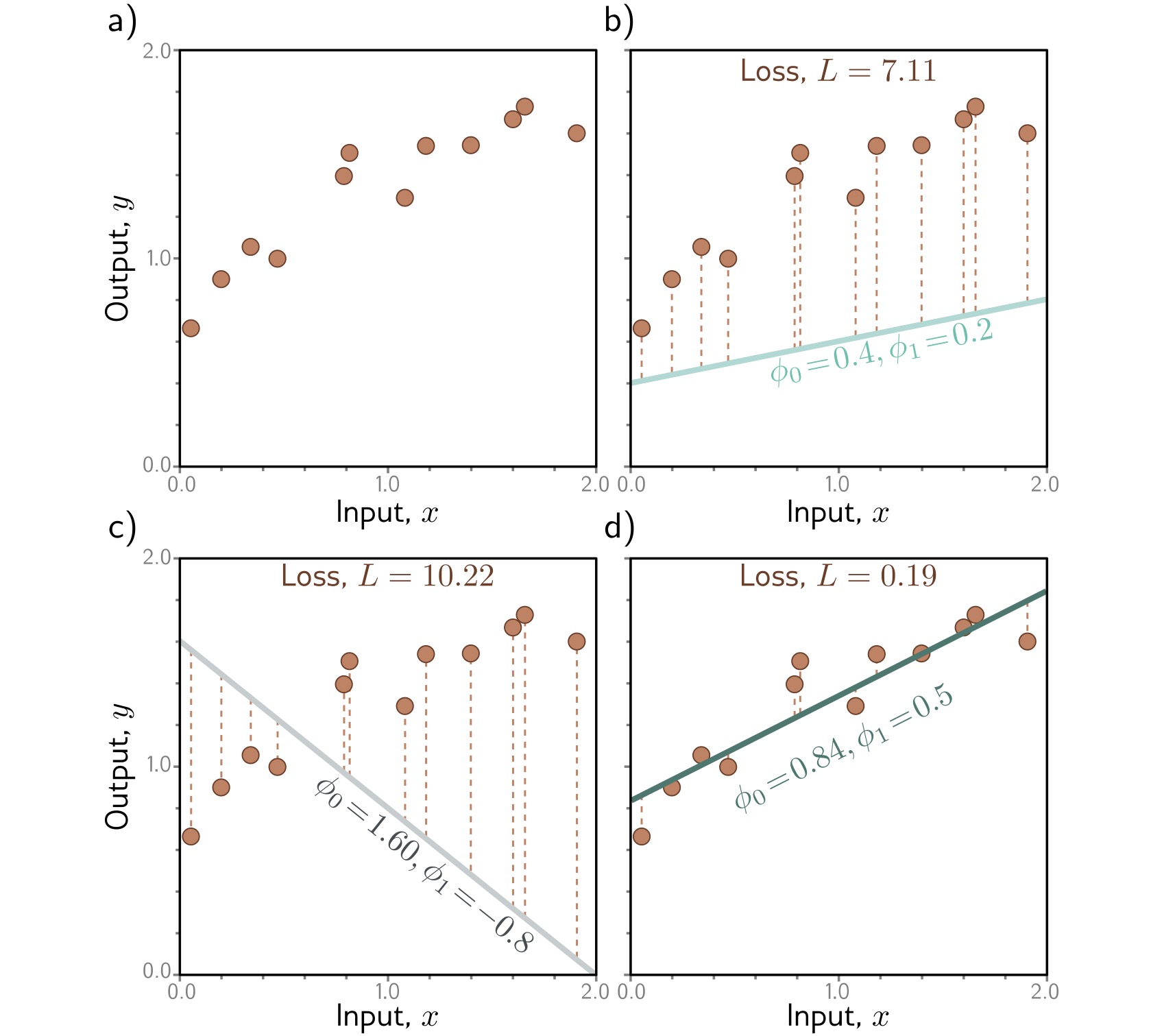
Loss Function: Sum of squared errors
\[L[\Phi] = \sum_{i=1}^{N} (y_i - f[x_i, \Phi])^2\]
Vertical distance from each data point to the line → squared → summed = total error
Loss Surface
Visualizing all possible parameter combinations:
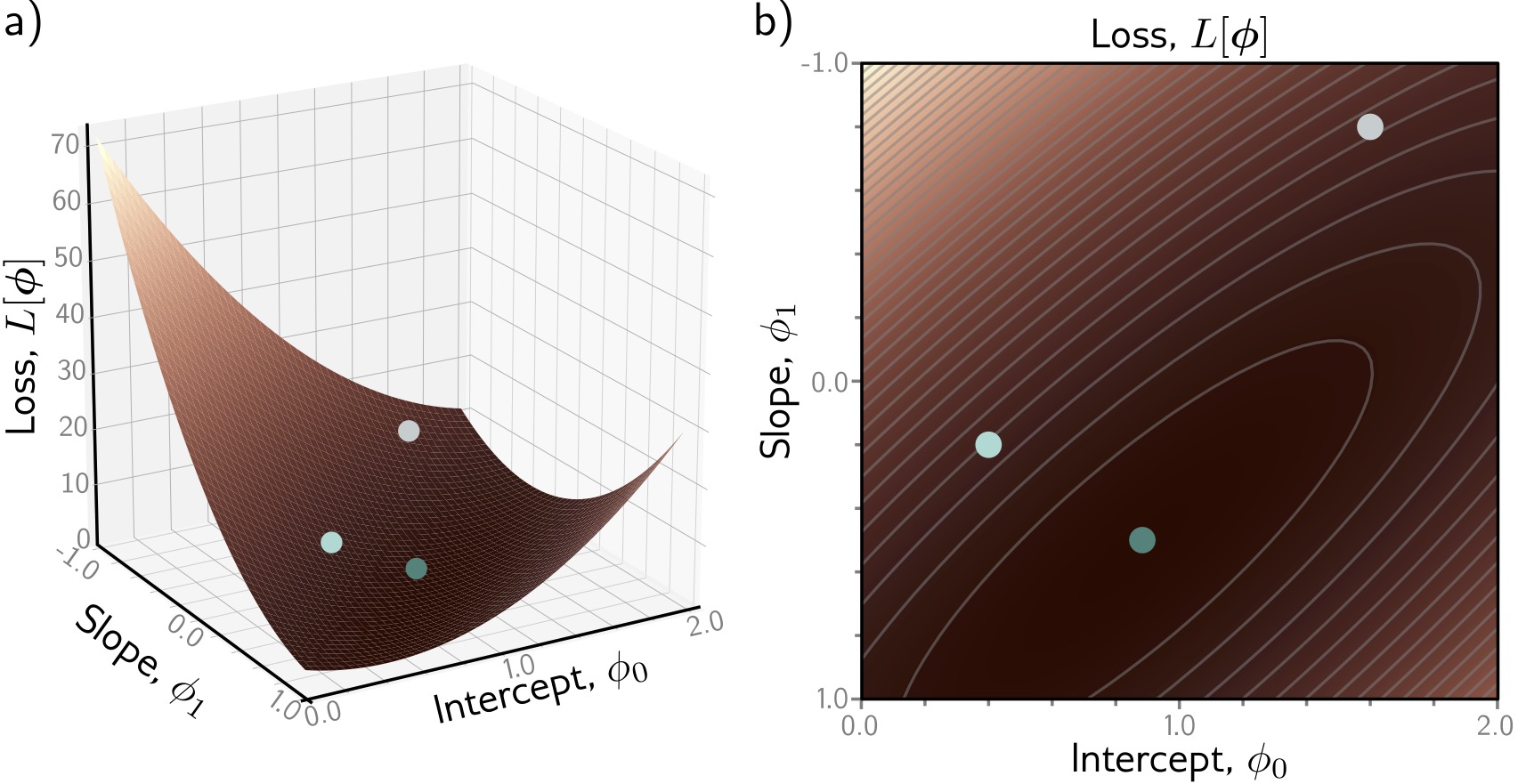
- X-axis: Slope \(\Phi_1\)
- Y-axis: Intercept \(\Phi_0\)
- Z-axis (color): Loss \(L[\Phi]\)
Goal: Find the lowest point (dark blue valley)
Key Observations:
- Single global minimum - bowl-shaped surface
- Smooth - we can use gradients to navigate
- Convex - any path downhill leads to optimum
For linear models, optimization is easy! Deep networks have much more complex loss landscapes…
Optimization: Gradient Descent
How do we find the minimum?
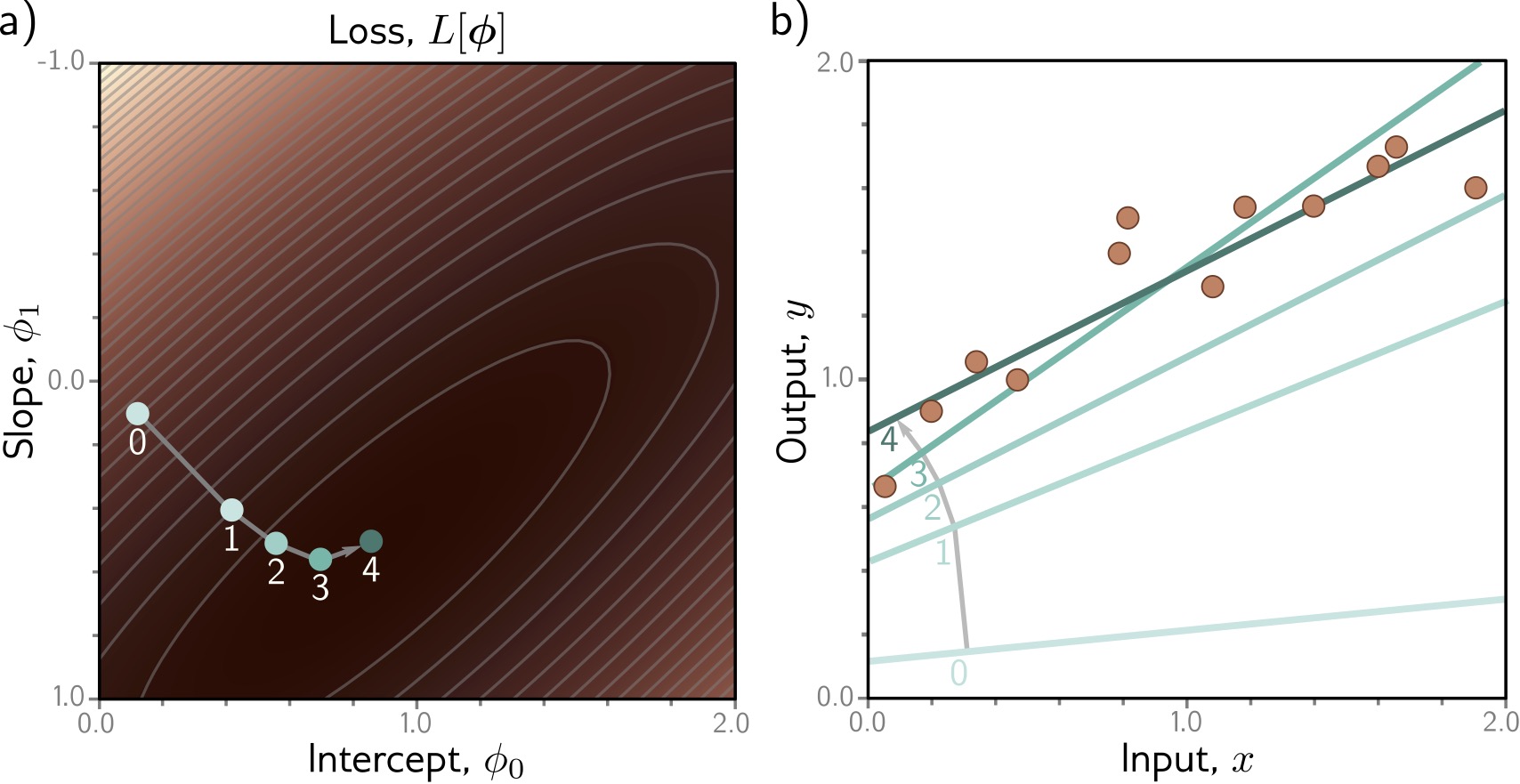
Algorithm: Iteratively move downhill
- Start at random position
- Compute gradient (slope direction)
- Take small step opposite to gradient
- Repeat until convergence
\[\Phi_{new} = \Phi_{old} - \alpha \nabla L[\Phi]\]
(\(\alpha\) = learning rate)
Activation Functions: ReLU
ReLU (Rectified Linear Unit): The most popular activation function
\[a[z] = \max(0, z) = \begin{cases} z & \text{if } z > 0 \\ 0 & \text{if } z \leq 0 \end{cases}\]
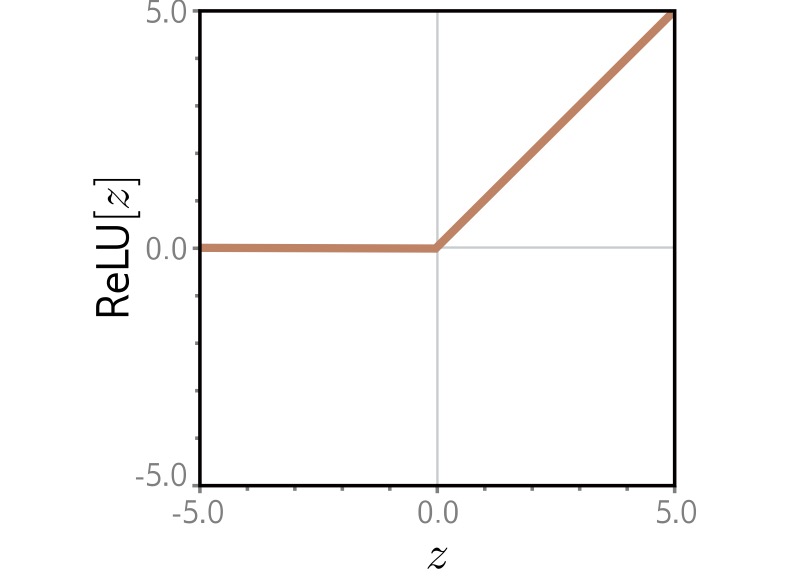
Why ReLU?
✓ Simple: Easy to compute and differentiate
✓ Efficient: Avoids vanishing gradient problem
✓ Sparse: Many activations are exactly zero
✓ Biological: Neurons either fire or they don’t
Building Intuition: Composing ReLUs
How do multiple ReLU activations combine to approximate complex functions?
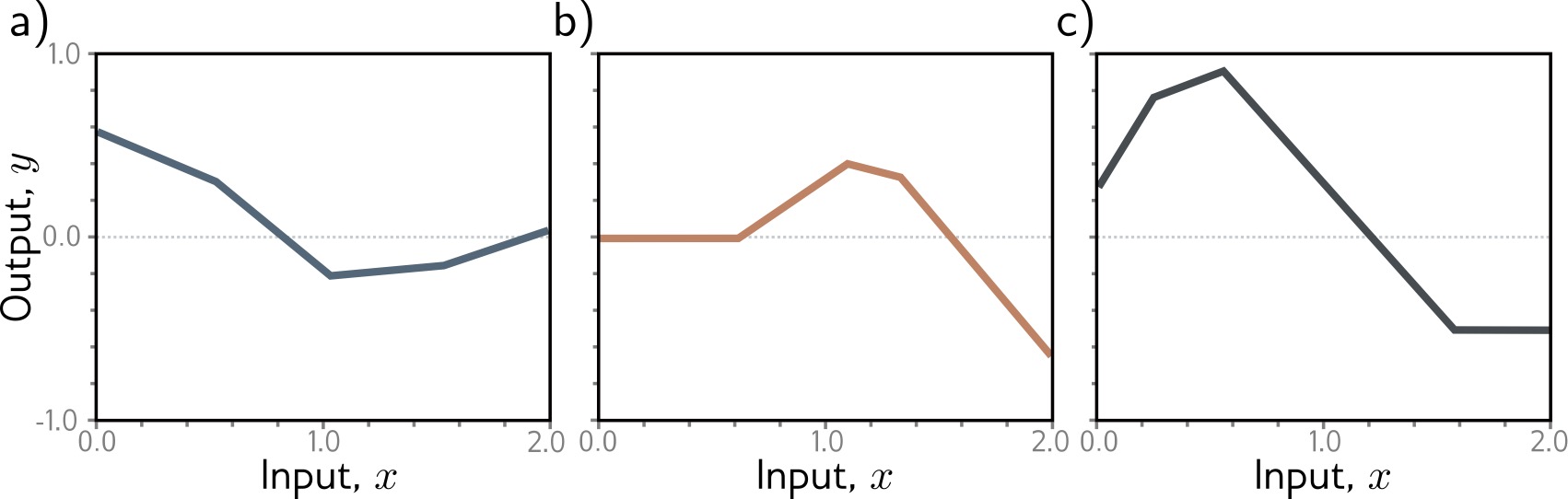
Each hidden unit:
- Computes linear function of input
- Applies ReLU → bent line
- Gets weighted and summed
Combining multiple units:
- Different slopes and bends
- Sum creates complex shapes
- More units → more flexibility
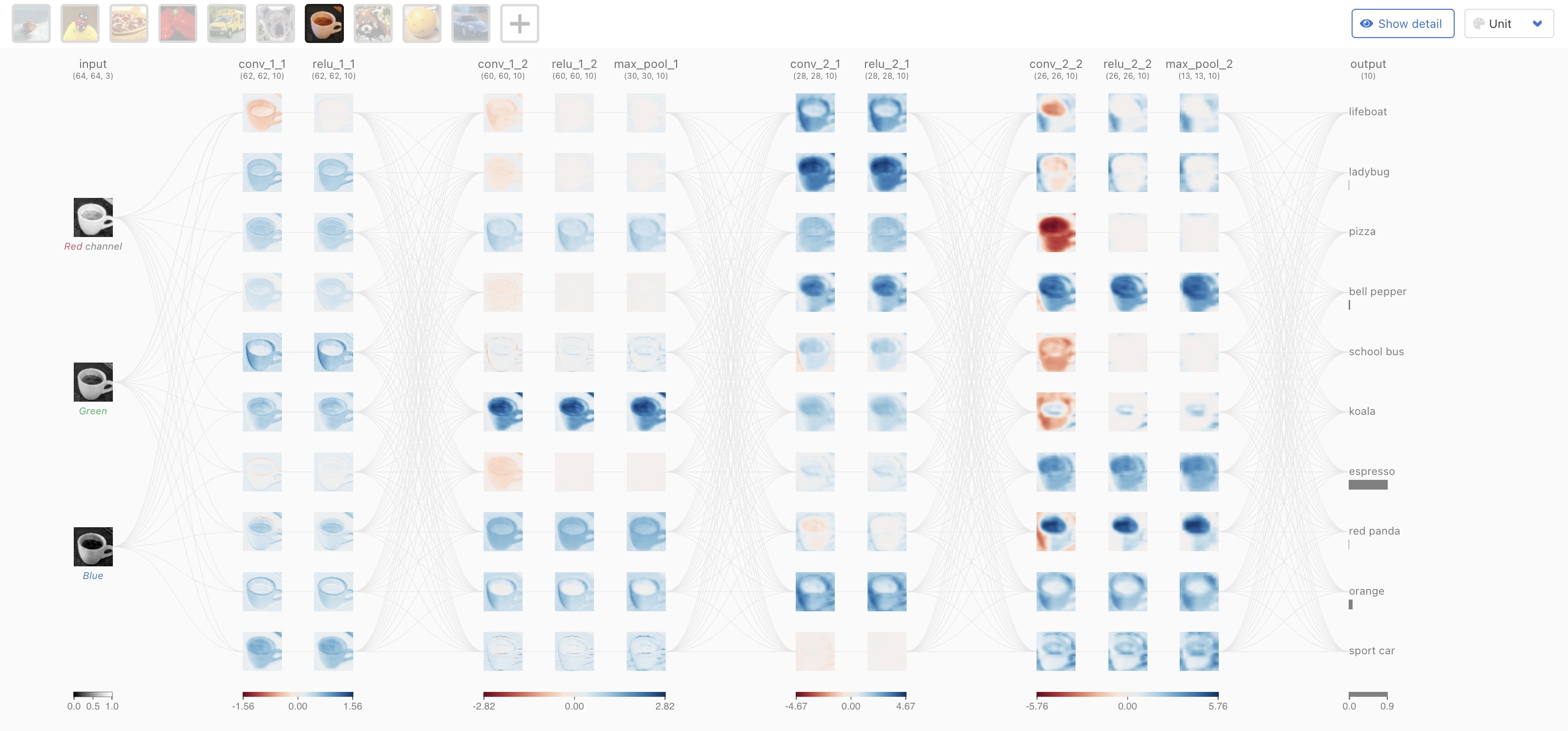
Neural Network Computation
Step-by-step: How a shallow network processes an input
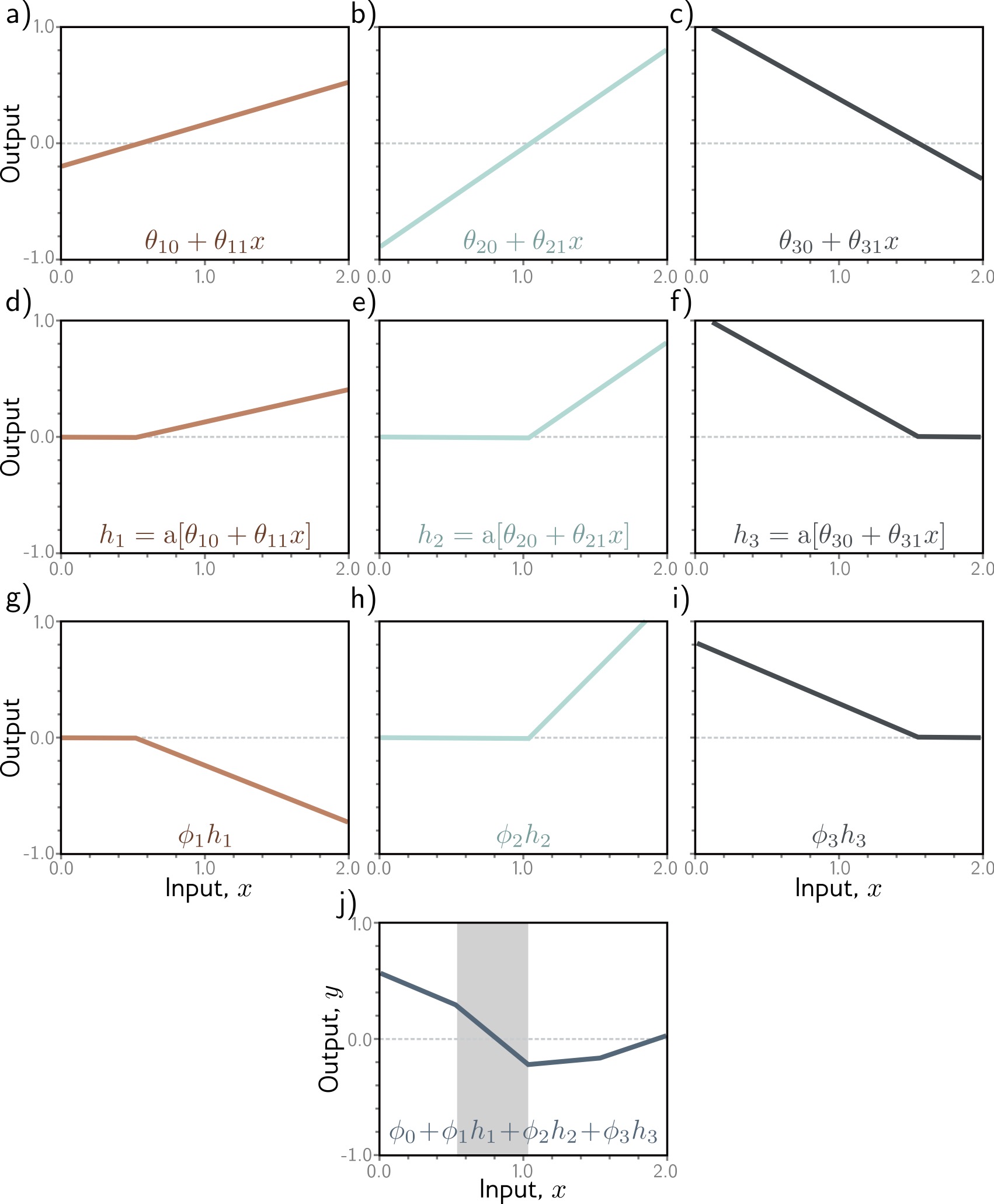
Process:
Input \(x\) (left) enters the network
Each hidden unit computes: \(h_i = a[\Theta_{i0} + \Theta_{i1} x]\)
Weighted combination: \(y = \Phi_0 + \sum_i \Phi_i h_i\)
Final output \(y\) (right)
Neural Network Diagram
Standard visualization: Network architecture
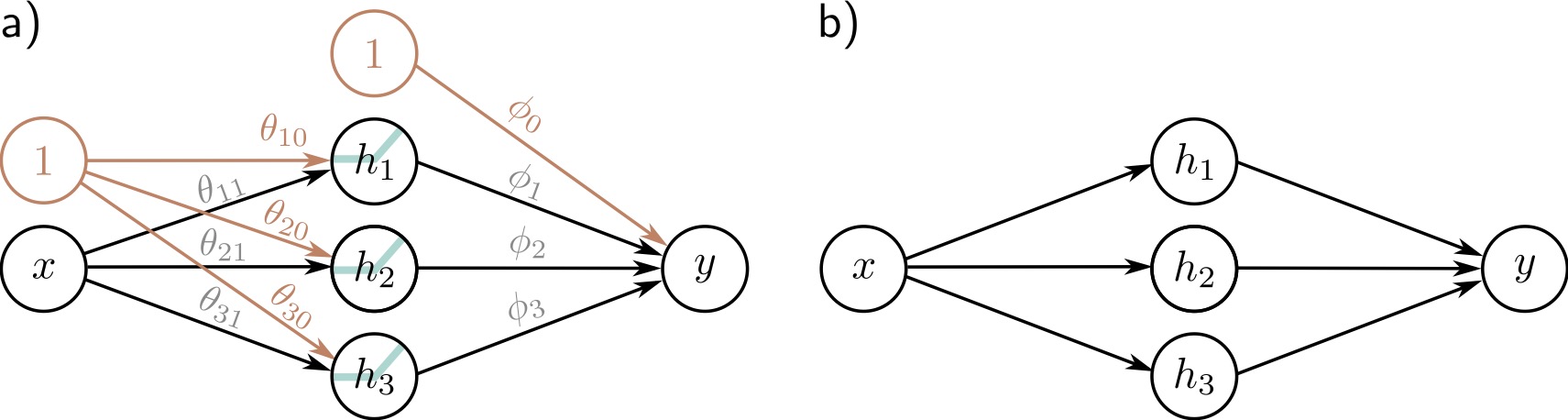
Components:
- ⚫ Input layer: Raw features
- 🔵 Hidden layer: Learned representations
- ⚫ Output layer: Prediction
- → Connections: Weighted parameters
Terminology:
- Hidden units/neurons: Computed values in middle
- Pre-activations: Before ReLU
- Activations: After ReLU
- Fully connected: Every unit connects to all units in next layer
Universal Approximation Theorem
Theoretical Foundation: Shallow networks can approximate any continuous function!
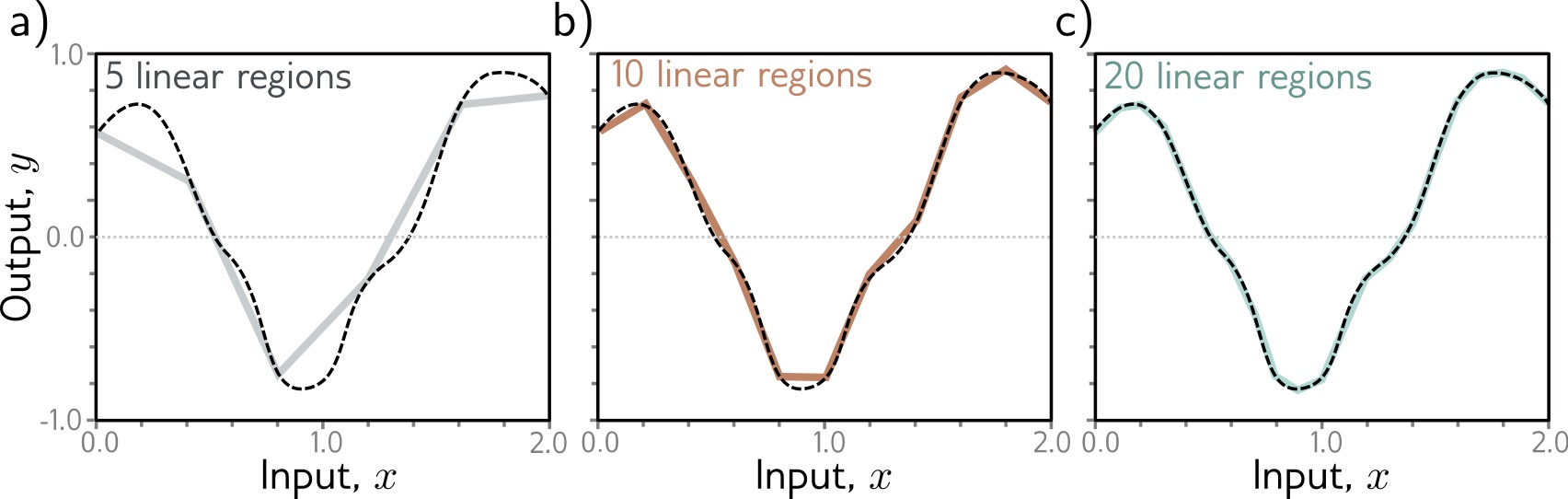
Theorem (Cybenko 1989, Hornik 1991):
A shallow neural network with enough hidden units can approximate any continuous function to arbitrary accuracy on a compact domain.
But…
- May require exponentially many hidden units
- Doesn’t tell us how to find the parameters
- Deep networks are often more efficient
Composing Networks
Building deep networks: Stack multiple hidden layers
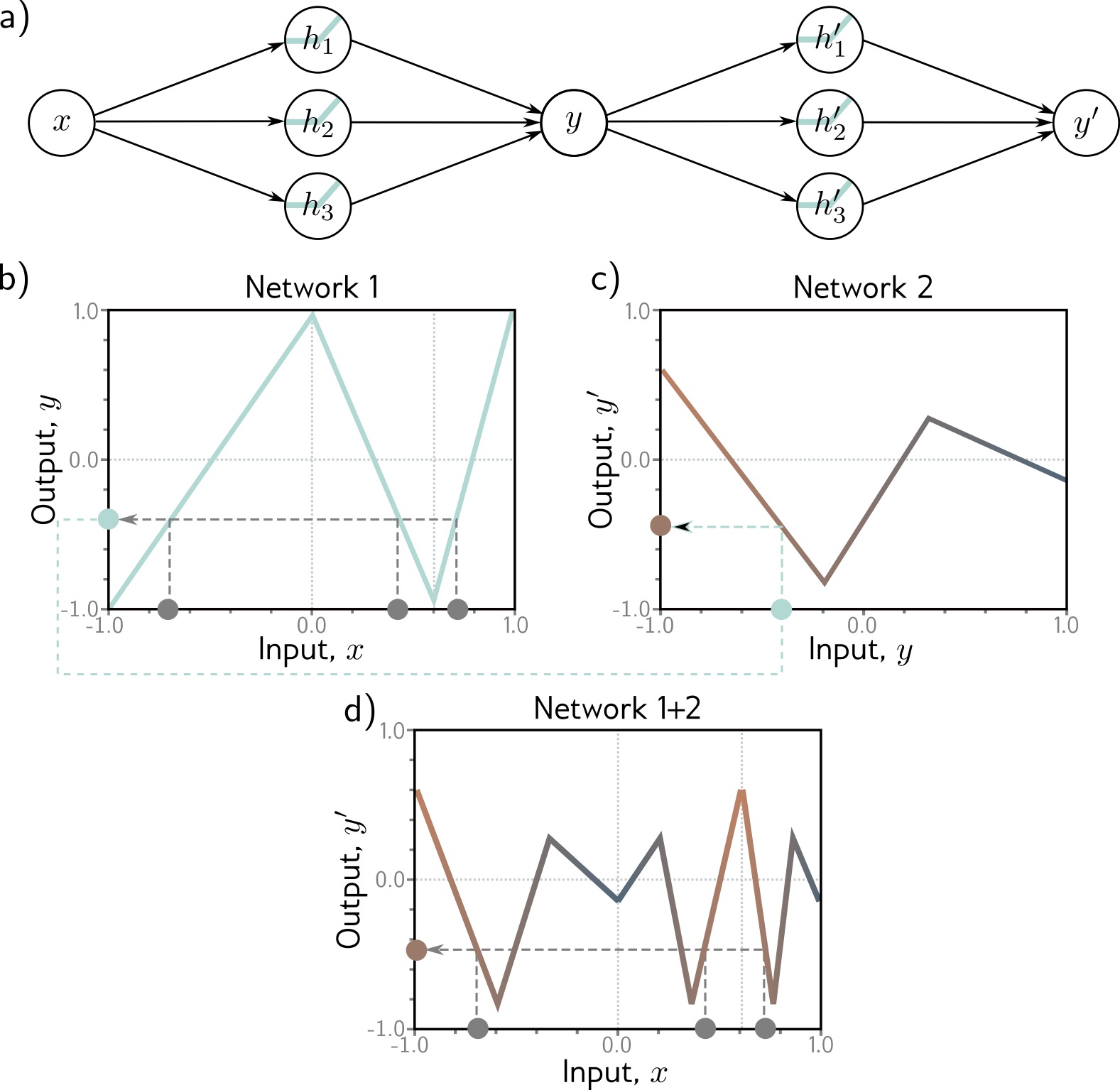
Each layer:
\[h^{(k)} = a[W^{(k)} h^{(k-1)} + b^{(k)}]\]
\(h^{(k)}\): Activations at layer \(k\)
\(W^{(k)}\), \(b^{(k)}\): Parameters for layer \(k\)
Composition: \(f = f_K \circ f_{K-1} \circ \ldots \circ f_1\)
How Deep Networks Transform Space
Geometric intuition: Each layer performs a non-linear transformation of the representation space
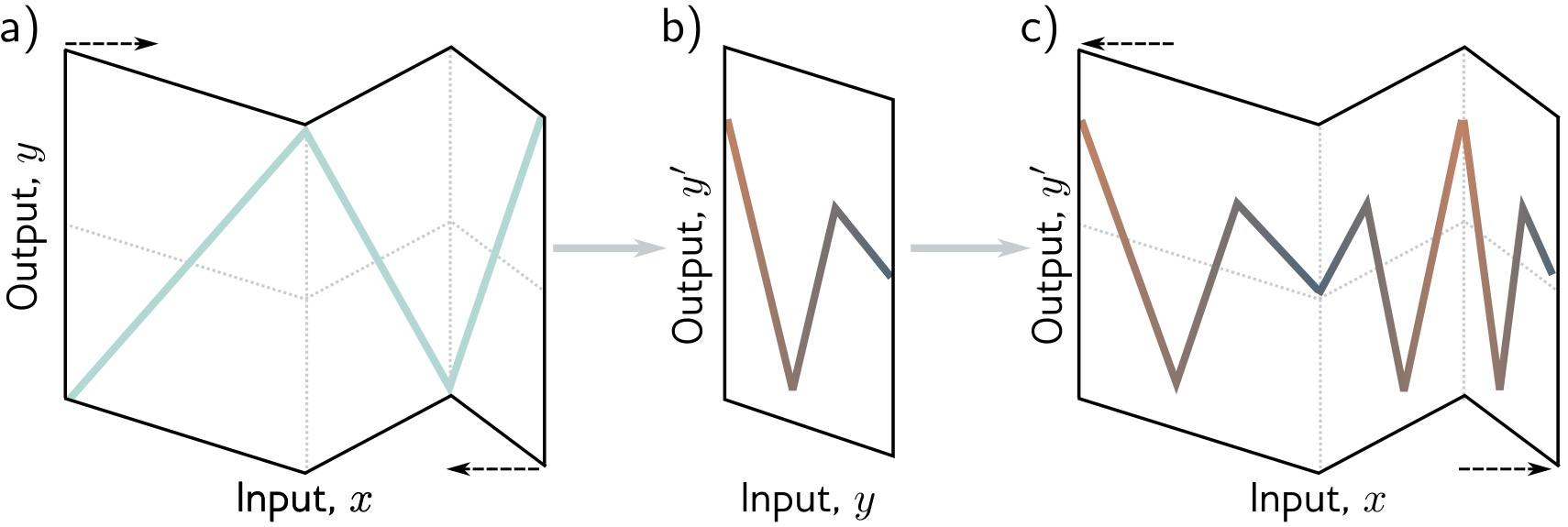
Layer 1:
Stretches, rotates, bends space with ReLU
Layer 2:
Further transforms the already-bent space
Result:
Complex folding of input space
→ Can separate classes that were originally intertwined
Two Hidden Layers
Adding depth: 2 hidden layers → more complex functions
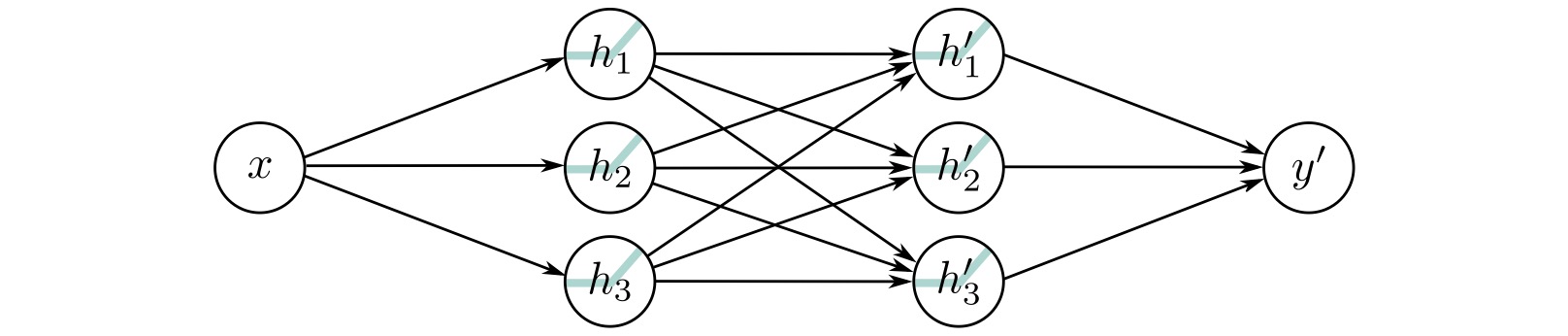
Key difference from shallow networks:
- First layer creates intermediate representations
- Second layer operates on those representations, not raw inputs
- Can capture compositional structure
Example: First layer detects edges, second layer combines edges into shapes
K Hidden Layers: Deep Architecture
Modern deep learning: Many layers stacked together
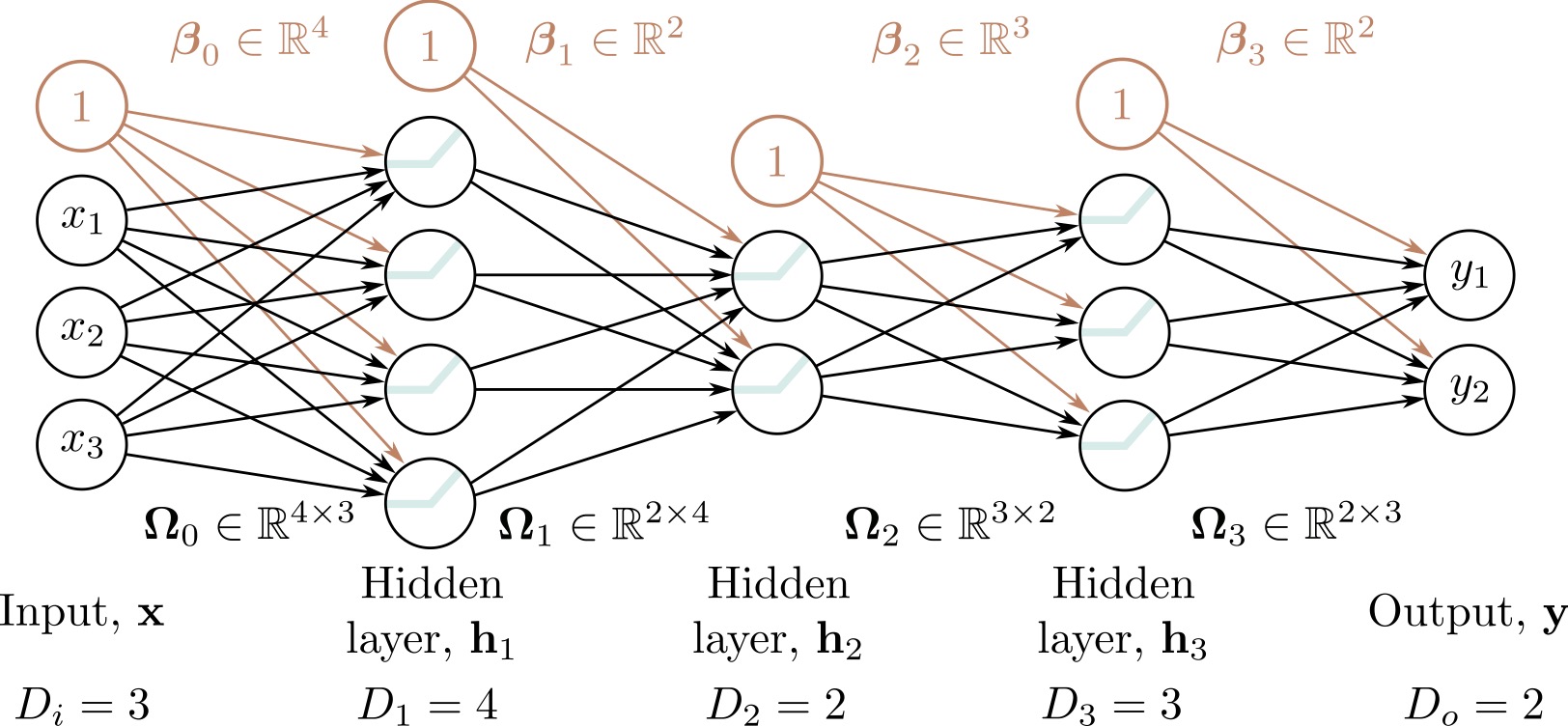
Deep Network Characteristics:
- Input layer: Raw features (e.g., pixel values)
- Hidden layer 1: Low-level features (edges, textures)
- Hidden layer 2: Mid-level features (parts, patterns)
- Hidden layer K: High-level features (concepts, objects)
- Output layer: Final prediction
Modern architectures: ResNet (152 layers), GPT-3 (96 layers), Vision Transformers (24+ layers)
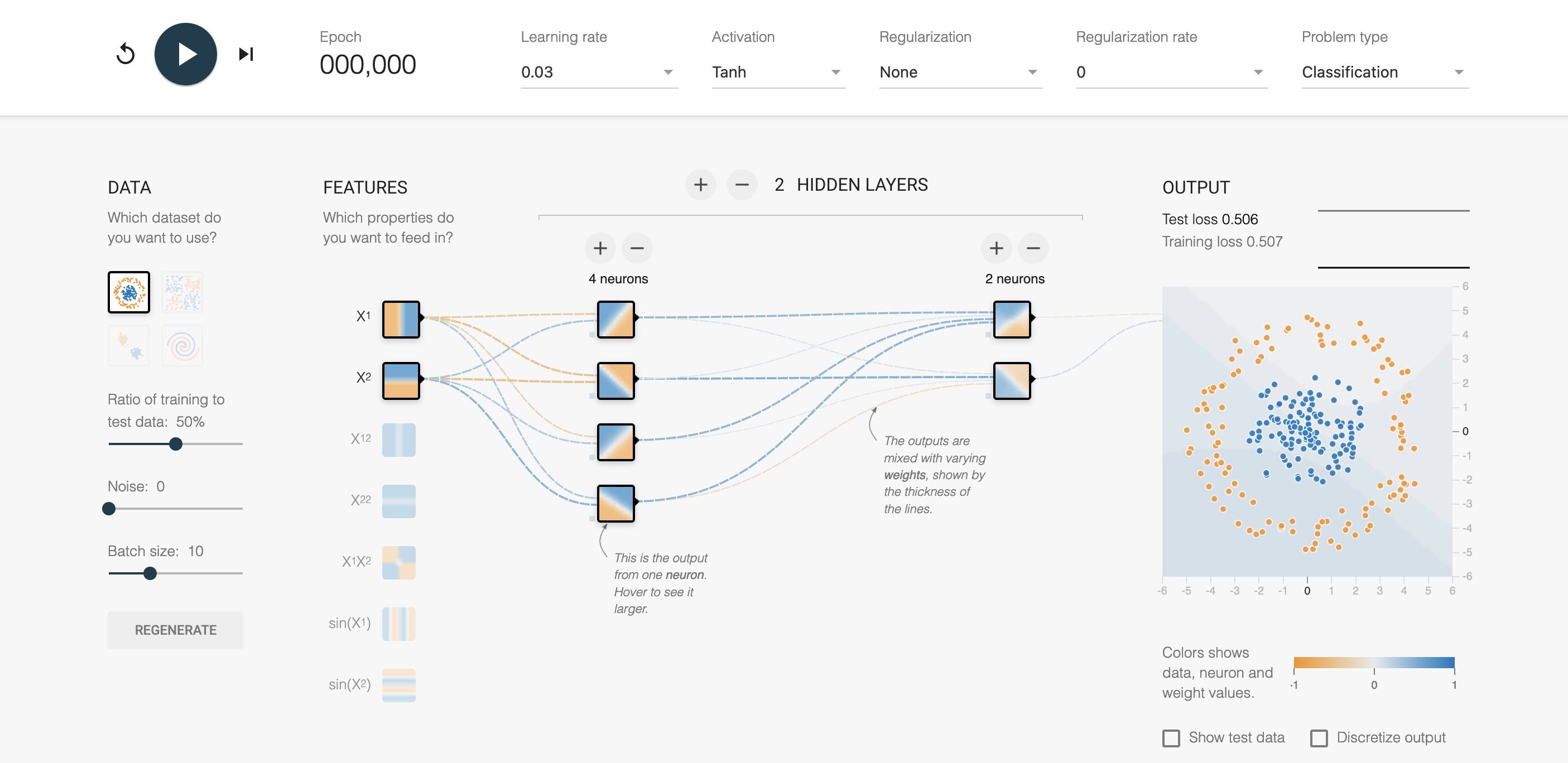
TensorFlow Playground
Interactive tool for understanding neural networks
https://playground.tensorflow.org
CNN Explainer
Interactive visualization for understanding Convolutional Neural Networks
https://poloclub.github.io/cnn-explainer/